Continuous 3D Perception Model with Persistent State
作者: Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A. Efros, Angjoo Kanazawa
分类: cs.CV
发布日期: 2025-01-21
💡 一句话要点
提出CUT3R,利用持续状态的循环模型解决连续3D感知任务。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D重建 连续感知 循环模型 Transformer 场景补全 动态场景 状态表示 点云图
📋 核心要点
- 现有3D重建方法难以处理连续输入,无法有效利用时序信息进行场景理解和补全。
- CUT3R利用Transformer构建循环模型,通过持续更新的状态表示,融合时序信息,实现场景的增量式重建和补全。
- 实验表明,CUT3R在多种3D/4D任务上取得了优异的性能,尤其在场景补全和动态场景重建方面。
📝 摘要(中文)
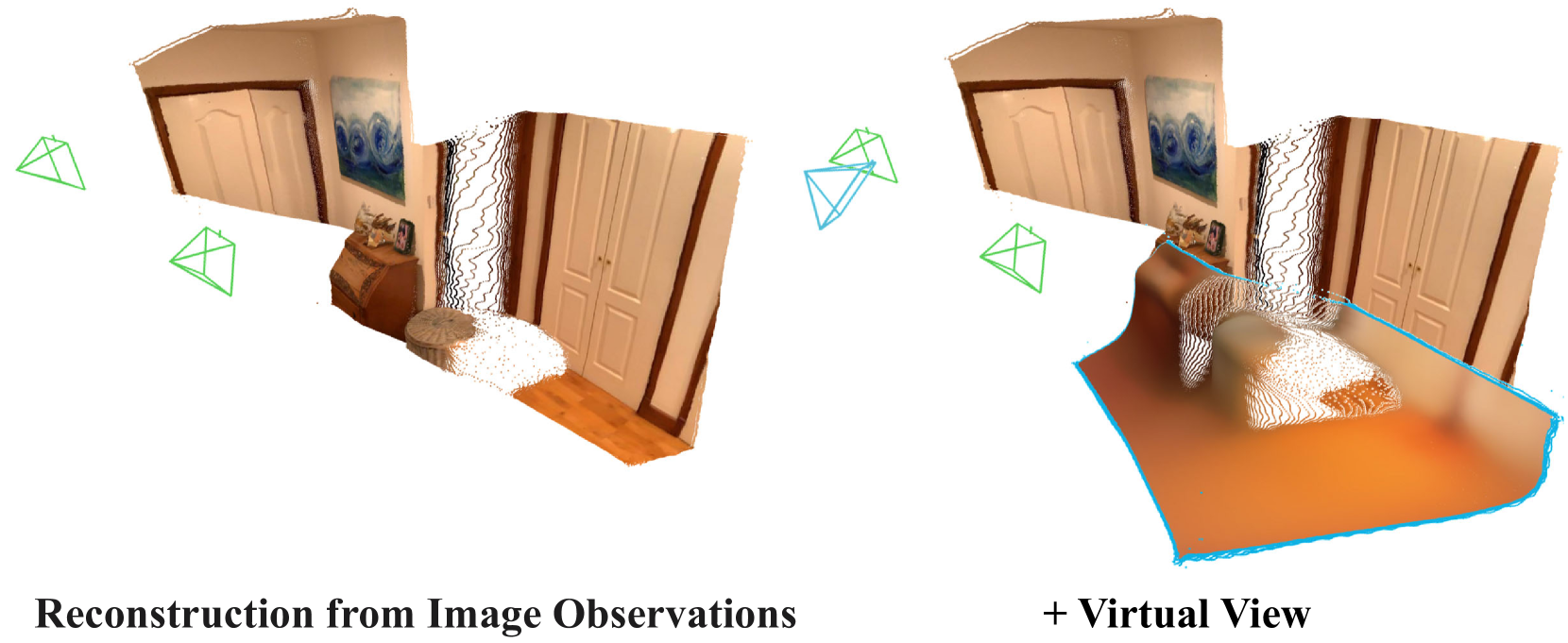
本文提出了一个统一的框架,能够解决广泛的3D任务。该方法采用一个具有状态的循环模型,通过每个新的观测不断更新其状态表示。给定图像流,这种演化的状态可以用于在线生成每个新输入的度量尺度点云图(逐像素3D点)。这些点云图位于一个共同的坐标系中,可以累积成一个连贯的、密集的场景重建,并随着新图像的到来而更新。我们的模型CUT3R(用于3D重建的连续更新Transformer)捕捉了真实世界场景的丰富先验知识:它不仅可以从图像观测中预测准确的点云图,还可以通过探测虚拟的、未观测的视角来推断场景中未见区域。我们的方法简单而高度灵活,自然地接受不同长度的图像,这些图像可以是视频流或无序的照片集,包含静态和动态内容。我们在各种3D/4D任务上评估了我们的方法,并在每个任务中展示了有竞争力的或最先进的性能。项目主页:https://cut3r.github.io/
🔬 方法详解
问题定义:现有3D重建方法通常针对单张图像或短序列,难以处理长时间、连续的视频流或无序图像集合。它们无法有效地利用时序信息来提高重建质量,并且在遮挡或缺失区域的场景补全方面表现不佳。此外,现有方法难以处理动态场景,无法对场景中的运动物体进行准确建模和重建。
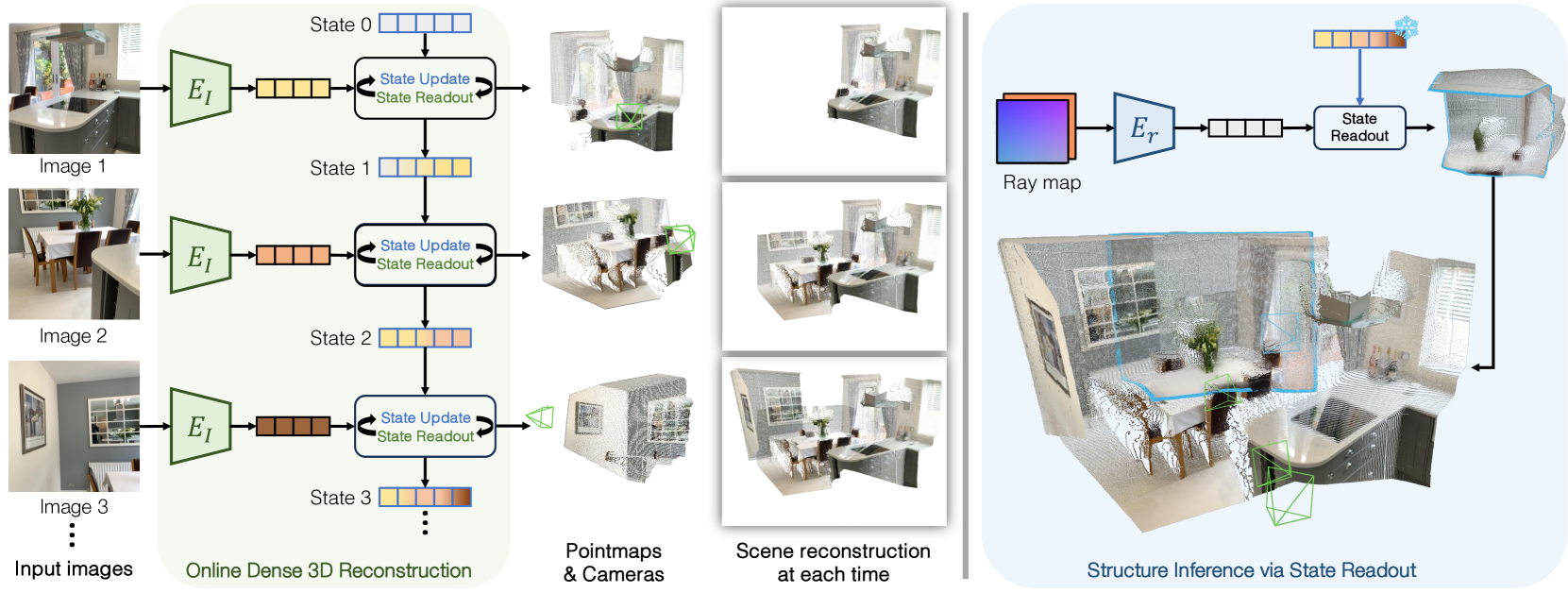
