Video Depth Anything: Consistent Depth Estimation for Super-Long Videos
作者: Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zilong Huang, Jiashi Feng, Bingyi Kang
分类: cs.CV, cs.AI
发布日期: 2025-01-21 (更新: 2025-06-15)
备注: Project page: https://videodepthanything.github.io/
💡 一句话要点
Video Depth Anything:为超长视频提供一致性深度估计
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视频深度估计 时间一致性 单目深度估计 深度学习 长视频处理
📋 核心要点
- 现有方法在处理长视频深度估计时,面临时间一致性差、计算效率低以及对几何先验依赖等挑战。
- Video Depth Anything通过设计高效的时空头和时序一致性损失,在保证质量的同时提升了计算效率。
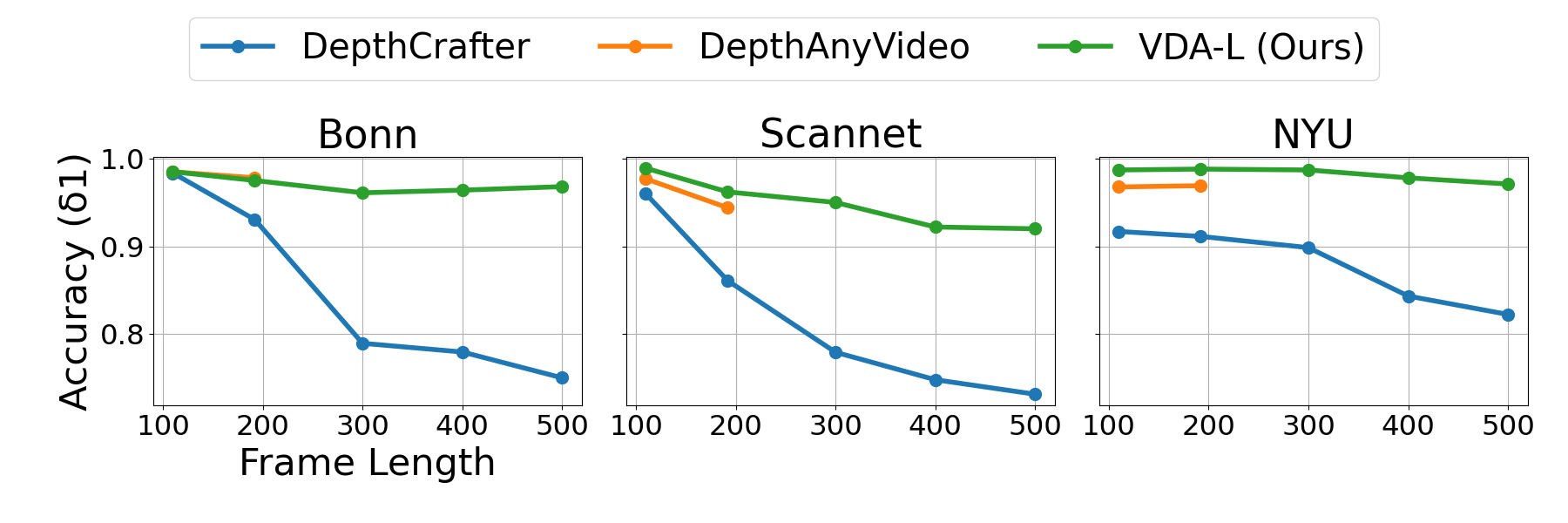
- 实验结果表明,该方法在多个视频基准测试中达到了新的state-of-the-art,且能实时处理视频。
📝 摘要(中文)
Depth Anything在单目深度估计方面取得了显著成功,具有很强的泛化能力。然而,它在视频中存在时间不一致性问题,阻碍了其在实际应用中的应用。目前的一些方法试图通过利用视频生成模型或引入光流和相机姿态的先验知识来缓解这个问题。但是,这些方法仅适用于短视频(<10秒),并且需要在质量和计算效率之间进行权衡。我们提出了Video Depth Anything,用于在超长视频(几分钟以上)中进行高质量、一致的深度估计,且不牺牲效率。我们的模型基于Depth Anything V2,并用高效的时空头替换了它的头部。我们设计了一个简单而有效的时序一致性损失,通过约束时序深度梯度,消除了对额外几何先验的需求。该模型在视频深度和未标记图像的联合数据集上进行训练,类似于Depth Anything V2。此外,还开发了一种新颖的基于关键帧的策略,用于长视频推理。实验表明,我们的模型可以应用于任意长度的视频,而不会影响质量、一致性或泛化能力。在多个视频基准上的综合评估表明,我们的方法在零样本视频深度估计方面树立了新的技术水平。我们提供不同规模的模型,以支持各种场景,我们最小的模型能够以30 FPS的速度实现实时性能。
🔬 方法详解
问题定义:论文旨在解决单目视频深度估计中,现有方法在处理超长视频时存在的时序不一致性问题。现有方法通常依赖光流或相机位姿等几何先验,计算复杂度高,且仅适用于短视频。此外,质量和效率之间存在权衡,难以兼顾。
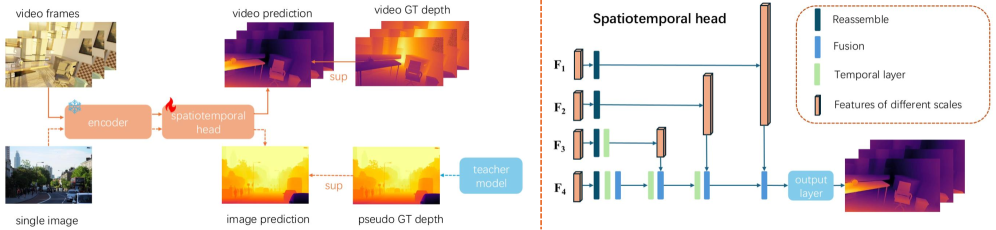
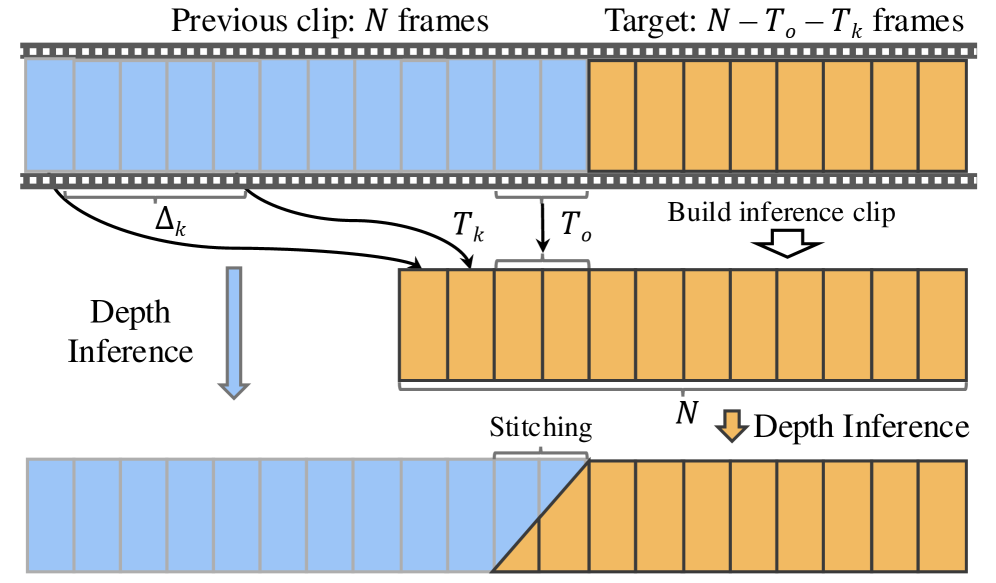
核心思路:论文的核心思路是基于Depth Anything V2,通过引入高效的时空头和时序一致性损失,直接在深度图层面约束时间一致性,避免了对额外几何先验的依赖。同时,采用关键帧策略来处理超长视频,降低计算量。
技术框架:整体框架包括三个主要部分:1) 基于Depth Anything V2的深度估计 backbone;2) 用于融合时序信息的时空头;3) 用于约束时间一致性的时序一致性损失。在推理阶段,采用关键帧策略,仅对关键帧进行深度估计,其余帧通过插值获得。
关键创新:最重要的创新点在于时序一致性损失的设计,它直接约束相邻帧深度图梯度的一致性,无需光流或相机位姿等额外信息,简化了流程,提高了效率。此外,关键帧策略也是一个重要的创新,使得模型能够处理超长视频。
关键设计:时序一致性损失定义为相邻帧深度图梯度差的L1范数。时空头的具体结构未知,但强调了其高效性。关键帧的选择策略未知,但推测可能基于场景变化或帧间差异。
🖼️ 关键图片
📊 实验亮点
