VARGPT: Unified Understanding and Generation in a Visual Autoregressive Multimodal Large Language Model
作者: Xianwei Zhuang, Yuxin Xie, Yufan Deng, Liming Liang, Jinghan Ru, Yuguo Yin, Yuexian Zou
分类: cs.CV
发布日期: 2025-01-21
💡 一句话要点
VARGPT:视觉自回归多模态大语言模型,统一理解与生成任务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉理解 视觉生成 自回归模型 指令微调
📋 核心要点
- 现有MLLM在视觉理解和生成任务上通常采用分离的框架,缺乏统一性,限制了模型的能力。
- VARGPT通过next-token和next-scale预测范式,在自回归框架内统一视觉理解和生成,实现混合模态输入输出。
- 实验结果表明,VARGPT在视觉问答和推理任务上优于LLaVA-1.5,并具备自回归视觉生成和指令到图像合成能力。
📝 摘要(中文)
本文提出了VARGPT,一种新颖的多模态大语言模型(MLLM),它在单一的自回归框架内统一了视觉理解和生成。VARGPT采用next-token预测范式进行视觉理解,采用next-scale预测范式进行视觉自回归生成。VARGPT创新性地扩展了LLaVA架构,在MLLM中实现了高效的scale-wise自回归视觉生成,同时在单一模型框架内无缝地适应了混合模态的输入和输出。VARGPT在精心策划的数据集上经过了三阶段的统一训练过程,包括预训练阶段和两个混合视觉指令微调阶段。统一的训练策略旨在实现视觉和文本特征之间的对齐,增强对理解和生成的指令遵循能力,并提高视觉生成质量。尽管VARGPT基于LLAVA架构进行多模态理解,但它在各种以视觉为中心的基准测试中,例如视觉问答和推理任务,显著优于LLaVA-1.5。值得注意的是,VARGPT自然地支持自回归视觉生成和指令到图像合成的能力,展示了其在视觉理解和生成任务中的多功能性。
🔬 方法详解
问题定义:现有的大部分多模态大语言模型(MLLM)通常将视觉理解和视觉生成作为两个独立的任务来处理,导致模型结构复杂,难以实现两种能力的有效融合。此外,如何高效地在MLLM中实现高质量的自回归视觉生成也是一个挑战。
核心思路:VARGPT的核心思路是利用自回归模型统一视觉理解和生成任务。对于视觉理解,采用next-token预测范式;对于视觉生成,采用next-scale预测范式。通过这种方式,模型可以在同一个框架下处理不同模态的输入和输出,并实现视觉内容的自回归生成。
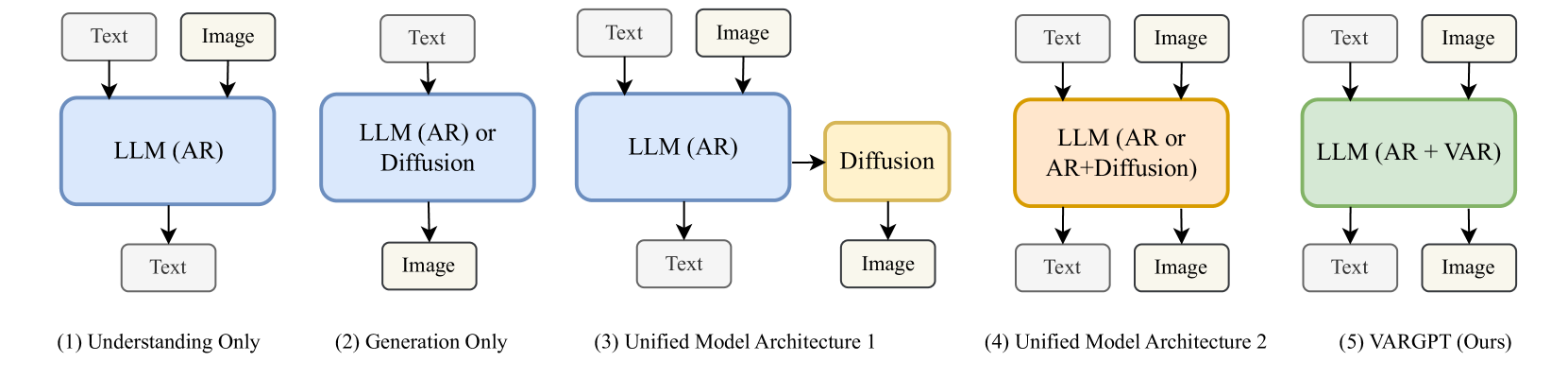
技术框架:VARGPT基于LLaVA架构进行扩展。整体框架包含视觉编码器、多模态连接器和语言模型三个主要部分。视觉编码器负责提取图像特征,多模态连接器将视觉特征与文本信息对齐,语言模型则负责生成文本或图像。模型训练分为三个阶段:预训练阶段用于对齐视觉和文本特征;第一阶段指令微调用于增强模型对指令的理解能力;第二阶段指令微调用于提高视觉生成质量。
关键创新:VARGPT的关键创新在于提出了scale-wise自回归视觉生成方法,并将其与视觉理解任务统一在同一个自回归框架下。这种方法允许模型以自回归的方式逐步生成图像,从而提高生成质量和控制能力。此外,VARGPT还设计了三阶段的统一训练策略,以实现视觉和文本特征的有效对齐,并提高模型在视觉理解和生成任务上的性能。
关键设计:VARGPT的关键设计包括:1) 使用LLaVA-1.5作为基础架构;2) 采用next-scale预测范式进行视觉生成,将图像分解为不同尺度的特征图,并以自回归的方式预测每个尺度的特征;3) 设计了三阶段的统一训练策略,包括预训练、指令微调(理解)和指令微调(生成);4) 使用了精心策划的数据集,以提高模型的视觉理解和生成能力。
