EventVL: Understand Event Streams via Multimodal Large Language Model
作者: Pengteng Li, Yunfan Lu, Pinghao Song, Wuyang Li, Huizai Yao, Hui Xiong
分类: cs.CV, cs.AI
发布日期: 2025-01-23 (更新: 2025-09-23)
💡 一句话要点
提出EventVL,首个生成式事件相机多模态大语言模型,用于显式语义理解。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事件相机 多模态学习 大语言模型 事件描述 场景理解
📋 核心要点
- 现有事件视觉-语言模型侧重传统感知任务,缺乏对事件流语义和上下文的充分理解。
- EventVL通过构建大型多模态数据集,并设计事件时空表示和动态语义对齐,实现显式语义理解。
- 实验表明,EventVL在事件描述和场景描述生成任务中显著优于现有MLLM基线。
📝 摘要(中文)
本文提出了EventVL,首个用于显式语义理解的生成式事件相机多模态大语言模型(MLLM)框架。现有基于事件的视觉-语言模型(VLM)主要使用CLIP,侧重于传统感知任务,无法充分理解事件流中的语义和上下文。为了弥补这一缺陷,我们首先标注了一个大型事件-图像/视频-文本数据集,包含近140万个高质量数据对,从而能够有效地学习各种场景,例如驾驶场景或人体运动。 之后,我们设计了事件时空表示,通过多样化地聚合和分割事件流来充分探索综合信息。 为了进一步促进紧凑的语义空间,引入了动态语义对齐来改进和完善事件的稀疏语义空间。 大量实验表明,我们的EventVL可以显著超越现有的MLLM基线,在事件描述和场景描述生成任务中表现出色。 我们希望我们的研究能够为事件视觉社区的发展做出贡献。
🔬 方法详解
问题定义:现有基于事件的视觉-语言模型(VLM)主要依赖CLIP等模型,专注于传统的感知任务,例如目标检测和分类。这些方法无法充分利用事件流中蕴含的丰富语义信息和上下文关系,导致模型对事件的理解不够深入和全面。因此,如何让模型能够显式地理解事件流的语义信息,成为了一个亟待解决的问题。
核心思路:EventVL的核心思路是构建一个生成式的多模态大语言模型,通过联合学习事件数据、图像/视频数据和文本数据,使模型能够理解事件流的语义信息,并生成相应的文本描述。这种方法借鉴了近年来在大规模语言模型上的成功经验,将事件视觉任务转化为一个文本生成任务,从而能够更好地利用语言模型的强大能力。
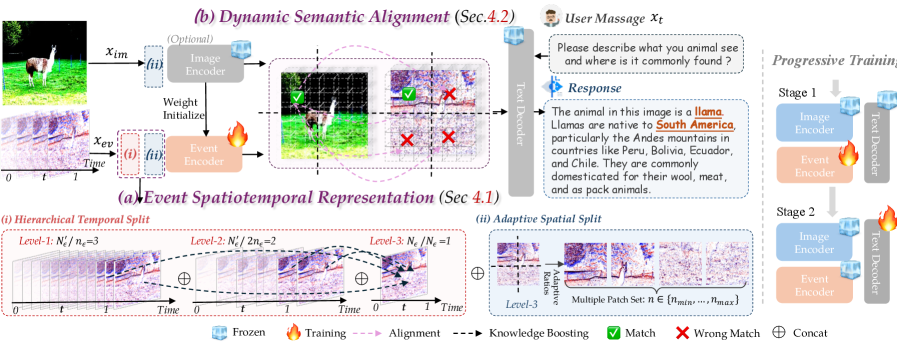
技术框架:EventVL的整体框架包含以下几个主要模块:1) 事件时空表示模块:该模块负责将事件流转换为一种紧凑的表示形式,以便后续模块能够更好地处理。该模块通过多样化地聚合和分割事件流,从而充分探索综合信息。2) 多模态编码器:该模块负责将事件表示、图像/视频数据和文本数据编码为统一的语义空间中的向量表示。3) 动态语义对齐模块:该模块负责对齐不同模态之间的语义信息,从而提高模型的理解能力。该模块通过改进和完善事件的稀疏语义空间,从而促进紧凑的语义空间。4) 文本解码器:该模块负责根据编码后的语义向量生成相应的文本描述。
关键创新:EventVL的关键创新在于以下几个方面:1) 首个生成式事件相机多模态大语言模型:EventVL是首个将生成式大语言模型应用于事件相机数据的研究,为事件视觉领域的研究开辟了新的方向。2) 大型多模态数据集:为了训练EventVL,作者标注了一个包含近140万个高质量数据对的大型事件-图像/视频-文本数据集,为模型的训练提供了充足的数据支持。3) 事件时空表示和动态语义对齐:作者设计了事件时空表示和动态语义对齐模块,从而能够更好地利用事件流中的语义信息,并提高模型的理解能力。
关键设计:EventVL的关键设计包括:1) 事件时空表示:具体实现方式未知,但强调了多样化聚合和分割事件流的重要性。2) 动态语义对齐:具体实现方式未知,但目标是改进和完善事件的稀疏语义空间。3) 损失函数:损失函数的具体形式未知,但可以推测其目标是使模型生成的文本描述与真实文本描述尽可能地接近。
