Can We Generate Images with CoT? Let's Verify and Reinforce Image Generation Step by Step
作者: Ziyu Guo, Renrui Zhang, Chengzhuo Tong, Zhizheng Zhao, Rui Huang, Haoquan Zhang, Manyuan Zhang, Jiaming Liu, Shanghang Zhang, Peng Gao, Hongsheng Li, Pheng-Ann Heng
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-01-23 (更新: 2025-07-23)
备注: Journal Version. Code and models are released at https://github.com/ZiyuGuo99/Image-Generation-CoT
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于CoT的图像生成方法,通过验证和强化步骤显著提升自回归图像生成质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自回归图像生成 思维链 奖励模型 偏好优化 图像验证
📋 核心要点
- 现有自回归图像生成方法缺乏有效的验证和强化机制,难以生成高质量图像。
- 利用CoT推理,通过验证生成步骤并根据偏好进行强化,提升图像生成质量。
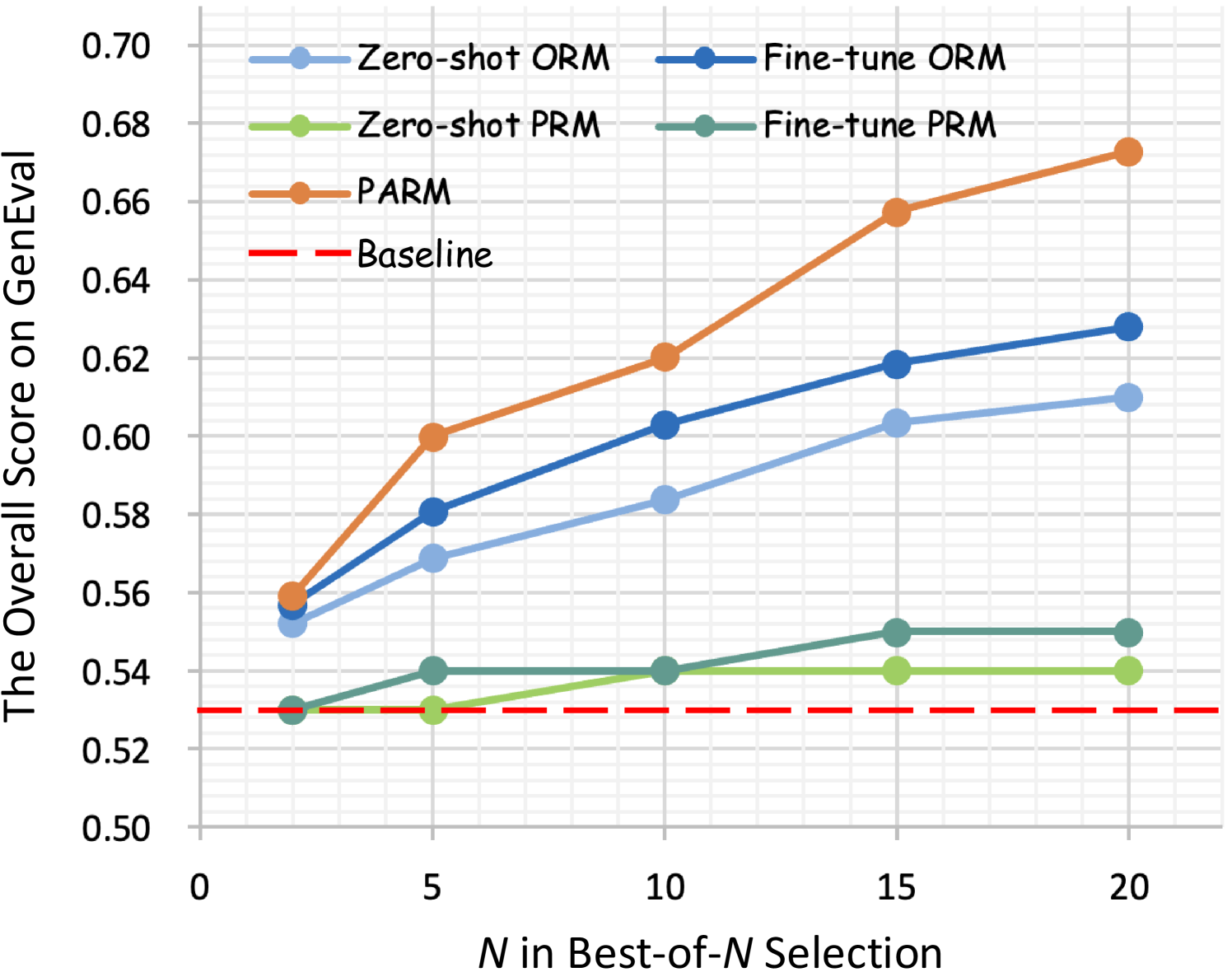
- 实验表明,该方法在GenEval上提升24%,超过Stable Diffusion 3 15%,效果显著。
📝 摘要(中文)
本文首次全面研究了思维链(CoT)推理在增强自回归图像生成方面的潜力。研究重点在于三种技术:扩展测试时计算以进行验证,通过直接偏好优化(DPO)对齐模型偏好,以及整合这些技术以产生互补效应。结果表明,这些方法可以有效地调整和组合,从而显著提高图像生成性能。此外,鉴于奖励模型在研究结果中的关键作用,提出了专门用于自回归图像生成的潜在评估奖励模型(PARM)和PARM++。