Contrast: A Hybrid Architecture of Transformers and State Space Models for Low-Level Vision
作者: Aman Urumbekov, Zheng Chen
分类: cs.CV
发布日期: 2025-01-23 (更新: 2025-03-09)
备注: 10 pages, 6 figures
💡 一句话要点
提出Contrast混合架构,融合Transformer与状态空间模型,提升图像超分辨率性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 图像超分辨率 Transformer 状态空间模型 Mamba 混合架构
📋 核心要点
- Transformer在超分辨率任务中计算复杂度高,感受野受限,难以有效建模全局上下文。
- Contrast融合卷积、Transformer和状态空间模型,结合Transformer和Mamba的优势,弥补各自的不足。
- 实验结果表明,Contrast在图像超分辨率任务上表现更优,验证了混合架构的有效性。
📝 摘要(中文)
Transformer在图像超分辨率(SR)任务中因其强大的全局上下文建模能力而日益普及。然而,其二次计算复杂度迫使其采用基于窗口的注意力机制,限制了感受野并限制了有效的上下文扩展。最近,Mamba架构作为一种有前景的替代方案出现,它具有线性计算复杂度,使其能够避免窗口机制并保持较大的感受野。然而,当需要高像素级精度时,Mamba在处理长上下文依赖关系方面面临挑战,例如在SR任务中。这是由于其隐藏状态机制,该机制可以压缩和存储大量上下文,但只能以近似的方式进行,从而导致Transformer不会遇到的不准确性。在本文中,我们提出了 extbf{Contrast},一种混合SR模型,它结合了 extbf{Con}volutional、 extbf{Tra}nsformer和 extbf{St}ate Space组件,有效地融合了Transformer和Mamba的优势,以解决它们各自的局限性。通过集成Transformer和状态空间机制, extbf{Contrast}弥补了每种方法的缺点,增强了全局上下文建模和像素级精度。我们证明,结合这两种架构可以减轻每种架构固有的问题,从而提高图像超分辨率任务的性能。
🔬 方法详解
问题定义:图像超分辨率任务需要精确的像素级重建,现有方法如Transformer虽然擅长全局上下文建模,但计算复杂度高,感受野受限。Mamba虽然计算复杂度低,感受野大,但在处理需要高像素级精度的长上下文依赖时,由于其隐藏状态的近似压缩,会引入不准确性。
核心思路:Contrast的核心思路是结合Transformer和Mamba的优势,弥补彼此的不足。Transformer擅长精确的上下文建模,但计算成本高;Mamba计算效率高,但精度稍逊。通过混合架构,Contrast旨在实现高精度和高效率的平衡。
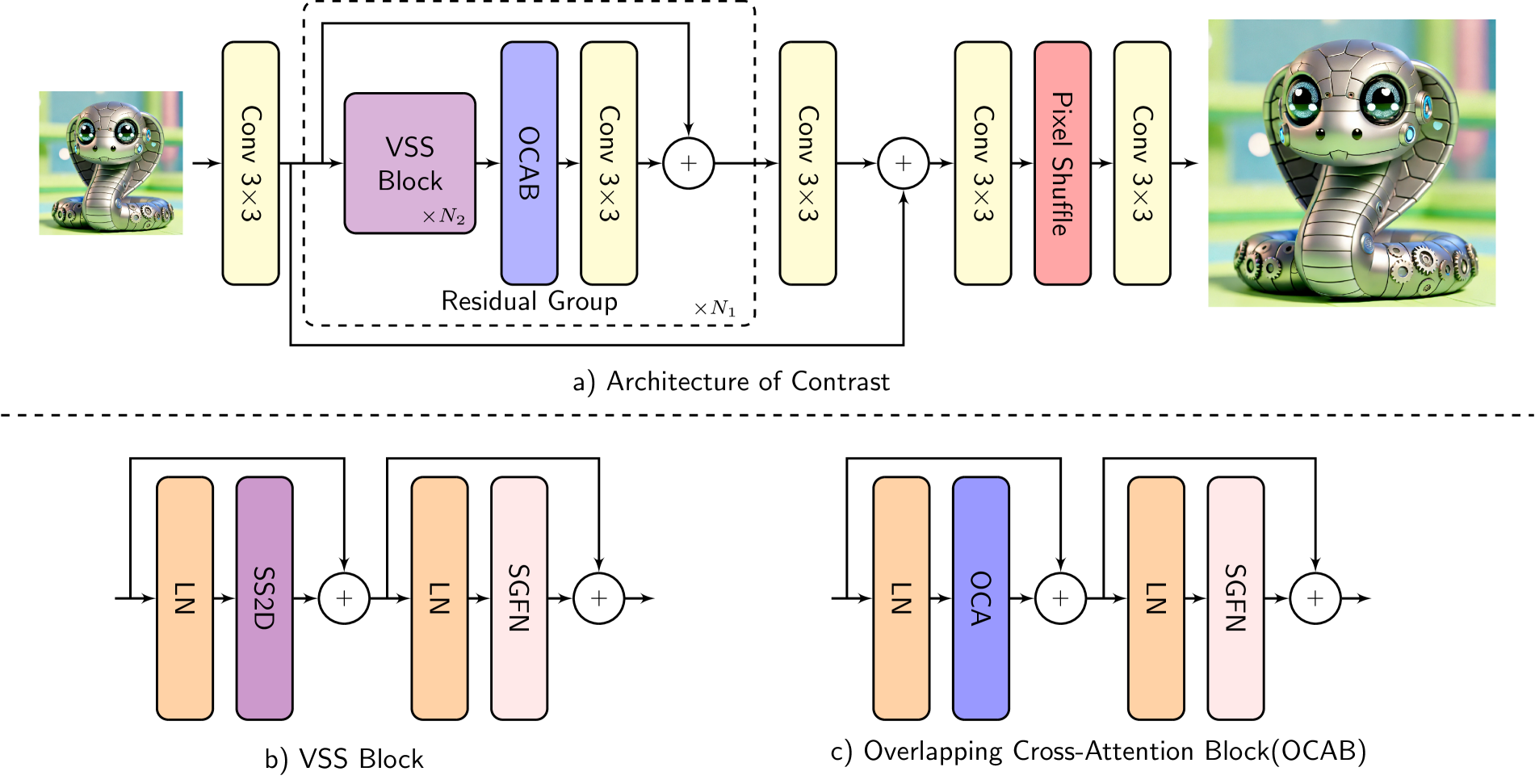
技术框架:Contrast是一个混合的超分辨率模型,包含卷积层、Transformer模块和状态空间模型(Mamba)模块。整体架构可能包含以下阶段:1. 浅层特征提取(卷积层);2. 多层混合模块(交替或并行使用Transformer和Mamba);3. 特征融合;4. 图像重建(上采样和卷积层)。具体流程取决于论文的具体实现细节。
关键创新:Contrast的关键创新在于混合架构的设计,它并非简单地堆叠Transformer和Mamba,而是通过某种方式将它们集成在一起,以实现优势互补。这种混合方式允许模型在保持全局上下文建模能力的同时,提高像素级精度。与纯Transformer或纯Mamba架构相比,Contrast在性能和效率之间取得了更好的平衡。
关键设计:具体的网络结构、Transformer和Mamba模块的配置、以及它们之间的连接方式是关键的设计细节。损失函数可能包括像素级的L1或L2损失,以及感知损失或对抗损失,以提高重建图像的视觉质量。论文中可能还包含关于训练策略、数据增强等方面的细节。
