Memory Storyboard: Leveraging Temporal Segmentation for Streaming Self-Supervised Learning from Egocentric Videos
作者: Yanlai Yang, Mengye Ren
分类: cs.CV, cs.LG
发布日期: 2025-01-21 (更新: 2025-08-11)
备注: Fourth Conference on Lifelong Learning Agents - CoLLAs 2025 (Oral)
💡 一句话要点
提出Memory Storyboard,利用时序分割进行第一视角视频流的自监督学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 自监督学习 第一视角视频 时序分割 对比学习 持续学习 记忆回放 事件分割
📋 核心要点
- 现有自监督学习方法主要关注静态图像或人工数据流,难以直接应用于真实世界长时程第一视角视频流。
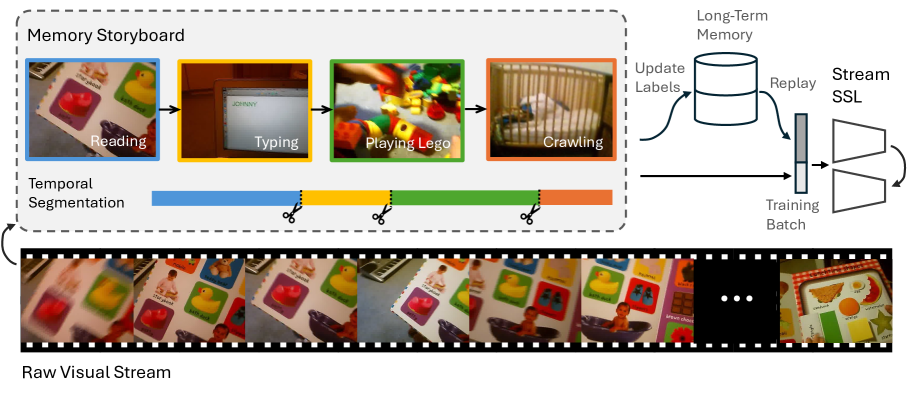
- 受人类记忆机制启发,提出Memory Storyboard,通过时序分割将视频帧分组,有效总结过去视觉信息。
- 实验表明,基于Memory Storyboard的对比学习方法在第一视角视频数据集上优于现有无监督持续学习方法。
📝 摘要(中文)
自监督学习有望从真实世界连续的、未经整理的数据流中学习到良好的表征。然而,现有的视觉自监督学习工作大多集中于静态图像或人工数据流。为了探索更真实的学习环境,我们研究了从长时程真实世界第一视角视频流中进行流式自监督学习。受到人类感知和记忆中的事件分割机制的启发,我们提出了“Memory Storyboard”,它将最近过去的帧分组为时间片段,以便更有效地总结过去的视觉流以进行记忆回放。为了适应高效的时间分割,我们提出了一个两层记忆层次结构:最近的过去存储在短期记忆中,然后将故事板时间片段转移到长期记忆中。在包括SAYCam和KrishnaCam在内的真实世界第一视角视频数据集上的实验表明,基于故事板帧的对比学习目标产生了语义上有意义的表征,优于最先进的无监督持续学习方法。
🔬 方法详解
问题定义:论文旨在解决从长时程、真实世界的第一视角视频流中进行自监督学习的问题。现有方法通常处理静态图像或人工数据流,无法有效处理连续、动态的视频数据,并且缺乏对时间信息的有效利用。这导致学习到的表征在语义理解方面表现不佳。
核心思路:论文的核心思路是模仿人类的记忆机制,特别是事件分割的概念。通过将视频流分割成多个时间片段(Storyboard),每个片段代表一个相对独立的事件或场景。这种分割能够更好地捕捉视频中的时间结构,并为自监督学习提供更有效的上下文信息。
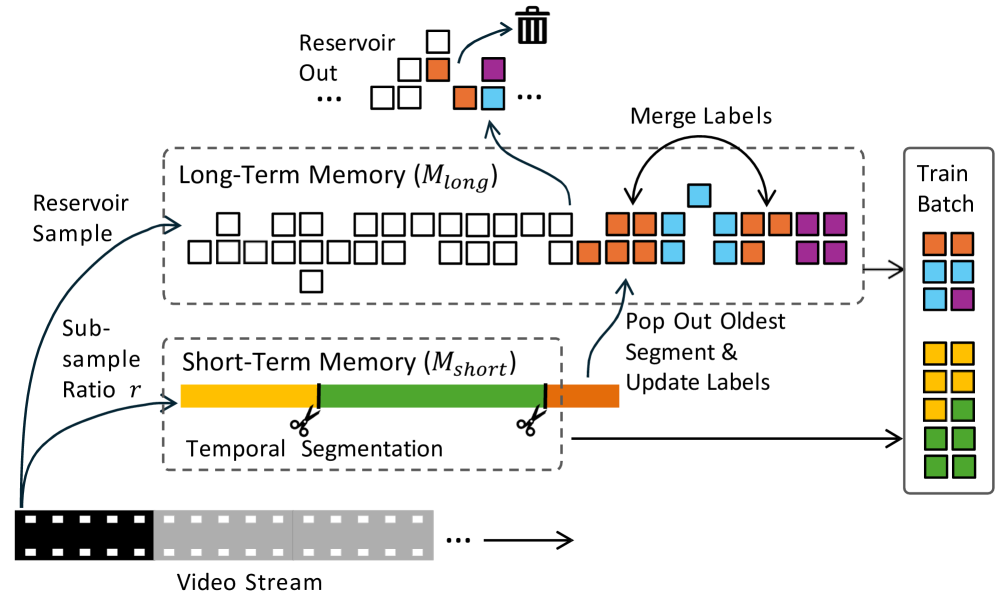
技术框架:整体框架包含两个主要模块:短期记忆和长期记忆。短期记忆用于存储最近的视频帧,长期记忆则存储通过时序分割得到的Storyboard片段。时序分割模块负责将短期记忆中的帧分组为有意义的片段,并将这些片段转移到长期记忆中。然后,在长期记忆中的Storyboard片段上应用对比学习目标,以学习视频的表征。
关键创新:关键创新在于Memory Storyboard的设计,它通过时序分割将视频流组织成更易于理解和学习的结构。与直接在原始视频帧上进行自监督学习相比,Storyboard能够更好地捕捉视频中的事件边界和语义信息。此外,两层记忆结构的设计也提高了学习效率,允许模型关注最近的过去,并同时利用长期记忆中的信息。
