Enhancing Monocular Depth Estimation with Multi-Source Auxiliary Tasks
作者: Alessio Quercia, Erenus Yildiz, Zhuo Cao, Kai Krajsek, Abigail Morrison, Ira Assent, Hanno Scharr
分类: cs.CV
发布日期: 2025-01-22
备注: Paper accepted at WACV 2025
期刊: WACV 2025
DOI: 10.1109/WACV61041.2025.00627
💡 一句话要点
提出多源辅助任务的单目深度估计方法,提升数据效率和深度预测质量。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 单目深度估计 多任务学习 辅助任务 数据效率 深度学习 语义分割 视觉基础模型
📋 核心要点
- 单目深度估计依赖高质量标注数据,但数据获取成本高昂且稀缺,限制了模型性能。
- 利用相关视觉任务的辅助数据集,通过交替训练和共享解码器,提升单目深度估计的质量。
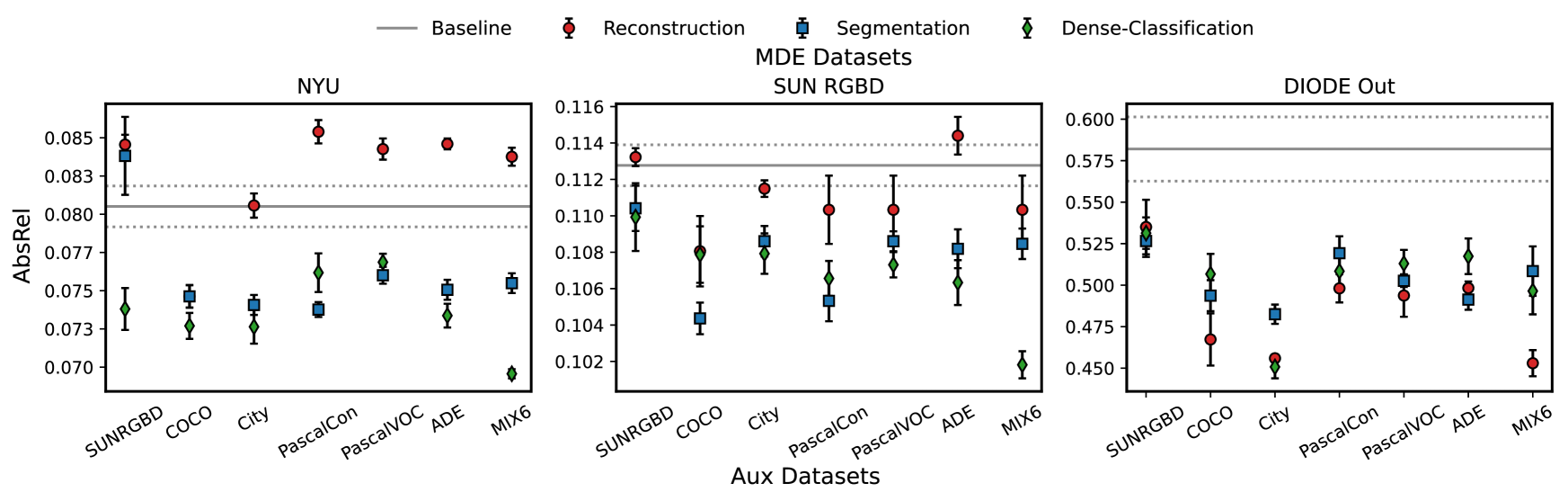
- 实验表明,该方法平均提升深度估计质量约11%,并显著提高了数据效率,减少了对大规模标注数据的依赖。
📝 摘要(中文)
单目深度估计(MDE)是计算机视觉中一项具有挑战性的任务,通常受到高质量标注数据集成本高昂和稀缺的限制。本文通过使用来自相关视觉任务的辅助数据集,采用交替训练方案来解决这一挑战。该方案基于预训练的视觉基础模型构建共享解码器,并赋予MDE更高的权重。通过广泛的实验,证明了结合各种领域内辅助数据集和任务可以平均提高约11%的MDE质量。实验分析表明,辅助任务具有不同的影响,证实了任务选择的重要性,并强调了质量的提升并非仅仅通过增加数据来实现。值得注意的是,研究表明,使用语义分割数据集作为多标签密集分类(MLDC)通常会导致额外的质量提升。最后,该方法显著提高了所考虑的MDE数据集的数据效率,在将数据集大小减少至少80%的同时,提高了其质量。这为使用来自相关任务的辅助数据来提高MDE质量铺平了道路,即使高质量标注数据的可用性有限。
🔬 方法详解
问题定义:单目深度估计(MDE)任务面临高质量标注数据稀缺的挑战,现有方法难以在有限数据下达到理想的精度。直接训练的模型容易过拟合,泛化能力不足。
核心思路:利用来自相关视觉任务(如语义分割)的辅助数据集,通过多任务学习的方式,提升单目深度估计模型的泛化能力和数据效率。核心在于利用辅助任务提供的额外信息,约束深度估计模型的学习过程,从而提高其性能。
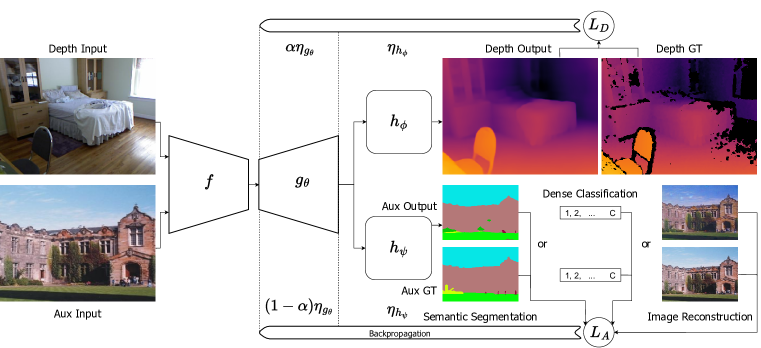
技术框架:整体框架包含一个共享的解码器,该解码器建立在预训练的视觉基础模型之上。训练过程采用交替训练方案,即在每个训练迭代中,轮流使用单目深度估计数据集和辅助数据集进行训练。针对不同的任务,使用相应的损失函数进行优化。
关键创新:该方法的核心创新在于有效利用了多源辅助任务来提升单目深度估计的性能。特别地,研究发现将语义分割数据集作为多标签密集分类(MLDC)任务进行训练,可以带来额外的性能提升。此外,该方法显著提高了数据效率,能够在减少训练数据量的情况下,保持甚至提升深度估计的精度。
