Contrastive Masked Autoencoders for Character-Level Open-Set Writer Identification
作者: Xiaowei Jiang, Wenhao Ma, Yiqun Duan, Thomas Do, Chin-Teng Lin
分类: cs.CV, cs.LG
发布日期: 2025-01-21
DOI: 10.1109/SMC54092.2024.10831598
💡 一句话要点
提出CMAE模型,解决字符级开放集手写者身份识别问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 手写者身份识别 开放集学习 掩码自编码器 对比学习 表征学习
📋 核心要点
- 开放集手写者身份识别面临挑战,现有方法难以识别训练集中未出现过的作者。
- CMAE模型结合MAE和对比学习,提取序列信息并区分手写风格,提升泛化能力。
- 实验表明,CMAE在CASIA数据集上达到SOTA精度89.7%,验证了其有效性。
📝 摘要(中文)
本文提出了一种用于字符级开放集手写者身份识别的对比掩码自编码器(CMAE)。在数字取证和文档认证领域,手写者身份识别在确定文档作者方面起着关键作用,而主要的挑战在于“开放集场景”,即准确识别训练期间未见过的作者。为了克服这一挑战,表征学习至关重要。CMAE模型融合了掩码自编码器(MAE)和对比学习(CL),分别用于捕获序列信息和区分不同的手写风格。实验结果表明,该模型在CASIA在线手写数据集上达到了最先进(SOTA)的精度,达到了89.7%。这项研究通过一种复杂的表征学习方法推进了通用手写者身份识别,为不断发展的数字手写分析领域做出了重要贡献。
🔬 方法详解
问题定义:论文旨在解决开放集场景下的字符级手写者身份识别问题。现有方法在识别训练集中未出现过的作者时表现不佳,泛化能力有限。这是因为它们难以提取到具有区分性的、鲁棒的手写风格表征。
核心思路:论文的核心思路是结合掩码自编码器(MAE)和对比学习(CL)的优势,利用MAE捕获手写字符的序列信息,利用CL学习不同手写风格之间的区分性特征。通过这种方式,模型能够学习到更具泛化能力的表征,从而更好地识别未见过的作者。
技术框架:CMAE模型主要包含两个模块:掩码自编码器(MAE)和对比学习(CL)。首先,MAE对输入的手写字符图像进行掩码,然后利用自编码器重建被掩码的部分,从而学习字符的序列信息。其次,CL利用对比损失函数,将同一作者的手写字符拉近,不同作者的手写字符推远,从而学习区分性的手写风格表征。最后,将两个模块学习到的表征进行融合,用于手写者身份识别。
关键创新:CMAE的关键创新在于将MAE和CL结合起来,同时学习手写字符的序列信息和区分性特征。与传统的基于手工特征或深度学习的方法相比,CMAE能够自动学习到更具泛化能力的表征,从而更好地适应开放集场景。
关键设计:在MAE模块中,论文采用了随机掩码策略,即随机选择一部分字符进行掩码。在CL模块中,论文采用了InfoNCE损失函数,用于学习对比表征。此外,论文还采用了数据增强技术,如旋转、缩放等,以增加模型的鲁棒性。
🖼️ 关键图片
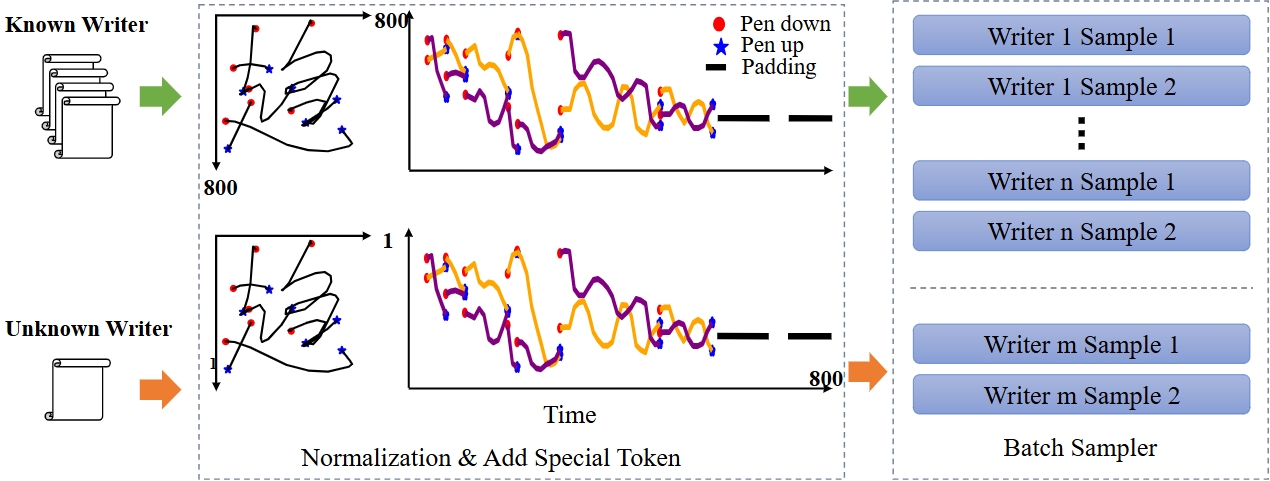
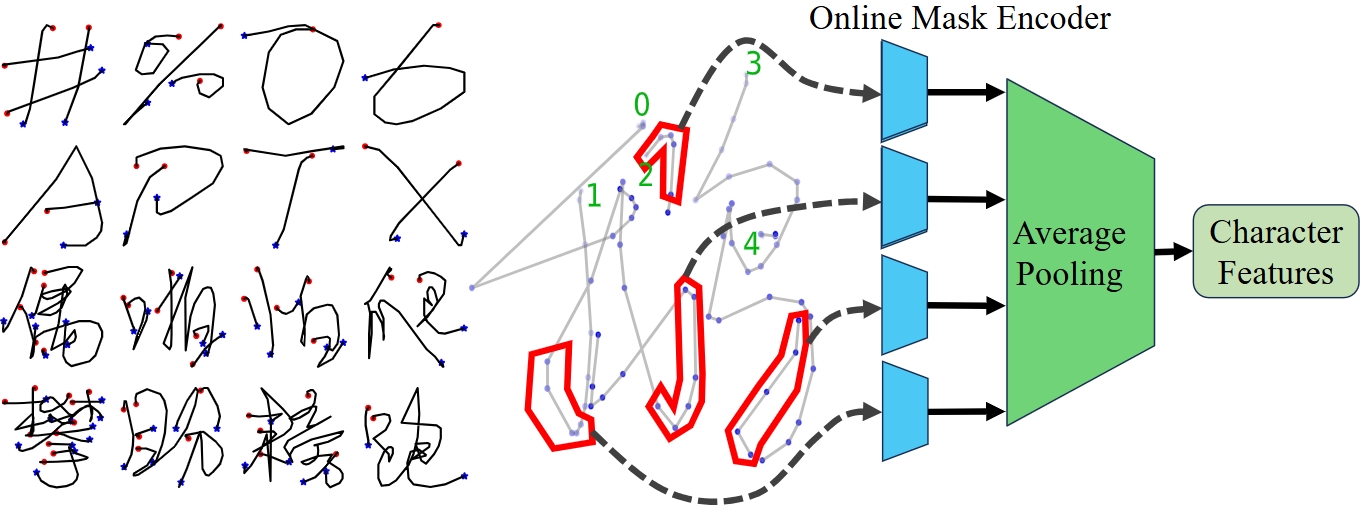
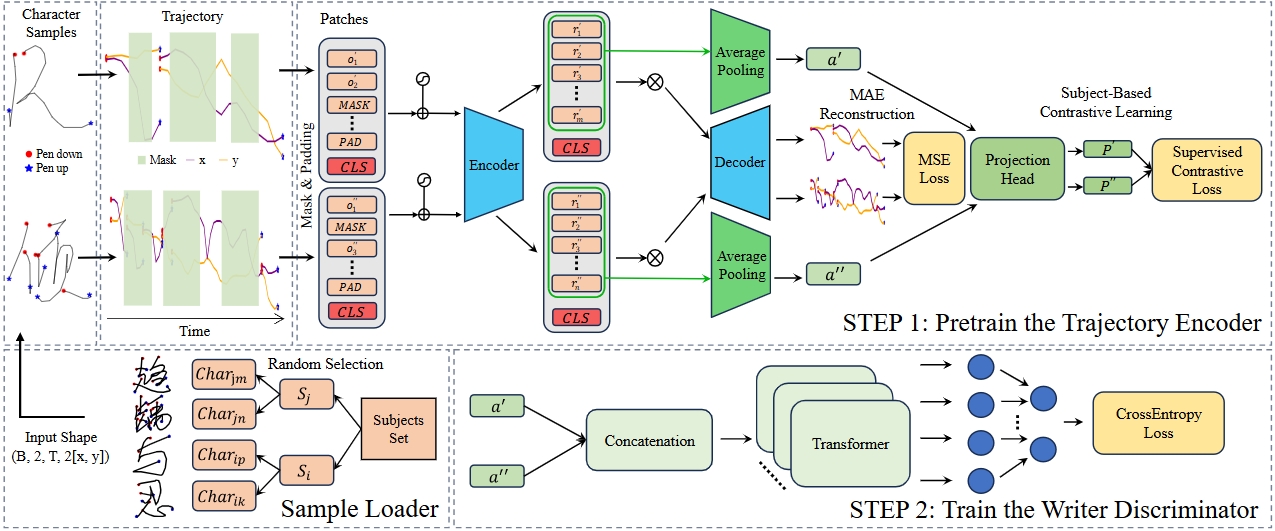
📊 实验亮点
