VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
作者: Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, Peng Jin, Wenqi Zhang, Fan Wang, Lidong Bing, Deli Zhao
分类: cs.CV
发布日期: 2025-01-22 (更新: 2025-06-03)
备注: BZ, KL, ZC, ZH, YY, GC, SL, YJ, HZ, and XL contributed equally to this project. Code: https://github.com/DAMO-NLP-SG/VideoLLaMA3
💡 一句话要点
VideoLLaMA3:面向图像和视频理解的前沿多模态基础模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视频理解 图像理解 视觉语言模型 大模型 视觉中心 可变分辨率 细粒度特征
📋 核心要点
- 现有方法在视频理解方面面临挑战,尤其是在数据效率和细粒度特征捕捉上存在不足。
- VideoLLaMA3采用视觉中心范式,侧重高质量图像文本数据,并优化视觉编码器以处理变分辨率图像。
- 实验结果表明,VideoLLaMA3在图像和视频理解任务中表现出色,证明了其视觉中心设计的有效性。
📝 摘要(中文)
本文提出了VideoLLaMA3,一种更先进的用于图像和视频理解的多模态基础模型。VideoLLaMA3的核心设计理念是“视觉中心”。“视觉中心”的含义体现在两个方面:以视觉为中心的训练范式和以视觉为中心的框架设计。我们以视觉为中心的训练范式的关键在于高质量的图像-文本数据对于图像和视频理解至关重要。我们没有准备大量的视频-文本数据集,而是专注于构建大规模和高质量的图像-文本数据集。VideoLLaMA3有四个训练阶段:1) 视觉编码器适配,使视觉编码器能够接受可变分辨率的图像作为输入;2) 视觉-语言对齐,使用涵盖多种类型(包括场景图像、文档、图表)的大规模图像-文本数据以及纯文本数据,联合调整视觉编码器、投影器和LLM;3) 多任务微调,结合用于下游任务的图像-文本SFT数据和视频-文本数据,为视频理解奠定基础;4) 以视频为中心的微调,进一步提高模型在视频理解方面的能力。在框架设计方面,为了更好地捕捉图像中的细粒度细节,预训练的视觉编码器被调整为将不同大小的图像编码为具有相应数量的视觉tokens,而不是固定数量的tokens。对于视频输入,我们根据视觉tokens的相似性减少其数量,从而使视频的表示更加精确和紧凑。受益于以视觉为中心的设计,VideoLLaMA3在图像和视频理解基准测试中取得了令人瞩目的性能。
🔬 方法详解
问题定义:现有视频理解模型通常依赖于大规模视频-文本数据集,这导致数据收集和标注成本高昂。此外,现有模型在捕捉视频中的细粒度细节方面存在不足,限制了其在复杂场景下的应用。
