ComposeAnyone: Controllable Layout-to-Human Generation with Decoupled Multimodal Conditions
作者: Shiyue Zhang, Zheng Chong, Xi Lu, Wenqing Zhang, Haoxiang Li, Xujie Zhang, Jiehui Huang, Xiao Dong, Xiaodan Liang
分类: cs.CV
发布日期: 2025-01-21
💡 一句话要点
ComposeAnyone:提出解耦多模态条件的可控布局到人体生成方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人体图像生成 扩散模型 多模态融合 布局控制 解耦控制
📋 核心要点
- 现有的人体图像生成方法缺乏灵活性和精确性,难以满足复杂需求,通常仅限于文本或图像参考。
- ComposeAnyone通过解耦多模态条件,允许用户使用文本或参考图像独立控制人体布局的各个部分。
- 实验结果表明,ComposeAnyone在人体图像生成方面,与布局、文本和参考图像的对齐效果更好,展现了多任务能力。
📝 摘要(中文)
本文提出ComposeAnyone,一种可控的布局到人体生成方法,该方法利用解耦的多模态条件。现有方法通常只关注文本到图像或基于图像参考的人体生成,无法满足日益复杂的需求。ComposeAnyone允许使用文本或参考图像对草绘人体布局中的任何部分进行解耦控制,并在生成过程中无缝集成它们。草绘布局使用颜色块几何形状(如椭圆和矩形),易于绘制,提供了一种更灵活和可访问的方式来定义空间布局。此外,本文还引入了ComposeHuman数据集,该数据集为每个人体图像的不同组件提供了解耦的文本和参考图像注释,从而在人体图像生成任务中实现更广泛的应用。大量实验表明,ComposeAnyone生成的人体图像与给定的布局、文本描述和参考图像更好地对齐,展示了其多任务能力和可控性。
🔬 方法详解
问题定义:现有的人体图像生成方法,如文本到图像生成或基于图像参考的生成,在控制的精细度和灵活性方面存在局限性。用户难以精确控制生成图像中特定部位的细节,也难以融合多种模态的信息进行指导。这限制了其在时尚设计等领域的应用。
核心思路:ComposeAnyone的核心思路是将人体布局作为生成过程的先验知识,并允许用户通过文本或参考图像对布局中的不同部分进行独立控制。通过解耦多模态条件,模型可以更好地理解用户的意图,并生成更符合用户期望的人体图像。
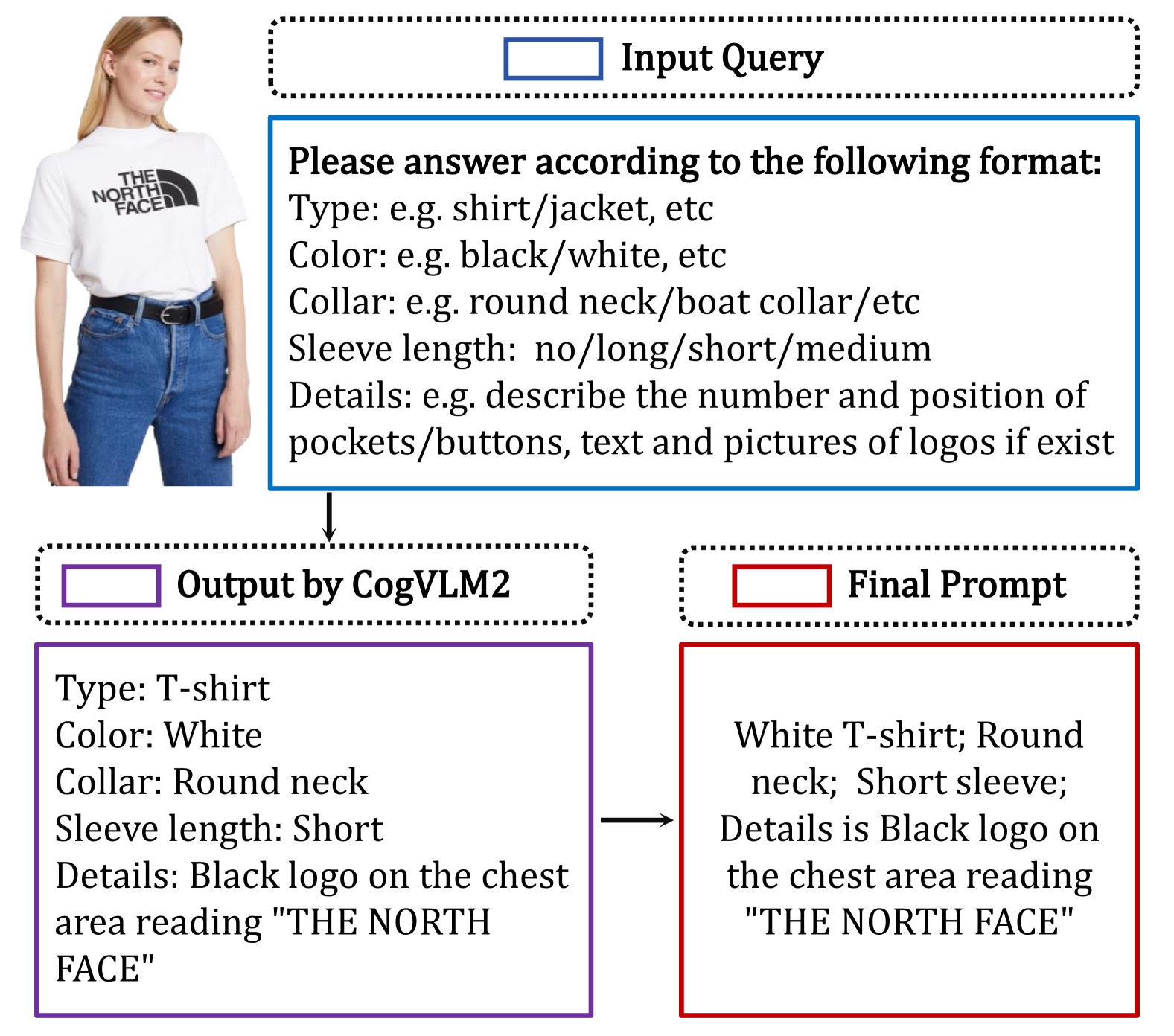
技术框架:ComposeAnyone的整体框架包含以下几个主要模块:1) 布局编码器:将手绘布局转换为特征表示。2) 多模态条件编码器:分别编码文本描述和参考图像,得到对应的特征表示。3) 解耦融合模块:将布局特征、文本特征和图像特征进行融合,实现对不同部位的独立控制。4) 扩散模型:基于融合后的特征,逐步生成人体图像。
关键创新:ComposeAnyone的关键创新在于解耦多模态条件控制。传统方法通常将所有条件信息混合在一起,难以实现精细控制。ComposeAnyone通过将文本和图像条件解耦,并将其与布局的不同部分进行关联,实现了对生成过程的更精确控制。此外,ComposeHuman数据集的构建也为该方法提供了数据支持。
关键设计:在布局编码器方面,使用了卷积神经网络提取布局特征。在多模态条件编码器方面,使用了预训练的文本编码器(如CLIP)和图像编码器(如ResNet)。在解耦融合模块方面,使用了注意力机制,将文本和图像特征与布局特征进行加权融合。在扩散模型方面,使用了U-Net结构,并引入了条件信息作为额外的输入。
🖼️ 关键图片


📊 实验亮点
