Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos
作者: Kairui Hu, Penghao Wu, Fanyi Pu, Wang Xiao, Yuanhan Zhang, Xiang Yue, Bo Li, Ziwei Liu
分类: cs.CV, cs.CL
发布日期: 2025-01-23
💡 一句话要点
提出Video-MMMU以评估多模态模型从专业视频中获取知识的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态模型 知识获取 视频学习 认知阶段 评估基准 教育技术 人工智能
📋 核心要点
- 现有视频基准未能系统评估大型多模态模型在知识获取方面的能力,存在明显的研究空白。
- 本文提出Video-MMMU基准,设计用于评估LMMs从多学科视频中获取和利用知识的能力,涵盖多个认知阶段。
- 实验结果显示,随着认知需求的增加,LMMs的性能显著下降,强调了提升其学习和适应能力的必要性。
📝 摘要(中文)
人类通过感知信息、理解知识和适应知识来解决新问题。视频作为有效的学习媒介,促进了这一认知过程。然而,现有视频基准未能系统评估大型多模态模型(LMMs)的知识获取能力。为此,本文提出Video-MMMU,一个多模态、多学科的基准,旨在评估LMMs从视频中获取和利用知识的能力。该基准包含300个专家级视频和900个人工标注问题,涵盖六个学科,通过与认知阶段对齐的问题-答案对进行评估。提出的知识增益指标Δknowledge量化了观看视频后的性能提升。评估结果显示,随着认知需求的增加,模型性能显著下降,揭示了人类与模型知识获取之间的显著差距,强调了提升LMMs从视频中学习和适应能力的方法的必要性。
🔬 方法详解
问题定义:现有方法缺乏对大型多模态模型在视频知识获取能力的系统评估,导致无法有效衡量其学习效果和适应能力。
核心思路:本文提出Video-MMMU基准,通过设计与认知阶段对齐的问题-答案对,系统评估LMMs在视频学习中的表现,旨在填补这一研究空白。
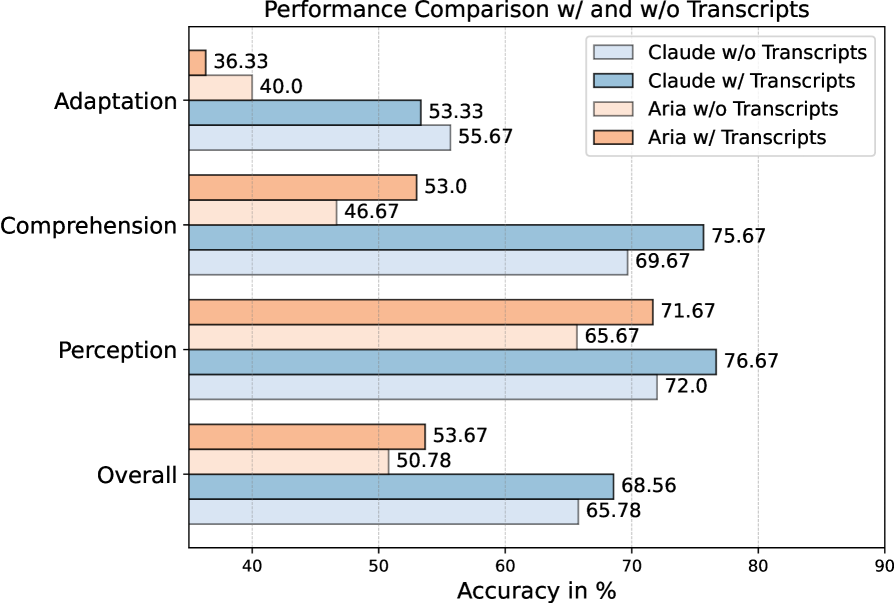
技术框架:Video-MMMU包含300个专家级视频和900个问题,分为感知、理解和适应三个认知阶段,评估模型在不同阶段的知识获取能力。
关键创新:提出的知识增益指标Δknowledge是本研究的核心创新,能够量化模型在观看视频后的性能提升,与现有方法相比,提供了更为细致的评估标准。
关键设计:在设计过程中,选择了多学科视频和人工标注问题,确保评估的全面性和专业性,同时在模型评估中引入了认知阶段的划分,以便更好地理解模型的学习过程。
🖼️ 关键图片


📊 实验亮点
实验结果表明,随着认知需求的增加,LMMs的性能显著下降,尤其在适应阶段,模型的表现较人类存在显著差距。通过引入Δknowledge指标,能够清晰量化模型在知识获取过程中的提升幅度,为未来的研究提供了重要参考。
🎯 应用场景
该研究的潜在应用领域包括教育技术、智能辅导系统和视频内容推荐等。通过提升LMMs从视频中获取和适应知识的能力,可以为用户提供更个性化和高效的学习体验,推动教育和培训行业的创新发展。
📄 摘要(原文)
Humans acquire knowledge through three cognitive stages: perceiving information, comprehending knowledge, and adapting knowledge to solve novel problems. Videos serve as an effective medium for this learning process, facilitating a progression through these cognitive stages. However, existing video benchmarks fail to systematically evaluate the knowledge acquisition capabilities in Large Multimodal Models (LMMs). To address this gap, we introduce Video-MMMU, a multi-modal, multi-disciplinary benchmark designed to assess LMMs' ability to acquire and utilize knowledge from videos. Video-MMMU features a curated collection of 300 expert-level videos and 900 human-annotated questions across six disciplines, evaluating knowledge acquisition through stage-aligned question-answer pairs: Perception, Comprehension, and Adaptation. A proposed knowledge gain metric, Δknowledge, quantifies improvement in performance after video viewing. Evaluation of LMMs reveals a steep decline in performance as cognitive demands increase and highlights a significant gap between human and model knowledge acquisition, underscoring the need for methods to enhance LMMs' capability to learn and adapt from videos.