🖼️ 关键图片

📊 实验亮点
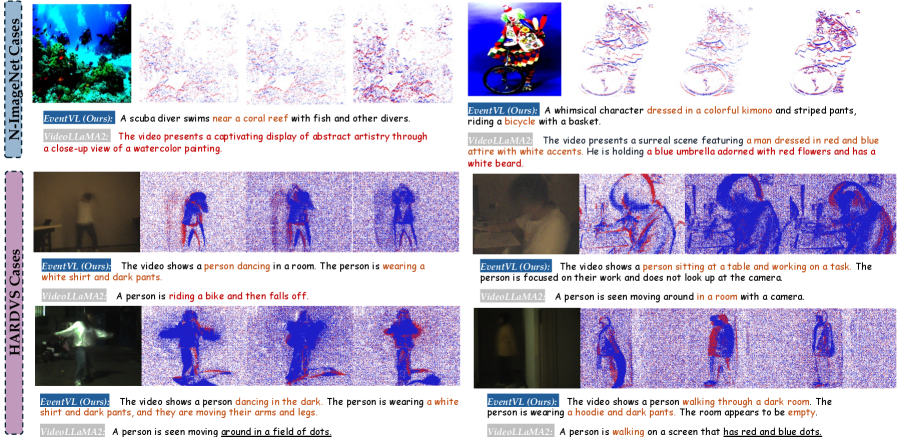
EventVL在事件描述和场景描述生成任务中取得了显著的性能提升,超越了现有的MLLM基线。具体的性能数据和提升幅度在论文中有所体现,但摘要中未明确给出。该结果表明,EventVL能够有效地理解事件流中的语义信息,并生成高质量的文本描述。
🎯 应用场景
EventVL在自动驾驶、机器人导航、监控等领域具有广泛的应用前景。例如,在自动驾驶中,EventVL可以用于理解车辆周围的交通状况,并生成相应的驾驶指令。在机器人导航中,EventVL可以用于理解环境信息,并规划出最佳的导航路径。在监控领域,EventVL可以用于检测异常事件,并及时发出警报。该研究的突破将推动事件视觉技术的发展,并为相关应用带来更智能、更高效的解决方案。
📄 摘要(原文)
The event-based Vision-Language Model (VLM) recently has made good progress for practical vision tasks. However, most of these works just utilize CLIP for focusing on traditional perception tasks, which obstruct model understanding explicitly the sufficient semantics and context from event streams. To address the deficiency, we propose EventVL, the first generative event-based MLLM (Multimodal Large Language Model) framework for explicit semantic understanding. Specifically, to bridge the data gap for connecting different modalities semantics, we first annotate a large event-image/video-text dataset, containing almost 1.4 million high-quality pairs of data, which enables effective learning across various scenes, e.g., drive scene or human motion. After that, we design Event Spatiotemporal Representation to fully explore the comprehensive information by diversely aggregating and segmenting the event stream. To further promote a compact semantic space, Dynamic Semantic Alignment is introduced to improve and complete sparse semantic spaces of events. Extensive experiments show that our EventVL can significantly surpass existing MLLM baselines in event captioning and scene description generation tasks. We hope our research could contribute to the development of the event vision community.