PARM通过潜在评估方法自适应地评估每个生成步骤,融合了现有奖励模型的优势,而PARM++进一步引入了反射机制来自我纠正生成的不满意图像,这是首次将反射机制融入自回归图像生成中。通过所研究的推理策略,增强了基线模型Show-o,取得了优异的成果,在GenEval基准测试中取得了显著的+24%的提升,超过了Stable Diffusion 3 +15%。
🔬 方法详解
问题定义:论文旨在解决自回归图像生成中,模型难以生成高质量、符合人类偏好的图像的问题。现有方法缺乏有效的验证和强化机制,导致生成过程容易出错,且难以纠正。
核心思路:论文的核心思路是将Chain-of-Thought (CoT)推理引入自回归图像生成过程。通过逐步验证生成步骤,并利用奖励模型对生成结果进行强化,从而提高图像质量和与人类偏好的一致性。CoT推理允许模型在生成过程中进行自我评估和纠正,类似于人类的思考过程。
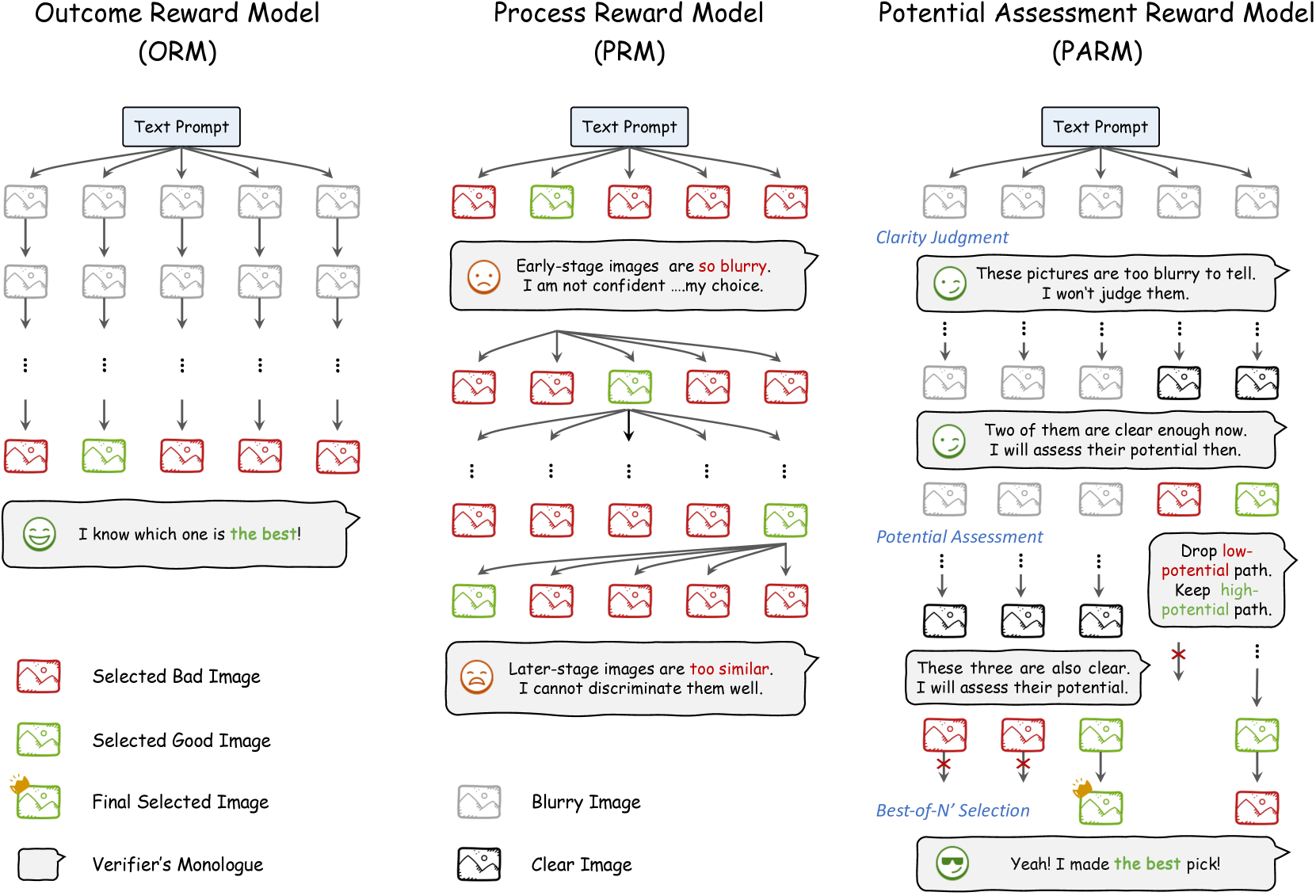
技术框架:整体框架包含三个主要部分:1) 基于CoT的验证:在测试时增加计算量,对每个生成步骤进行验证,确保其合理性;2) 基于DPO的偏好对齐:使用直接偏好优化(DPO)方法,将模型偏好与人类偏好对齐,引导模型生成更符合人类期望的图像;3) 潜在评估奖励模型(PARM/PARM++):设计专门用于自回归图像生成的奖励模型,用于评估生成过程中的每个步骤,并提供反馈信号。
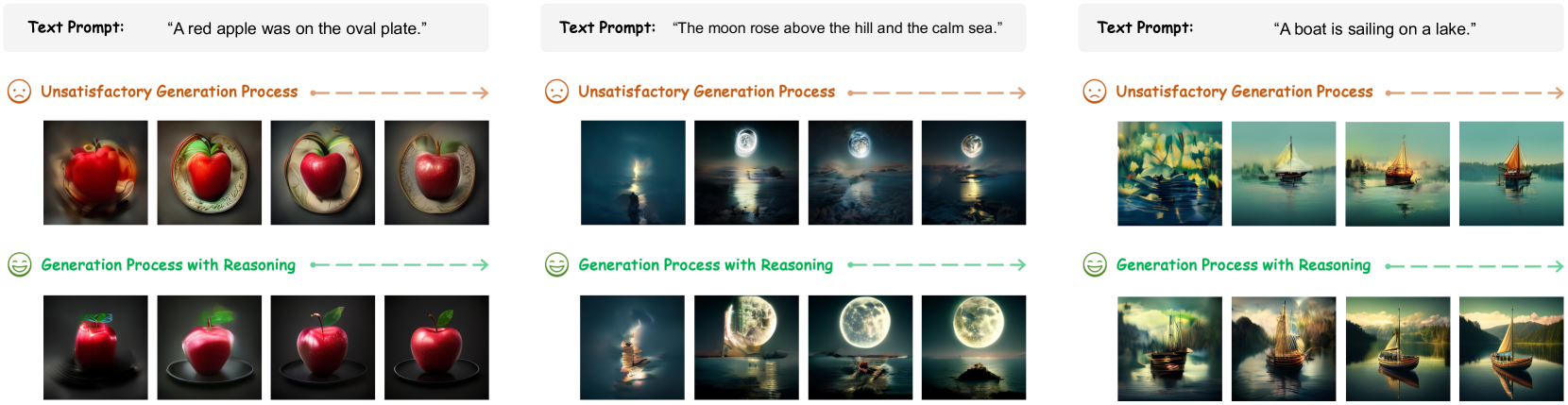
关键创新:论文的关键创新在于将CoT推理与自回归图像生成相结合,并提出了PARM和PARM++奖励模型。PARM通过潜在评估方法自适应地评估每个生成步骤,融合了现有奖励模型的优点。PARM++更进一步,引入了反射机制,使模型能够自我纠正生成的不满意图像,这是首次将反射机制应用于自回归图像生成。
关键设计:PARM的关键设计在于其潜在评估方法,该方法能够根据当前生成状态和历史生成步骤,预测未来生成结果的潜在质量,从而更准确地评估当前步骤的贡献。PARM++的反射机制则通过生成多个候选图像,并根据奖励模型的评估结果选择最优图像,从而实现自我纠正。DPO的损失函数用于优化生成模型,使其生成的图像更符合奖励模型的偏好。