🖼️ 关键图片


📊 实验亮点
论文提出的Contrast模型在图像超分辨率任务上取得了显著的性能提升。具体的数据和对比基线需要在论文中查找,但可以预期的是,Contrast在PSNR、SSIM等指标上优于传统的Transformer和Mamba模型,尤其是在高放大倍数下,优势可能更加明显。
🎯 应用场景
Contrast模型在图像超分辨率领域具有广泛的应用前景,可用于提升监控视频、卫星图像、医学影像等的分辨率,从而改善图像质量,辅助分析决策。该研究对其他低级视觉任务,如图像去噪、图像修复等,也具有一定的借鉴意义。
📄 摘要(原文)
Transformers have become increasingly popular for image super-resolution (SR) tasks due to their strong global context modeling capabilities. However, their quadratic computational complexity necessitates the use of window-based attention mechanisms, which restricts the receptive field and limits effective context expansion. Recently, the Mamba architecture has emerged as a promising alternative with linear computational complexity, allowing it to avoid window mechanisms and maintain a large receptive field. Nevertheless, Mamba faces challenges in handling long-context dependencies when high pixel-level precision is required, as in SR tasks. This is due to its hidden state mechanism, which can compress and store a substantial amount of context but only in an approximate manner, leading to inaccuracies that transformers do not suffer from. In this paper, we propose \textbf{Contrast}, a hybrid SR model that combines \textbf{Con}volutional, \textbf{Tra}nsformer, and \textbf{St}ate Space components, effectively blending the strengths of transformers and Mamba to address their individual limitations. By integrating transformer and state space mechanisms, \textbf{Contrast} compensates for the shortcomings of each approach, enhancing both global context modeling and pixel-level accuracy. We demonstrate that combining these two architectures allows us to mitigate the problems inherent in each, resulting in improved performance on image super-resolution tasks.