该方法在多个视频深度估计基准测试中取得了state-of-the-art的结果,证明了其在质量、一致性和泛化能力方面的优越性。此外,该模型能够在保证性能的同时,实现实时处理(30 FPS),使其更具实用性。论文提供了不同规模的模型,以适应不同的应用场景。
🎯 应用场景
该研究成果可广泛应用于机器人导航、自动驾驶、视频编辑、虚拟现实/增强现实等领域。高质量且时间一致的深度信息对于理解视频内容、构建三维场景以及实现各种智能应用至关重要。该方法能够处理超长视频,使其在实际应用中更具价值。
📄 摘要(原文)
Depth Anything has achieved remarkable success in monocular depth estimation with strong generalization ability. However, it suffers from temporal inconsistency in videos, hindering its practical applications. Various methods have been proposed to alleviate this issue by leveraging video generation models or introducing priors from optical flow and camera poses. Nonetheless, these methods are only applicable to short videos (< 10 seconds) and require a trade-off between quality and computational efficiency. We propose Video Depth Anything for high-quality, consistent depth estimation in super-long videos (over several minutes) without sacrificing efficiency. We base our model on Depth Anything V2 and replace its head with an efficient spatial-temporal head. We design a straightforward yet effective temporal consistency loss by constraining the temporal depth gradient, eliminating the need for additional geometric priors. The model is trained on a joint dataset of video depth and unlabeled images, similar to Depth Anything V2. Moreover, a novel key-frame-based strategy is developed for long video inference. Experiments show that our model can be applied to arbitrarily long videos without compromising quality, consistency, or generalization ability. Comprehensive evaluations on multiple video benchmarks demonstrate that our approach sets a new state-of-the-art in zero-shot video depth estimation. We offer models of different scales to support a range of scenarios, with our smallest model capable of real-time performance at 30 FPS.