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在GenEval基准测试中取得了显著的+24%的提升,超过了Stable Diffusion 3 +15%。这表明基于CoT的图像生成方法能够显著提高图像质量和与人类偏好的一致性。PARM和PARM++奖励模型也表现出优异的性能,能够有效地评估和指导图像生成过程。
🎯 应用场景
该研究成果可应用于各种图像生成场景,例如艺术创作、内容生成、图像编辑等。通过提升图像生成质量和可控性,可以为用户提供更优质的图像生成服务,并推动相关领域的发展。未来,该方法有望应用于视频生成、3D模型生成等更复杂的生成任务。
📄 摘要(原文)
Chain-of-Thought (CoT) reasoning has been extensively explored in large models to tackle complex understanding tasks. However, it still remains an open question whether such strategies can be applied to verifying and reinforcing image generation scenarios. In this paper, we provide the first comprehensive investigation of the potential of CoT reasoning to enhance autoregressive image generation. We focus on three techniques: scaling test-time computation for verification, aligning model preferences with Direct Preference Optimization (DPO), and integrating these techniques for complementary effects. Our results demonstrate that these approaches can be effectively adapted and combined to significantly improve image generation performance. Furthermore, given the pivotal role of reward models in our findings, we propose the Potential Assessment Reward Model (PARM) and PARM++, specialized for autoregressive image generation. PARM adaptively assesses each generation step through a potential assessment approach, merging the strengths of existing reward models, and PARM++ further introduces a reflection mechanism to self-correct the generated unsatisfactory image, which is the first to incorporate reflection in autoregressive image generation. Using our investigated reasoning strategies, we enhance a baseline model, Show-o, to achieve superior results, with a significant +24% improvement on the GenEval benchmark, surpassing Stable Diffusion 3 by +15%. We hope our study provides unique insights and paves a new path for integrating CoT reasoning with autoregressive image generation. Code and models are released at https://github.com/ZiyuGuo99/Image-Generation-CoT