3DGS$^2$: Near Second-order Converging 3D Gaussian Splatting
作者: Lei Lan, Tianjia Shao, Zixuan Lu, Yu Zhang, Chenfanfu Jiang, Yin Yang
分类: cs.CV, cs.GR
发布日期: 2025-01-22 (更新: 2025-01-27)
备注: 11 pages
💡 一句话要点
提出3DGS$^2$,利用近二阶收敛算法加速3D高斯溅射训练,显著提升训练效率。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D高斯溅射 新视角合成 二阶优化 牛顿法 GPU加速 快速训练 3D重建
📋 核心要点
- 现有3DGS训练依赖SGD,收敛速度慢,训练时间长,难以满足实时应用需求。
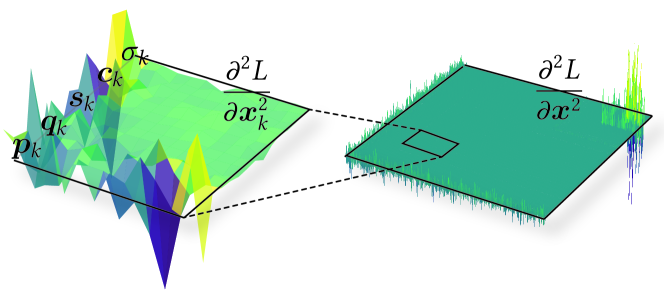
- 利用高斯核属性的独立性和图像间核的稀疏耦合性,构建局部牛顿系统加速训练。
- 实验表明,该方法比传统3DGS训练速度提升一个数量级,且重建质量不下降。
📝 摘要(中文)
3D高斯溅射(3DGS)已成为新视角合成和3D重建的主流解决方案。通过使用高斯核集合显式地编码3D场景,3DGS实现了高质量的渲染和卓越的效率。作为一种基于学习的方法,3DGS训练通常采用标准随机梯度下降(SGD)方法,该方法最多提供线性收敛。因此,即使使用GPU加速,训练也通常需要几十分钟。本文为3DGS引入了一种(近)二阶收敛训练算法,利用了其独特的性质。我们的方法受到两个关键观察结果的启发。首先,高斯核的属性对图像空间损失的贡献是独立的,这支持了孤立的和局部的优化算法。我们通过在单个内核属性级别上分割优化,为每个参数组分析地构建小尺寸牛顿系统,并在GPU线程上有效地解决这些系统来利用这一点。这实现了每个训练图像的类牛顿收敛,而无需依赖全局Hessian矩阵。其次,内核在输入图像中表现出稀疏和结构化的耦合。此属性使我们能够有效地利用空间信息来减轻随机训练期间的过冲。我们的方法比基于GPU的标准3DGS训练收敛速度快一个数量级,所需的迭代次数减少了10倍以上,同时保持或超过了基于SGD的3DGS重建的质量。
🔬 方法详解
问题定义:3D高斯溅射(3DGS)虽然在高质量新视角合成方面表现出色,但其训练过程依赖于随机梯度下降(SGD),收敛速度慢,训练时间长,限制了其在实时应用中的潜力。现有方法难以在保证重建质量的同时,显著提升训练效率。
核心思路:论文的核心思路是利用3DGS中高斯核的两个关键特性来加速训练:一是高斯核的各个属性(如位置、缩放、旋转等)对图像空间损失的贡献是相对独立的,这允许对每个属性进行局部优化;二是不同图像之间的高斯核存在稀疏且结构化的耦合关系,可以利用空间信息来抑制训练过程中的过冲现象。
技术框架:该方法主要分为两个阶段。首先,针对每个高斯核的属性,构建一个小的牛顿系统,该系统基于该属性对损失函数的二阶导数(Hessian矩阵)的近似。然后,在GPU线程上并行地求解这些小规模的牛顿系统,从而实现对每个属性的快速更新。其次,利用高斯核在不同图像之间的空间关系,设计一种机制来平滑训练过程,减少过冲,进一步加速收敛。
关键创新:该方法最重要的创新在于将二阶优化方法(牛顿法)引入到3DGS的训练中,并且巧妙地利用了高斯核的独立性和耦合性,避免了直接计算和存储全局Hessian矩阵的巨大开销。与传统的SGD方法相比,该方法能够实现更快的收敛速度。
关键设计:关键设计包括:1) 如何针对每个高斯核属性构建小规模的牛顿系统,并高效地在GPU上求解;2) 如何利用高斯核的空间关系来设计平滑机制,抑制训练过程中的过冲;3) 如何平衡局部优化和全局一致性,以保证重建质量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在保持或超过传统基于SGD的3DGS重建质量的前提下,训练速度提升了一个数量级以上,所需的迭代次数减少了10倍以上。这使得3DGS的训练时间从几十分钟缩短到几分钟,显著提升了其实用性。
🎯 应用场景
该研究成果可广泛应用于需要快速3D重建和新视角合成的领域,例如:实时虚拟现实、增强现实、机器人导航、自动驾驶、游戏开发等。更快的训练速度使得3DGS能够应用于动态场景的重建,并降低了对计算资源的需求,促进了其在移动设备上的部署。
📄 摘要(原文)
3D Gaussian Splatting (3DGS) has emerged as a mainstream solution for novel view synthesis and 3D reconstruction. By explicitly encoding a 3D scene using a collection of Gaussian kernels, 3DGS achieves high-quality rendering with superior efficiency. As a learning-based approach, 3DGS training has been dealt with the standard stochastic gradient descent (SGD) method, which offers at most linear convergence. Consequently, training often requires tens of minutes, even with GPU acceleration. This paper introduces a (near) second-order convergent training algorithm for 3DGS, leveraging its unique properties. Our approach is inspired by two key observations. First, the attributes of a Gaussian kernel contribute independently to the image-space loss, which endorses isolated and local optimization algorithms. We exploit this by splitting the optimization at the level of individual kernel attributes, analytically constructing small-size Newton systems for each parameter group, and efficiently solving these systems on GPU threads. This achieves Newton-like convergence per training image without relying on the global Hessian. Second, kernels exhibit sparse and structured coupling across input images. This property allows us to effectively utilize spatial information to mitigate overshoot during stochastic training. Our method converges an order faster than standard GPU-based 3DGS training, requiring over $10\times$ fewer iterations while maintaining or surpassing the quality of the compared with the SGD-based 3DGS reconstructions.