EchoVideo: Identity-Preserving Human Video Generation by Multimodal Feature Fusion
作者: Jiangchuan Wei, Shiyue Yan, Wenfeng Lin, Boyuan Liu, Renjie Chen, Mingyu Guo
分类: cs.CV
发布日期: 2025-01-23 (更新: 2025-02-27)
💡 一句话要点
EchoVideo:通过多模态特征融合实现身份保持的人类视频生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频生成 身份保持 多模态融合 图像-文本融合 深度学习 人脸生成 视频编辑 对抗生成网络
📋 核心要点
- 现有身份保持视频生成方法依赖低层人脸信息,易产生“复制粘贴”伪影和相似度低的问题。
- EchoVideo通过身份图像-文本融合模块(IITF)提取高级语义特征,并采用两阶段训练策略,提升身份保持能力。
- 实验表明,EchoVideo在生成高质量、可控性和高保真度视频方面表现出色,有效保留面部身份。
📝 摘要(中文)
视频生成领域的最新进展对各种下游应用产生了重大影响,尤其是在身份保持的视频生成(IPT2V)方面。然而,现有方法在“复制粘贴”伪影和低相似度问题上表现不佳,这主要是由于它们依赖于低层次的面部图像信息。这种依赖会导致僵硬的面部外观和反映不相关细节的伪影。为了解决这些挑战,我们提出了EchoVideo,它采用了两个关键策略:(1)身份图像-文本融合模块(IITF),它集成了来自文本的高级语义特征,捕获干净的面部身份表示,同时丢弃遮挡、姿势和光照变化,以避免引入伪影;(2)一个两阶段训练策略,在第二阶段结合了一种随机方法来随机利用浅层面部信息。目标是平衡浅层特征提供的保真度增强,同时减轻对它们的过度依赖。这种策略鼓励模型在训练期间利用高级特征,最终培养更强大的面部身份表示。EchoVideo有效地保留了面部身份并保持了全身的完整性。广泛的实验表明,它在生成高质量、可控性和高保真度的视频方面取得了优异的成果。
🔬 方法详解
问题定义:现有身份保持视频生成方法过度依赖低层次的面部图像信息,导致生成视频中出现“复制粘贴”伪影,并且生成的人脸与目标身份的相似度较低。这些方法难以有效去除遮挡、姿势和光照变化等干扰因素,使得生成结果不够鲁棒。
核心思路:EchoVideo的核心思路是利用文本信息中蕴含的高级语义特征来指导视频生成,从而避免直接依赖低层次的面部图像信息。通过融合图像和文本特征,模型可以学习到更干净、更鲁棒的面部身份表示,从而提高生成视频的质量和身份保持能力。同时,采用两阶段训练策略,平衡浅层特征和高级特征的使用,避免过度依赖浅层特征。
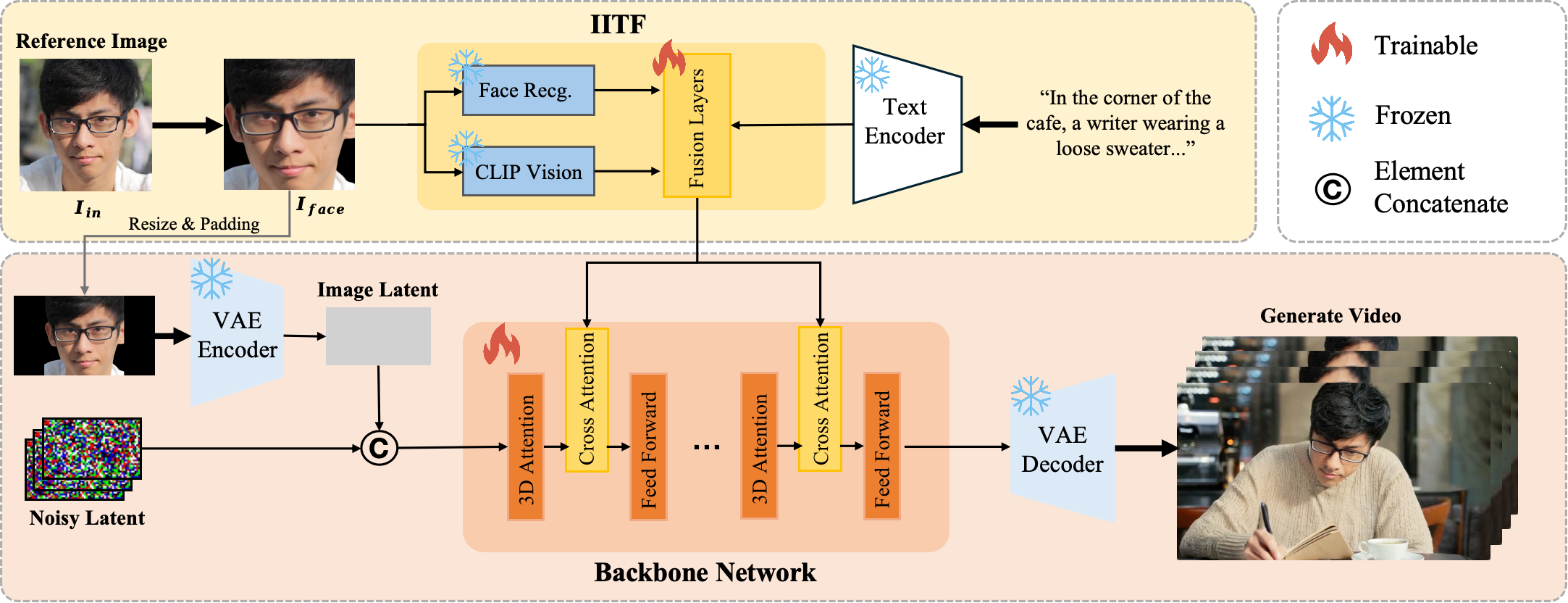
技术框架:EchoVideo包含两个主要模块:身份图像-文本融合模块(IITF)和两阶段训练策略。IITF模块负责将输入的身份图像和文本描述融合,提取高级语义特征。两阶段训练策略首先使用全部特征进行训练,然后在第二阶段随机使用浅层面部信息,以鼓励模型更多地依赖高级特征。整体流程是:输入身份图像和文本描述,通过IITF提取特征,然后输入到视频生成模型中,生成目标视频。
关键创新:EchoVideo的关键创新在于IITF模块和两阶段训练策略。IITF模块通过融合图像和文本信息,有效地提取了高级语义特征,避免了直接使用低层次图像信息带来的问题。两阶段训练策略则平衡了浅层特征和高级特征的使用,使得模型能够更好地学习到鲁棒的面部身份表示。与现有方法相比,EchoVideo更注重利用高级语义信息,从而提高了生成视频的质量和身份保持能力。
关键设计:IITF模块的具体实现细节未知,但可以推测其可能采用了注意力机制或者其他特征融合方法。两阶段训练策略中,第二阶段随机使用浅层面部信息的概率是一个关键参数,需要根据具体实验进行调整。损失函数的设计也至关重要,可能包括身份损失、内容损失和对抗损失等,以保证生成视频的质量和身份保持能力。具体的网络结构未知。