关键设计:时序分割模块的具体实现方式未知,论文可能使用了某种聚类算法或变化点检测方法。对比学习目标的选择也很重要,可能使用了InfoNCE或其他变体。此外,短期记忆和长期记忆的大小,以及Storyboard片段的长度等参数也需要仔细调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于Memory Storyboard的对比学习方法在SAYCam和KrishnaCam等真实世界第一视角视频数据集上,显著优于现有的无监督持续学习方法。具体性能数据未知,但论文强调了该方法能够学习到语义上有意义的表征。
🎯 应用场景
该研究成果可应用于机器人导航、智能助手、可穿戴设备等领域。通过学习第一视角视频流中的信息,机器人可以更好地理解周围环境,并做出更智能的决策。智能助手可以根据用户的日常活动进行个性化推荐和服务。可穿戴设备可以记录和分析用户的行为模式,提供健康建议。
📄 摘要(原文)
Self-supervised learning holds the promise of learning good representations from real-world continuous uncurated data streams. However, most existing works in visual self-supervised learning focus on static images or artificial data streams. Towards exploring a more realistic learning substrate, we investigate streaming self-supervised learning from long-form real-world egocentric video streams. Inspired by the event segmentation mechanism in human perception and memory, we propose "Memory Storyboard" that groups recent past frames into temporal segments for more effective summarization of the past visual streams for memory replay. To accommodate efficient temporal segmentation, we propose a two-tier memory hierarchy: the recent past is stored in a short-term memory, and the storyboard temporal segments are then transferred to a long-term memory. Experiments on real-world egocentric video datasets including SAYCam and KrishnaCam show that contrastive learning objectives on top of storyboard frames result in semantically meaningful representations that outperform those produced by state-of-the-art unsupervised continual learning methods.