关键设计:在训练过程中,对单目深度估计任务赋予更高的权重,以保证其性能。对于语义分割数据集,将其转化为多标签密集分类任务,即将每个像素的类别标签视为一个独立的标签。损失函数方面,针对单目深度估计任务,采用常用的深度回归损失函数;针对辅助任务,采用交叉熵损失函数等。具体的网络结构和参数设置在论文中有详细描述,代码已开源。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在单目深度估计任务上取得了显著的性能提升,平均提升约11%。更重要的是,该方法显著提高了数据效率,能够在减少至少80%训练数据的情况下,保持甚至提升深度估计的精度。研究还发现,将语义分割数据集作为多标签密集分类(MLDC)任务进行训练,可以带来额外的性能提升。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、机器人导航、增强现实等领域。在这些场景中,准确的深度信息至关重要。该方法通过利用辅助数据,降低了对大规模高质量标注数据的依赖,使得单目深度估计技术能够更容易地部署到资源受限的环境中,具有重要的实际应用价值。
📄 摘要(原文)
Monocular depth estimation (MDE) is a challenging task in computer vision, often hindered by the cost and scarcity of high-quality labeled datasets. We tackle this challenge using auxiliary datasets from related vision tasks for an alternating training scheme with a shared decoder built on top of a pre-trained vision foundation model, while giving a higher weight to MDE. Through extensive experiments we demonstrate the benefits of incorporating various in-domain auxiliary datasets and tasks to improve MDE quality on average by ~11%. Our experimental analysis shows that auxiliary tasks have different impacts, confirming the importance of task selection, highlighting that quality gains are not achieved by merely adding data. Remarkably, our study reveals that using semantic segmentation datasets as Multi-Label Dense Classification (MLDC) often results in additional quality gains. Lastly, our method significantly improves the data efficiency for the considered MDE datasets, enhancing their quality while reducing their size by at least 80%. This paves the way for using auxiliary data from related tasks to improve MDE quality despite limited availability of high-quality labeled data. Code is available at https://jugit.fz-juelich.de/ias-8/mdeaux.