核心思路:CUT3R的核心思路是利用一个状态化的循环模型,该模型能够随着新的观测不断更新其内部状态。这个状态表示包含了对场景的持续理解,可以用于预测每个新输入的点云图,并将其累积到统一的坐标系中。通过这种方式,模型能够逐步构建一个连贯、密集的场景重建,并利用时序信息来推断未见区域。
技术框架:CUT3R的整体架构包含以下主要模块:1) 图像编码器:将输入的图像编码成特征向量。2) 状态更新模块:利用Transformer网络,将图像特征和当前状态进行融合,更新状态表示。3) 点云图预测模块:根据更新后的状态,预测当前帧的点云图。4) 累积模块:将预测的点云图累积到全局坐标系中,形成场景重建。整个流程是循环进行的,每一帧图像都会更新状态并生成新的点云图。
关键创新:CUT3R的关键创新在于其状态化的循环模型和Transformer网络的应用。状态化的循环模型允许模型记住之前的观测,并利用时序信息来提高重建质量和进行场景补全。Transformer网络能够有效地融合图像特征和状态表示,捕捉场景中的长程依赖关系。与现有方法相比,CUT3R能够处理更长的输入序列,并且在场景补全和动态场景重建方面表现更好。
关键设计:CUT3R的关键设计包括:1) 使用Transformer网络作为状态更新模块,以捕捉长程依赖关系。2) 设计了专门的损失函数,用于鼓励模型预测准确的点云图和进行有效的场景补全。3) 采用了一种自监督学习策略,利用虚拟视角来训练模型进行场景补全。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
CUT3R在多个3D/4D任务上取得了有竞争力的或最先进的性能。例如,在场景补全任务中,CUT3R能够有效地推断未见区域,生成逼真的场景重建。在动态场景重建任务中,CUT3R能够准确地建模和重建运动物体,优于现有方法。具体的数据指标和对比结果可以在论文的实验部分找到。
🎯 应用场景
CUT3R具有广泛的应用前景,包括:1) 机器人导航:帮助机器人理解周围环境,进行自主导航和避障。2) 虚拟现实/增强现实:生成逼真的3D场景,提供沉浸式的用户体验。3) 自动驾驶:构建高精度的地图,提高自动驾驶系统的安全性。4) 场景重建:对现实世界进行数字化建模,用于城市规划、文物保护等领域。
📄 摘要(原文)
We present a unified framework capable of solving a broad range of 3D tasks. Our approach features a stateful recurrent model that continuously updates its state representation with each new observation. Given a stream of images, this evolving state can be used to generate metric-scale pointmaps (per-pixel 3D points) for each new input in an online fashion. These pointmaps reside within a common coordinate system, and can be accumulated into a coherent, dense scene reconstruction that updates as new images arrive. Our model, called CUT3R (Continuous Updating Transformer for 3D Reconstruction), captures rich priors of real-world scenes: not only can it predict accurate pointmaps from image observations, but it can also infer unseen regions of the scene by probing at virtual, unobserved views. Our method is simple yet highly flexible, naturally accepting varying lengths of images that may be either video streams or unordered photo collections, containing both static and dynamic content. We evaluate our method on various 3D/4D tasks and demonstrate competitive or state-of-the-art performance in each. Project Page: https://cut3r.github.io/