CMAE模型在CASIA在线手写数据集上取得了显著的成果,精度达到了89.7%,超越了现有的SOTA方法。这一结果表明,CMAE模型能够有效地学习到具有区分性和泛化能力的手写风格表征,从而在开放集场景下实现准确的手写者身份识别。该模型在精度方面相比之前的最佳方法有显著提升。
🎯 应用场景
该研究成果可应用于数字取证、文档认证、笔迹分析等领域。例如,在法律领域,可以利用该技术鉴定匿名信件的作者;在金融领域,可以用于验证签名真伪;在教育领域,可以用于分析学生的书写习惯。随着数字化的普及,该技术在身份认证和安全领域具有广阔的应用前景。
📄 摘要(原文)
In the realm of digital forensics and document authentication, writer identification plays a crucial role in determining the authors of documents based on handwriting styles. The primary challenge in writer-id is the "open-set scenario", where the goal is accurately recognizing writers unseen during the model training. To overcome this challenge, representation learning is the key. This method can capture unique handwriting features, enabling it to recognize styles not previously encountered during training. Building on this concept, this paper introduces the Contrastive Masked Auto-Encoders (CMAE) for Character-level Open-Set Writer Identification. We merge Masked Auto-Encoders (MAE) with Contrastive Learning (CL) to simultaneously and respectively capture sequential information and distinguish diverse handwriting styles. Demonstrating its effectiveness, our model achieves state-of-the-art (SOTA) results on the CASIA online handwriting dataset, reaching an impressive precision rate of 89.7%. Our study advances universal writer-id with a sophisticated representation learning approach, contributing substantially to the ever-evolving landscape of digital handwriting analysis, and catering to the demands of an increasingly interconnected world.