Integrating Persian Lip Reading in Surena-V Humanoid Robot for Human-Robot Interaction
作者: Ali Farshian Abbasi, Aghil Yousefi-Koma, Soheil Dehghani Firouzabadi, Parisa Rashidi, Alireza Naeini
分类: cs.CV, cs.RO
发布日期: 2025-01-23
💡 一句话要点
将波斯语唇语识别集成到Surena-V机器人,提升人机交互能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 唇语识别 人机交互 人形机器人 深度学习 LSTM
📋 核心要点
- 现有语音识别技术在嘈杂环境中表现不佳,影响人机交互的可靠性,尤其是在类人机器人应用中。
- 本研究提出将波斯语唇语识别技术融入Surena-V机器人,通过视觉信息辅助语音识别,提升交互能力。
- 实验结果表明,基于LSTM的唇语识别模型准确率达到89%,成功实现了Surena-V机器人的实时人机交互。
📝 摘要(中文)
本研究旨在通过将波斯语唇语识别技术集成到Surena-V人形机器人中,提高其语音识别能力,从而改善社交环境中人机交互的质量。唇语识别对于机器人至关重要,尤其是在嘈杂环境中,能够提升其在护理和客户服务等场景下的沟通能力。该研究探索了两种互补的方法:一种是间接方法,利用面部landmark追踪;另一种是直接方法,利用卷积神经网络(CNN)和长短期记忆网络(LSTM)。间接方法侧重于追踪关键面部landmark,特别是嘴唇周围的landmark,以推断运动。直接方法处理原始视频数据,用于动作和语音识别。实验结果表明,LSTM模型表现最佳,准确率达到89%,并已成功应用于Surena-V机器人,实现了实时人机交互。该研究强调了这些方法在口头交流受限环境中的有效性。
🔬 方法详解
问题定义:论文旨在解决嘈杂环境下机器人语音识别准确率低的问题。传统的语音识别方法在背景噪声干扰严重时性能显著下降,影响了人机交互的流畅性和可靠性。因此,需要一种辅助手段来提高机器人在复杂环境下的理解能力。