🖼️ 关键图片

📊 实验亮点
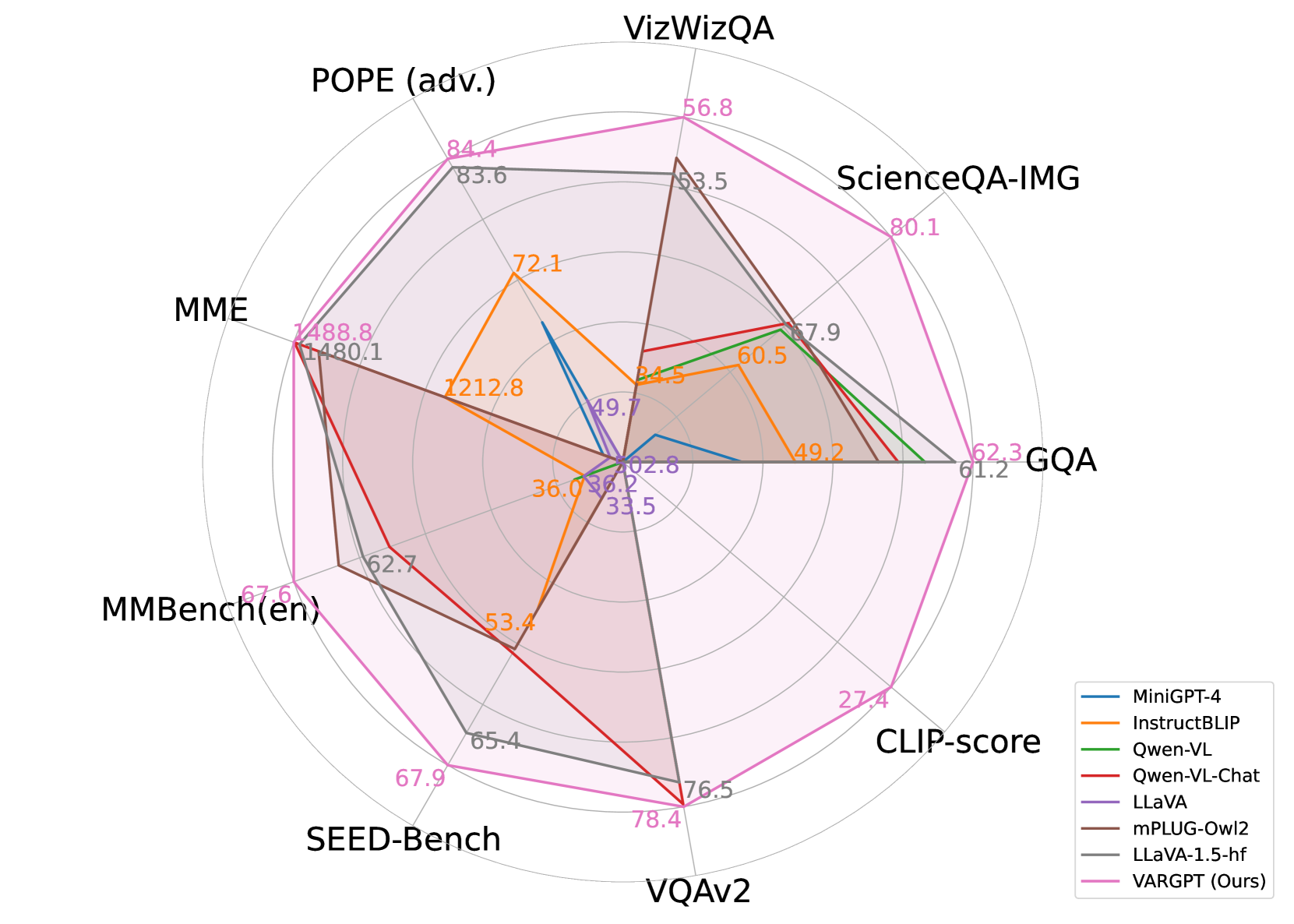
VARGPT在视觉问答和推理任务上显著优于LLaVA-1.5,证明了其在视觉理解方面的优越性能。此外,VARGPT还能够自然地支持自回归视觉生成和指令到图像合成,展示了其在视觉生成方面的强大能力。项目主页提供了更多实验结果和演示。
🎯 应用场景
VARGPT具有广泛的应用前景,包括图像编辑、图像修复、视觉内容创作、智能助手等。例如,用户可以通过文本指令来编辑图像,或者让模型根据文本描述生成新的图像。此外,VARGPT还可以应用于机器人领域,帮助机器人理解周围环境并生成相应的动作。
📄 摘要(原文)
We present VARGPT, a novel multimodal large language model (MLLM) that unifies visual understanding and generation within a single autoregressive framework. VARGPT employs a next-token prediction paradigm for visual understanding and a next-scale prediction paradigm for visual autoregressive generation. VARGPT innovatively extends the LLaVA architecture, achieving efficient scale-wise autoregressive visual generation within MLLMs while seamlessly accommodating mixed-modal input and output within a single model framework. Our VARGPT undergoes a three-stage unified training process on specially curated datasets, comprising a pre-training phase and two mixed visual instruction-tuning phases. The unified training strategy are designed to achieve alignment between visual and textual features, enhance instruction following for both understanding and generation, and improve visual generation quality, respectively. Despite its LLAVA-based architecture for multimodel understanding, VARGPT significantly outperforms LLaVA-1.5 across various vision-centric benchmarks, such as visual question-answering and reasoning tasks. Notably, VARGPT naturally supports capabilities in autoregressive visual generation and instruction-to-image synthesis, showcasing its versatility in both visual understanding and generation tasks. Project page is at: \url{https://vargpt-1.github.io/}