MMVU: Measuring Expert-Level Multi-Discipline Video Understanding
作者: Yilun Zhao, Lujing Xie, Haowei Zhang, Guo Gan, Yitao Long, Zhiyuan Hu, Tongyan Hu, Weiyuan Chen, Chuhan Li, Junyang Song, Zhijian Xu, Chengye Wang, Weifeng Pan, Ziyao Shangguan, Xiangru Tang, Zhenwen Liang, Yixin Liu, Chen Zhao, Arman Cohan
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-01-21
💡 一句话要点
MMVU:提出专家级多学科视频理解评测基准,挑战通用模型在专业领域的知识推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频理解 多模态学习 专家级推理 知识密集型 基准数据集
📋 核心要点
- 现有视频理解基准侧重于基本视觉感知,缺乏对领域特定知识和专家级推理能力的考察。
- MMVU基准通过专家标注的多学科视频理解问题,挑战模型在专业领域的知识应用和推理能力。
- 实验表明,即使是最先进的模型在MMVU上仍远低于人类专家水平,揭示了现有模型的不足。
📝 摘要(中文)
本文提出了MMVU,一个综合性的专家级、多学科视频理解基准,用于评估基础模型。MMVU包含3000个由专家标注的问题,涵盖科学、医疗保健、人文社科和工程四个核心学科的27个主题。与之前的基准相比,MMVU具有三个关键优势。首先,它挑战模型应用领域特定知识并执行专家级推理来分析专业领域视频,超越了当前视频基准中评估的基本视觉感知。其次,每个示例都由人类专家从头开始标注,并实施严格的数据质量控制以确保数据集的高质量。最后,每个示例都通过专家标注的推理依据和相关领域知识进行丰富,从而促进深入分析。在MMVU上对32个前沿多模态基础模型进行了广泛评估。最新的具备System-2能力的模型,如o1和Gemini 2.0 Flash Thinking,在测试模型中表现最佳,但仍未达到人类专家的水平。通过深入的错误分析和案例研究,为专业领域专家级、知识密集型视频理解的未来发展提供了可操作的见解。
🔬 方法详解
问题定义:现有视频理解基准主要关注基础的视觉感知能力,缺乏对模型在特定领域知识的运用和专家级别的推理能力的考察。这些基准难以评估模型在专业领域的实际应用潜力。因此,需要一个能够全面评估模型在多学科领域进行专家级视频理解能力的基准。
核心思路:MMVU的核心思路是构建一个高质量、多学科、专家标注的视频理解数据集,该数据集不仅包含视频内容,还包含专家标注的推理依据和相关领域知识。通过在该数据集上评估模型,可以更全面地了解模型在专业领域的知识应用和推理能力。
技术框架:MMVU数据集的构建流程主要包括以下几个阶段:1) 确定学科领域和主题;2) 收集相关视频;3) 由领域专家设计问题并进行标注;4) 对标注数据进行质量控制;5) 补充专家标注的推理依据和相关领域知识。评估过程则是将视频和问题输入到多模态模型中,然后将模型的答案与专家标注的答案进行比较,从而评估模型的性能。
关键创新:MMVU的关键创新在于其专家级的标注和多学科的覆盖范围。与以往的视频理解基准相比,MMVU更加注重考察模型在专业领域的知识应用和推理能力。此外,MMVU还提供了专家标注的推理依据和相关领域知识,这有助于深入分析模型的错误,并为未来的研究提供指导。
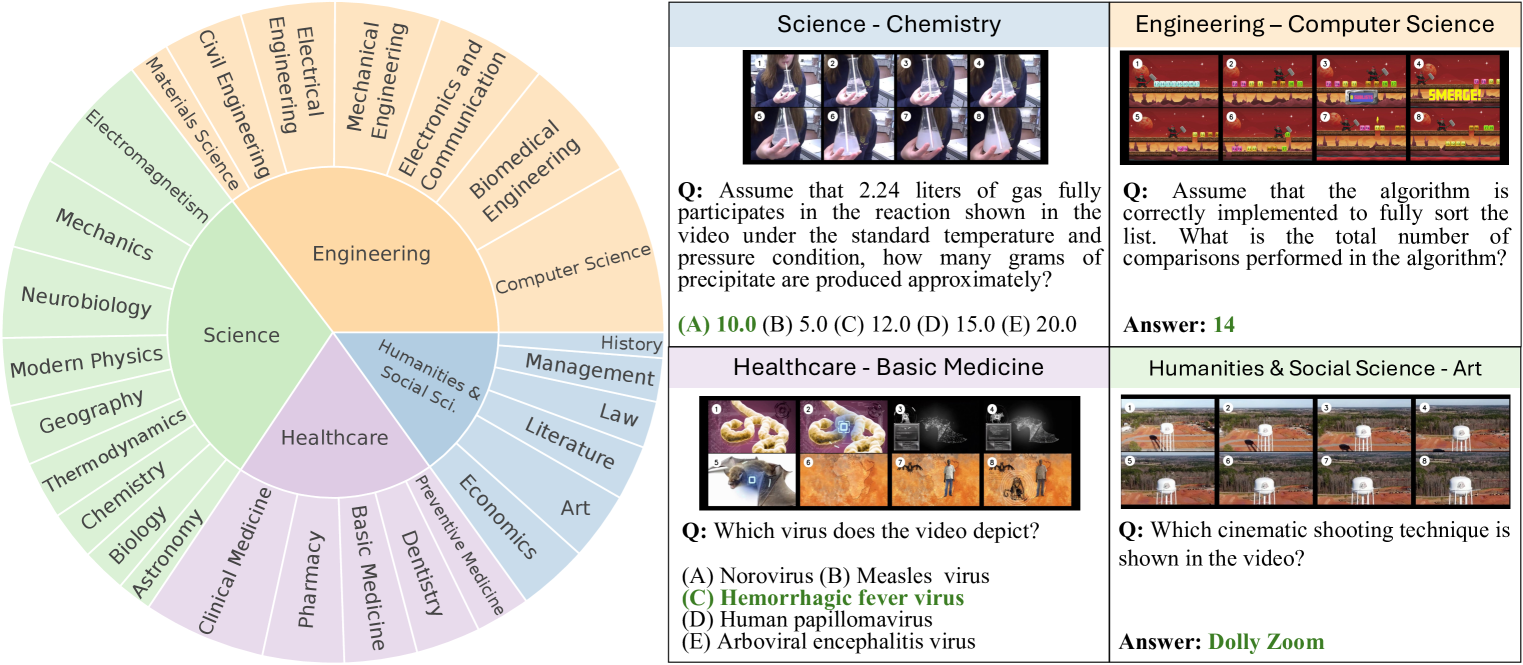
关键设计:MMVU数据集涵盖了科学、医疗保健、人文社科和工程四个核心学科的27个主题,共包含3000个专家标注的问题。每个问题都经过严格的质量控制,以确保数据集的准确性和可靠性。此外,每个问题都附带专家标注的推理依据和相关领域知识,这有助于深入分析模型的错误,并为未来的研究提供指导。具体的模型评估指标未知。