核心思路:论文的核心思路是利用唇语识别作为语音识别的补充。通过分析说话人的唇部运动,提取视觉特征,从而在一定程度上弥补语音信息的缺失或干扰。这种多模态融合的方法可以提高机器人在嘈杂环境下的理解能力和交互质量。
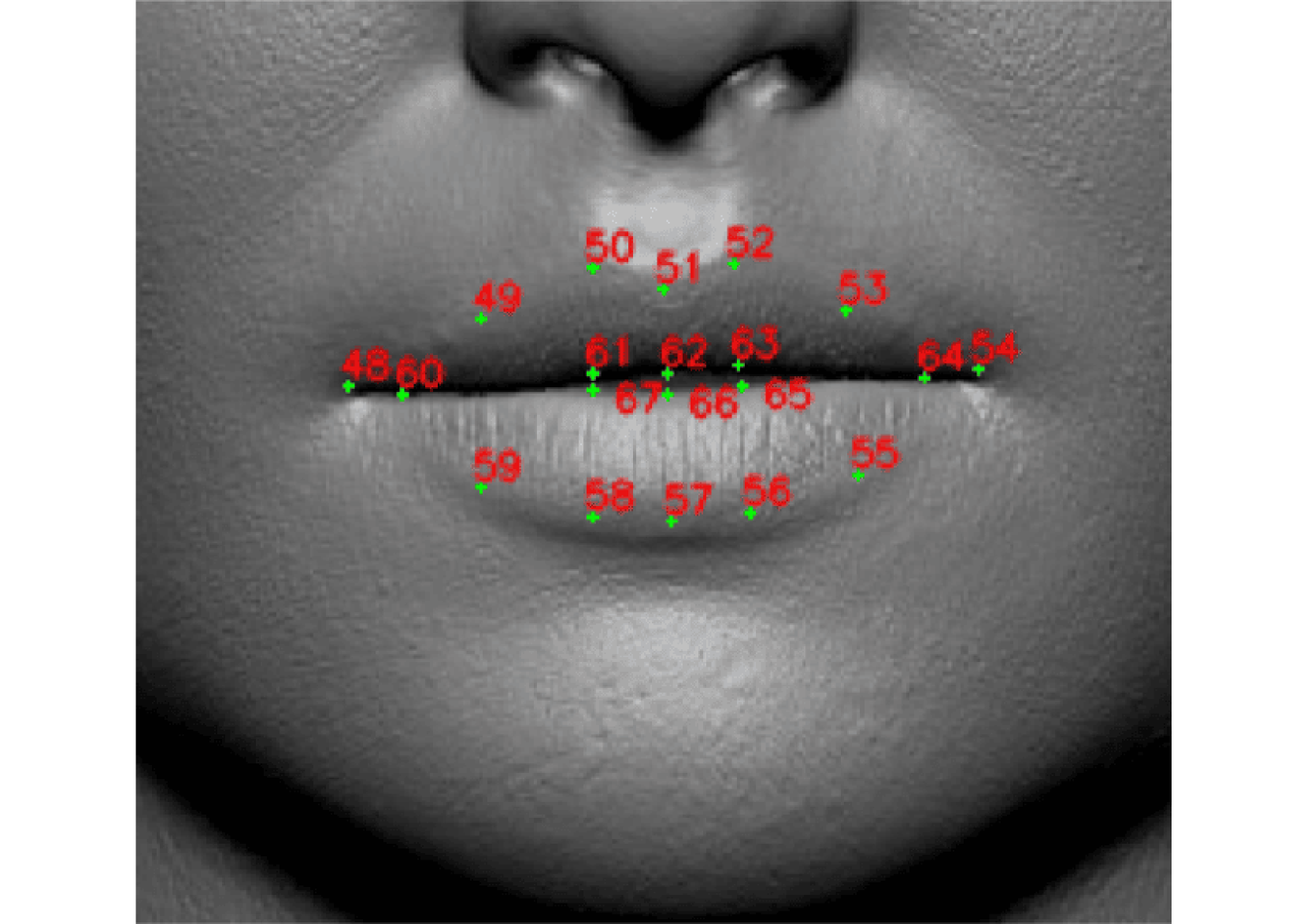
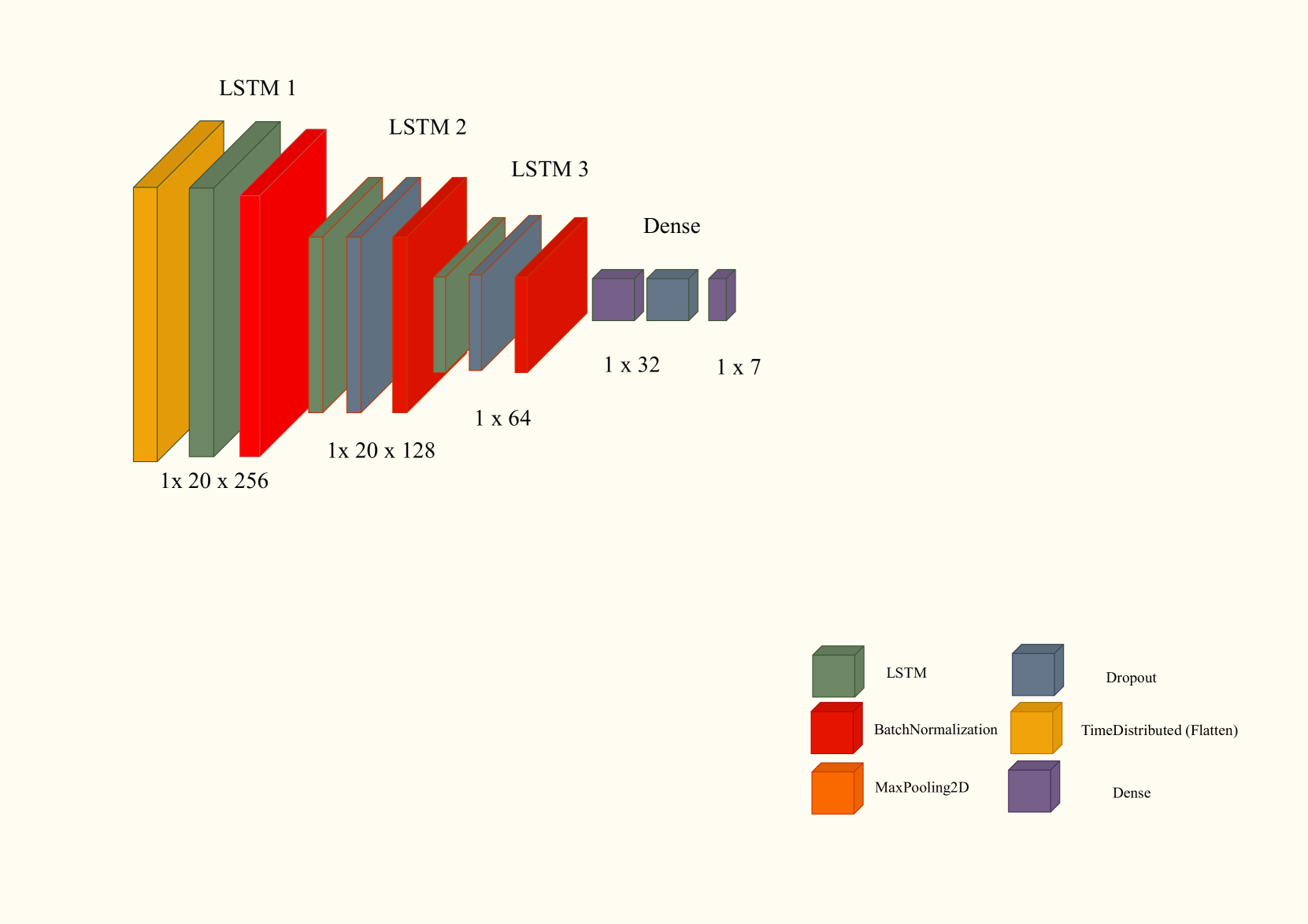
技术框架:整体框架包含数据采集、预处理、特征提取、模型训练和集成五个主要阶段。首先,构建波斯语唇语数据集。然后,采用两种方法进行特征提取:间接方法通过面部landmark追踪提取唇部运动特征;直接方法使用CNN和LSTM网络直接从视频数据中提取时空特征。最后,将训练好的唇语识别模型集成到Surena-V机器人中,实现实时人机交互。
关键创新:该研究的关键创新在于将波斯语唇语识别技术应用于人形机器人,并探索了两种互补的特征提取方法。间接方法利用landmark追踪,计算量小,易于实现;直接方法利用深度学习模型,能够自动学习更复杂的特征。两种方法的结合可以提高唇语识别的鲁棒性和准确性。
关键设计:在直接方法中,CNN用于提取视频帧的空间特征,LSTM用于捕捉唇部运动的时序信息。LSTM网络的具体结构和参数设置(如隐藏层大小、层数等)需要根据实验结果进行调整。损失函数通常采用交叉熵损失函数,优化算法可以选择Adam等。此外,数据集的规模和质量对模型的性能至关重要,需要进行数据增强和清洗。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于LSTM的唇语识别模型在波斯语数据集上取得了89%的准确率。该模型成功集成到Surena-V机器人中,实现了实时人机交互,验证了该方法在实际应用中的有效性。该研究为多模态人机交互提供了一种新的解决方案。
🎯 应用场景
该研究成果可应用于多种人机交互场景,如智能客服、医疗护理、教育培训等。在嘈杂环境中,唇语识别可以作为语音识别的补充,提高机器人理解人类指令的准确性。此外,该技术还可用于帮助听力障碍人士进行交流,具有广泛的社会价值和应用前景。
📄 摘要(原文)
Lip reading is vital for robots in social settings, improving their ability to understand human communication. This skill allows them to communicate more easily in crowded environments, especially in caregiving and customer service roles. Generating a Persian Lip-reading dataset, this study integrates Persian lip-reading technology into the Surena-V humanoid robot to improve its speech recognition capabilities. Two complementary methods are explored, an indirect method using facial landmark tracking and a direct method leveraging convolutional neural networks (CNNs) and long short-term memory (LSTM) networks. The indirect method focuses on tracking key facial landmarks, especially around the lips, to infer movements, while the direct method processes raw video data for action and speech recognition. The best-performing model, LSTM, achieved 89\% accuracy and has been successfully implemented into the Surena-V robot for real-time human-robot interaction. The study highlights the effectiveness of these methods, particularly in environments where verbal communication is limited.