PromptMono: Cross Prompting Attention for Self-Supervised Monocular Depth Estimation in Challenging Environments
作者: Changhao Wang, Guanwen Zhang, Zhengyun Cheng, Wei Zhou
分类: cs.CV
发布日期: 2025-01-23 (更新: 2025-03-28)
备注: 10 pages
💡 一句话要点
PromptMono:利用跨Prompting注意力提升复杂环境下单目深度估计
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 单目深度估计 自监督学习 视觉Prompt学习 跨Prompting注意力 复杂环境 领域自适应 深度学习 机器人视觉
📋 核心要点
- 现有单目深度估计方法在理想条件下表现良好,但在复杂环境中仍面临挑战。
- PromptMono利用视觉Prompt学习,通过可学习参数捕获领域知识,统一模型预测不同环境下的深度。
- 提出的门控跨Prompting注意力(GCPA)模块,有效融合Prompt信息,提升了深度估计的准确性。
📝 摘要(中文)
为了提升单目深度估计在复杂环境下的性能,本文提出了一种基于视觉Prompt学习的自监督学习框架PromptMono。该框架利用一组可学习的参数作为视觉Prompt,以捕获特定领域的知识。为了将Prompt信息融入图像表征,本文设计了一种新颖的门控跨Prompting注意力(GCPA)模块,从而增强了在各种条件下的深度估计能力。在Oxford Robotcar数据集和nuScenes数据集上的实验结果表明,本文提出的方法具有优越的性能。
🔬 方法详解
问题定义:论文旨在解决单目深度估计在复杂和多变环境下的性能瓶颈。现有方法在理想环境下表现良好,但在光照变化、天气条件恶劣等情况下,深度估计的准确性显著下降。现有的单目深度估计方法难以泛化到不同的环境,需要针对特定环境进行调整或重新训练,缺乏通用性和鲁棒性。
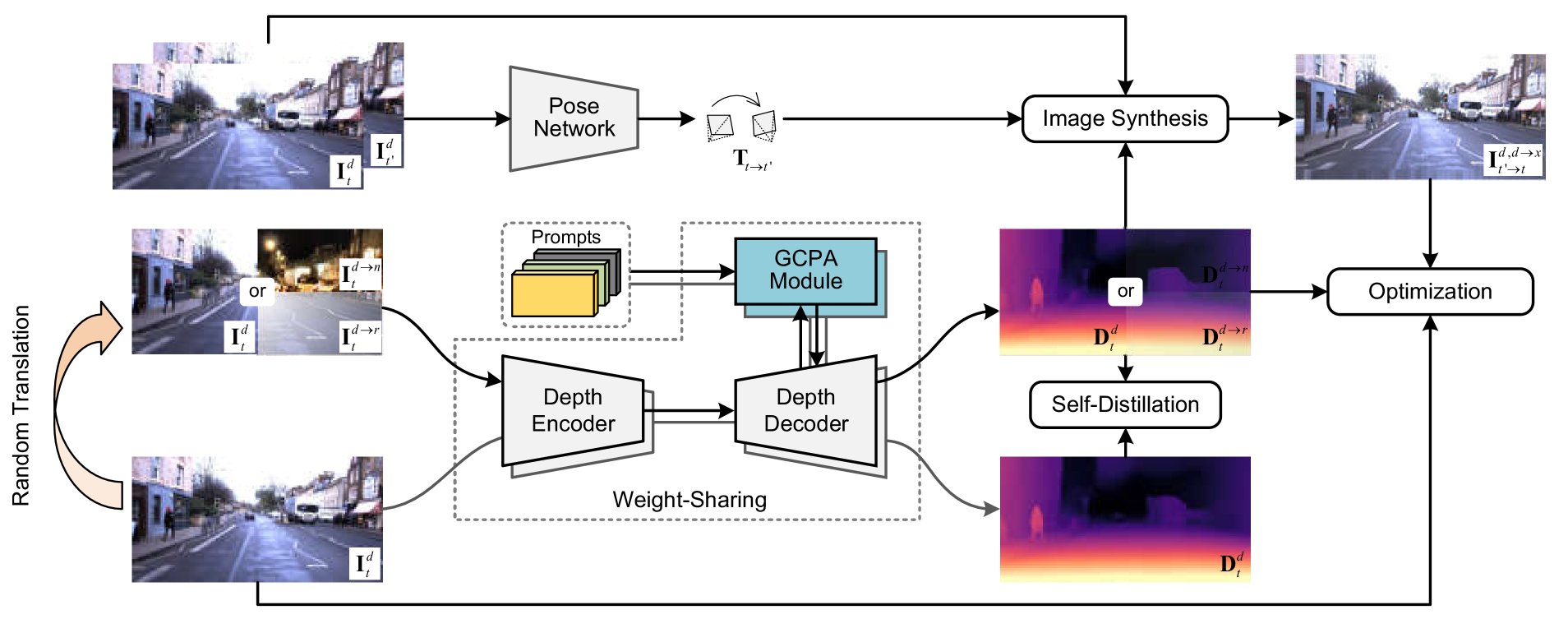
核心思路:论文的核心思路是利用视觉Prompt学习,通过引入一组可学习的参数(即视觉Prompt)来捕获特定领域的知识。这些Prompt可以理解为对不同环境特征的编码,通过将Prompt信息融入到图像表征中,模型能够更好地适应不同的环境,从而提高深度估计的准确性和泛化能力。
技术框架:PromptMono的整体框架包含以下几个主要模块:1) 图像输入:输入待估计深度的单目图像。2) 特征提取:使用卷积神经网络提取图像的特征表示。3) Prompt生成:一组可学习的参数作为视觉Prompt,用于捕获特定领域的知识。4) 门控跨Prompting注意力(GCPA)模块:将Prompt信息融入到图像特征表示中,增强模型对不同环境的适应性。5) 深度预测:利用解码器将融合了Prompt信息的特征表示解码为深度图。6) 自监督学习:使用光度一致性损失等自监督损失函数训练模型。
关键创新:论文的关键创新在于提出了门控跨Prompting注意力(GCPA)模块。GCPA模块能够有效地将Prompt信息融入到图像特征表示中,从而增强模型对不同环境的适应性。与传统的注意力机制不同,GCPA模块通过门控机制来控制Prompt信息的融合程度,避免了Prompt信息对原始图像特征的过度干扰。