🖼️ 关键图片


📊 实验亮点
论文通过大量实验验证了EchoVideo的有效性,表明其在生成高质量、可控性和高保真度视频方面取得了优异的成果。具体的性能数据和对比基线未知,但摘要强调了EchoVideo在身份保持和全身完整性方面的优势。实验结果表明,EchoVideo能够有效地保留面部身份,并生成逼真的全身视频。
🎯 应用场景
EchoVideo技术可应用于虚拟形象生成、电影特效制作、社交媒体内容创作等领域。该技术能够生成高质量、身份保持的视频,为用户提供更逼真、更个性化的视觉体验。未来,该技术有望在元宇宙、数字人等新兴领域发挥重要作用。
📄 摘要(原文)
Recent advancements in video generation have significantly impacted various downstream applications, particularly in identity-preserving video generation (IPT2V). However, existing methods struggle with "copy-paste" artifacts and low similarity issues, primarily due to their reliance on low-level facial image information. This dependence can result in rigid facial appearances and artifacts reflecting irrelevant details. To address these challenges, we propose EchoVideo, which employs two key strategies: (1) an Identity Image-Text Fusion Module (IITF) that integrates high-level semantic features from text, capturing clean facial identity representations while discarding occlusions, poses, and lighting variations to avoid the introduction of artifacts; (2) a two-stage training strategy, incorporating a stochastic method in the second phase to randomly utilize shallow facial information. The objective is to balance the enhancements in fidelity provided by shallow features while mitigating excessive reliance on them. This strategy encourages the model to utilize high-level features during training, ultimately fostering a more robust representation of facial identities. EchoVideo effectively preserves facial identities and maintains full-body integrity. Extensive experiments demonstrate that it achieves excellent results in generating high-quality, controllability and fidelity videos.