ComposeAnyone在多个数据集上进行了实验,结果表明其生成的人体图像与给定的布局、文本描述和参考图像具有更好的对齐性。相较于现有方法,ComposeAnyone在生成质量和可控性方面均有显著提升。实验结果验证了ComposeAnyone的多任务能力和可控性。
🎯 应用场景
ComposeAnyone在时尚设计、虚拟试衣、游戏角色生成等领域具有广泛的应用前景。设计师可以使用该方法快速生成不同风格、不同姿势的人体图像,从而加速设计流程。用户可以通过上传自己的照片和文本描述,生成个性化的虚拟形象。该技术还可以用于创建游戏角色,并根据玩家的喜好进行定制。
📄 摘要(原文)
Building on the success of diffusion models, significant advancements have been made in multimodal image generation tasks. Among these, human image generation has emerged as a promising technique, offering the potential to revolutionize the fashion design process. However, existing methods often focus solely on text-to-image or image reference-based human generation, which fails to satisfy the increasingly sophisticated demands. To address the limitations of flexibility and precision in human generation, we introduce ComposeAnyone, a controllable layout-to-human generation method with decoupled multimodal conditions. Specifically, our method allows decoupled control of any part in hand-drawn human layouts using text or reference images, seamlessly integrating them during the generation process. The hand-drawn layout, which utilizes color-blocked geometric shapes such as ellipses and rectangles, can be easily drawn, offering a more flexible and accessible way to define spatial layouts. Additionally, we introduce the ComposeHuman dataset, which provides decoupled text and reference image annotations for different components of each human image, enabling broader applications in human image generation tasks. Extensive experiments on multiple datasets demonstrate that ComposeAnyone generates human images with better alignment to given layouts, text descriptions, and reference images, showcasing its multi-task capability and controllability.