核心思路:VideoLLaMA3的核心思路是采用“视觉中心”范式,即认为高质量的图像-文本数据对于图像和视频理解至关重要。通过专注于构建大规模和高质量的图像-文本数据集,并优化视觉编码器以更好地捕捉图像和视频中的细粒度细节,从而提高模型的性能和数据效率。
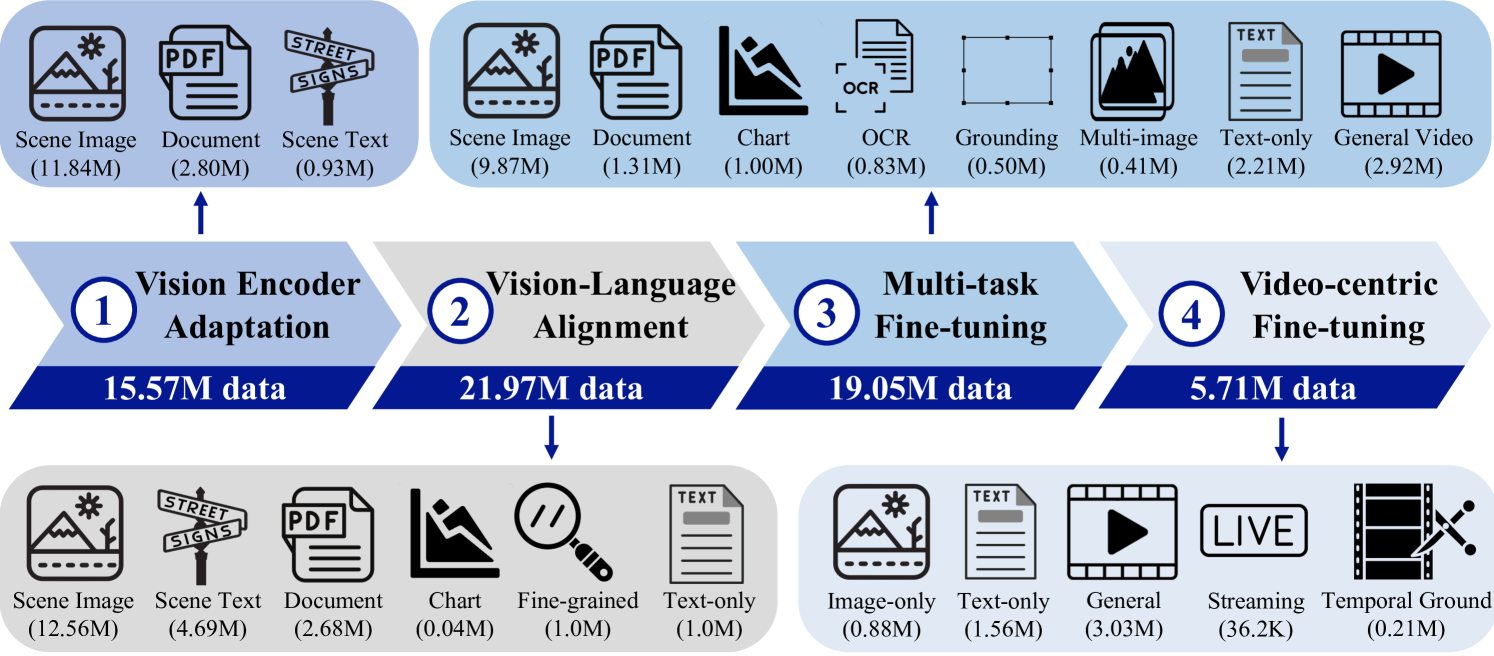
技术框架:VideoLLaMA3的整体框架包括四个训练阶段:1) 视觉编码器适配:使视觉编码器能够接受可变分辨率的图像作为输入。2) 视觉-语言对齐:使用大规模图像-文本数据联合调整视觉编码器、投影器和LLM。3) 多任务微调:结合图像-文本SFT数据和视频-文本数据,为下游任务和视频理解奠定基础。4) 以视频为中心的微调:进一步提高模型在视频理解方面的能力。
关键创新:VideoLLaMA3的关键创新在于其“视觉中心”的训练范式和框架设计。与现有方法不同,VideoLLaMA3更加注重高质量的图像-文本数据,并优化视觉编码器以更好地捕捉图像和视频中的细粒度细节。此外,VideoLLaMA3还采用了可变数量的视觉tokens来表示不同大小的图像,从而提高了模型的灵活性和表达能力。
关键设计:在视觉编码器适配阶段,采用了自适应的图像分辨率处理方法,允许模型接受不同大小的图像输入。在视觉-语言对齐阶段,使用了多种类型的图像-文本数据,包括场景图像、文档和图表。在视频输入处理方面,根据视觉tokens的相似性减少其数量,以实现更精确和紧凑的视频表示。
🖼️ 关键图片

📊 实验亮点
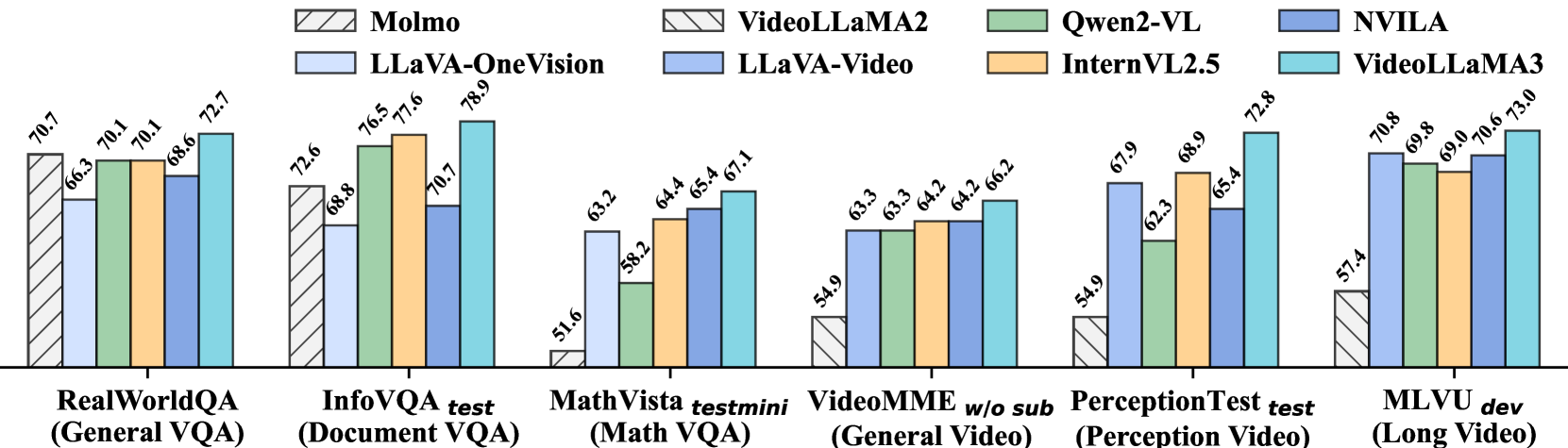
VideoLLaMA3在图像和视频理解基准测试中取得了显著的性能提升,证明了其视觉中心设计的有效性。具体的性能数据和对比基线信息在论文中详细展示,表明VideoLLaMA3在多个任务上优于现有模型。
🎯 应用场景
VideoLLaMA3在多个领域具有广泛的应用前景,包括智能监控、视频内容分析、自动驾驶、医疗影像诊断等。该模型能够更准确地理解图像和视频内容,从而为这些应用提供更可靠的支持。未来,VideoLLaMA3有望成为多模态人工智能领域的重要基石。
📄 摘要(原文)
In this paper, we propose VideoLLaMA3, a more advanced multimodal foundation model for image and video understanding. The core design philosophy of VideoLLaMA3 is vision-centric. The meaning of "vision-centric" is two-fold: the vision-centric training paradigm and vision-centric framework design. The key insight of our vision-centric training paradigm is that high-quality image-text data is crucial for both image and video understanding. Instead of preparing massive video-text datasets, we focus on constructing large-scale and high-quality image-text datasets. VideoLLaMA3 has four training stages: 1) Vision Encoder Adaptation, which enables vision encoder to accept images of variable resolutions as input; 2) Vision-Language Alignment, which jointly tunes the vision encoder, projector, and LLM with large-scale image-text data covering multiple types (including scene images, documents, charts) as well as text-only data. 3) Multi-task Fine-tuning, which incorporates image-text SFT data for downstream tasks and video-text data to establish a foundation for video understanding. 4) Video-centric Fine-tuning, which further improves the model's capability in video understanding. As for the framework design, to better capture fine-grained details in images, the pretrained vision encoder is adapted to encode images of varying sizes into vision tokens with corresponding numbers, rather than a fixed number of tokens. For video inputs, we reduce the number of vision tokens according to their similarity so that the representation of videos will be more precise and compact. Benefit from vision-centric designs, VideoLLaMA3 achieves compelling performances in both image and video understanding benchmarks.