🖼️ 关键图片


📊 实验亮点
在MMVU基准上,最新的System-2-capable模型,如o1和Gemini 2.0 Flash Thinking,表现最佳,但仍远低于人类专家水平。这表明现有模型在专家级、知识密集型视频理解方面仍有很大的提升空间。通过对模型错误进行深入分析,可以为未来的研究提供有价值的指导。
🎯 应用场景
MMVU基准的提出,能够推动多模态模型在专业领域的应用,例如辅助医疗诊断、科学研究、工程设计等。通过不断提升模型在MMVU上的性能,可以开发出更智能、更可靠的专业领域视频理解系统,从而提高工作效率和决策质量。未来,可以进一步扩展MMVU的学科范围和问题类型,使其更具通用性和实用性。
📄 摘要(原文)
We introduce MMVU, a comprehensive expert-level, multi-discipline benchmark for evaluating foundation models in video understanding. MMVU includes 3,000 expert-annotated questions spanning 27 subjects across four core disciplines: Science, Healthcare, Humanities & Social Sciences, and Engineering. Compared to prior benchmarks, MMVU features three key advancements. First, it challenges models to apply domain-specific knowledge and perform expert-level reasoning to analyze specialized-domain videos, moving beyond the basic visual perception typically assessed in current video benchmarks. Second, each example is annotated by human experts from scratch. We implement strict data quality controls to ensure the high quality of the dataset. Finally, each example is enriched with expert-annotated reasoning rationals and relevant domain knowledge, facilitating in-depth analysis. We conduct an extensive evaluation of 32 frontier multimodal foundation models on MMVU. The latest System-2-capable models, o1 and Gemini 2.0 Flash Thinking, achieve the highest performance among the tested models. However, they still fall short of matching human expertise. Through in-depth error analyses and case studies, we offer actionable insights for future advancements in expert-level, knowledge-intensive video understanding for specialized domains.