关键设计:GCPA模块的设计是关键。具体来说,GCPA模块首先计算Prompt与图像特征之间的注意力权重,然后利用门控机制对注意力权重进行调整,最后将调整后的注意力权重应用于Prompt信息,得到融合了Prompt信息的图像特征表示。自监督学习方面,论文采用光度一致性损失作为主要的损失函数,同时可能结合其他辅助损失函数,如平滑损失等,以提高深度估计的准确性和鲁棒性。具体的网络结构和参数设置在论文中有详细描述,但此处未知。
🖼️ 关键图片


📊 实验亮点
PromptMono在Oxford Robotcar数据集和nuScenes数据集上进行了评估,实验结果表明,PromptMono在深度估计精度方面优于现有的自监督单目深度估计方法。具体的性能提升数据未知,但摘要中明确指出该方法具有“superior performance”。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、机器人导航、增强现实等领域。在自动驾驶中,准确的深度估计是感知周围环境的关键。PromptMono能够提高在各种复杂环境下的深度估计精度,从而提升自动驾驶系统的安全性和可靠性。在机器人导航中,PromptMono可以帮助机器人更好地理解周围环境,实现自主导航。在增强现实中,PromptMono可以提供更准确的深度信息,从而实现更逼真的增强现实效果。
📄 摘要(原文)
Considerable efforts have been made to improve monocular depth estimation under ideal conditions. However, in challenging environments, monocular depth estimation still faces difficulties. In this paper, we introduce visual prompt learning for predicting depth across different environments within a unified model, and present a self-supervised learning framework called PromptMono. It employs a set of learnable parameters as visual prompts to capture domain-specific knowledge. To integrate prompting information into image representations, a novel gated cross prompting attention (GCPA) module is proposed, which enhances the depth estimation in diverse conditions. We evaluate the proposed PromptMono on the Oxford Robotcar dataset and the nuScenes dataset. Experimental results demonstrate the superior performance of the proposed method.