Fast Underwater Scene Reconstruction using Multi-View Stereo and Physical Imaging
作者: Shuyi Hu, Qi Liu
分类: cs.CV
发布日期: 2025-01-21
💡 一句话要点
提出基于物理成像的水下多视图立体快速重建方法,提升重建质量与效率。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 水下场景重建 多视图立体 物理成像模型 神经渲染 深度估计
📋 核心要点
- 水下场景重建受散射和吸收影响,传统NeRF方法训练和渲染速度慢。
- 结合多视图立体和物理成像模型,分别进行深度估计和基于物理的渲染。
- 无需深度真值,通过介质子网估计介质参数,恢复真实颜色,提升几何保真度。
📝 摘要(中文)
水下场景重建面临光线与介质复杂相互作用的挑战,散射和吸收效应增加了深度估计和渲染的难度。虽然最近基于神经辐射场(NeRF)的水下场景方法通过建模和分离散射介质实现了高质量的结果,但训练和渲染速度仍然很慢。为了解决这些限制,我们提出了一种新方法,该方法将多视图立体(MVS)与基于物理的水下图像形成模型相结合。我们的方法包括两个分支:一个用于使用MVS的传统代价体流程进行深度估计,另一个用于基于基于物理的图像形成模型进行渲染。深度分支改善了场景几何结构,而介质分支确定散射参数以实现精确的场景渲染。与依赖于真实深度值的传统MVSNet方法不同,我们的方法不需要使用深度真值,从而加快了训练和渲染过程。通过利用介质子网来估计介质参数,并将其与用于渲染的颜色MLP相结合,我们恢复了水下场景的真实颜色,并实现了更高保真度的几何表示。实验结果表明,我们的方法能够高质量地合成散射介质中的新视角,通过去除介质来清晰地恢复视图,并且在渲染质量和训练效率方面优于现有方法。
🔬 方法详解
问题定义:水下场景重建由于光线在水中的散射和吸收效应,导致深度估计和渲染变得非常困难。现有的基于NeRF的方法虽然能取得较好的重建效果,但是训练和渲染速度慢,难以满足实际应用的需求。
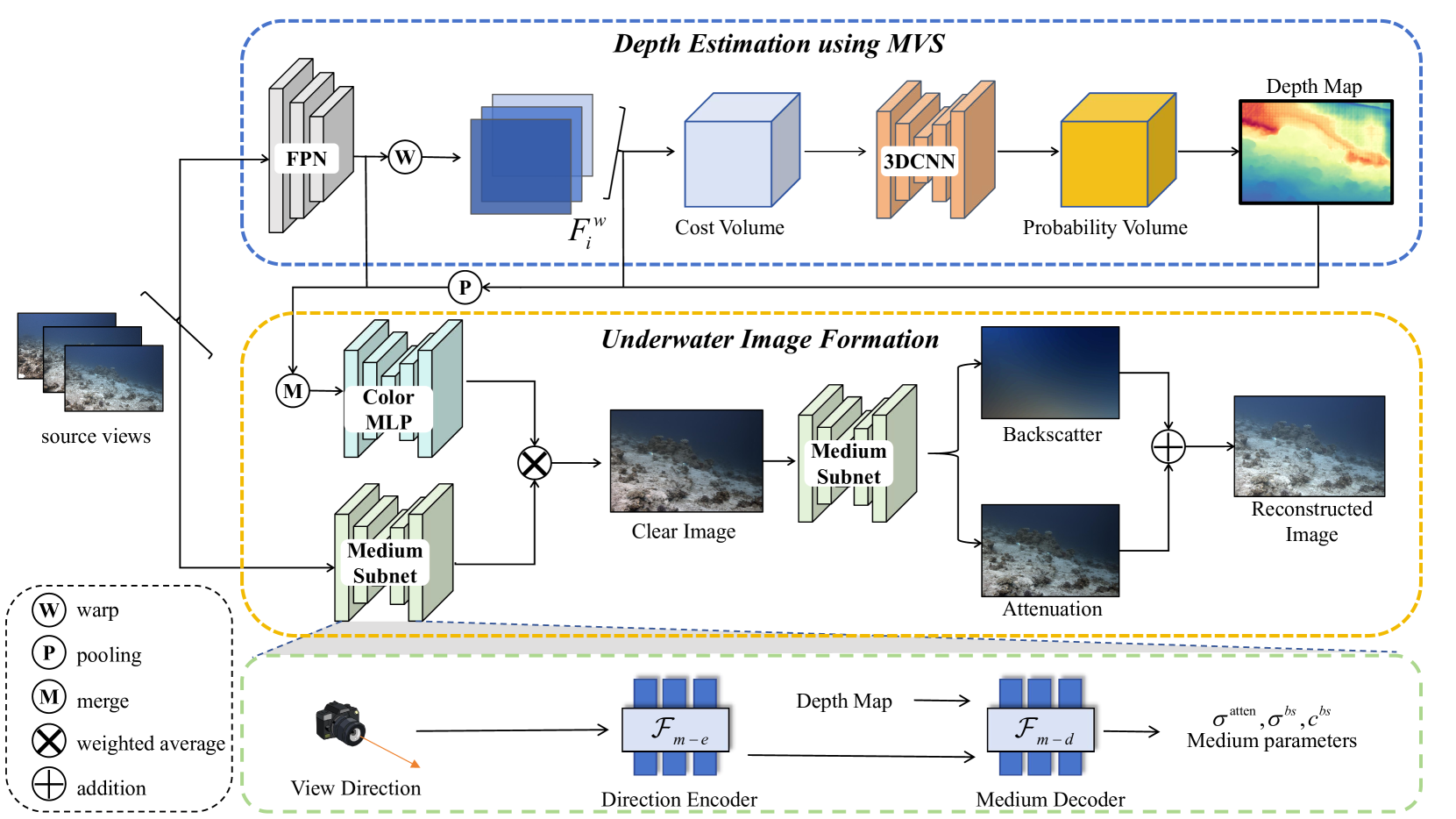
核心思路:论文的核心思路是将传统的多视图立体(MVS)方法与基于物理的水下图像形成模型相结合。MVS用于快速估计场景的几何结构,而物理模型用于精确地建模水下光线的传播过程,从而实现高质量的渲染。这种结合既能保证重建的精度,又能提高重建的速度。
技术框架:该方法包含两个主要分支:深度估计分支和渲染分支。深度估计分支采用传统的MVS代价体流程,用于估计场景的深度信息。渲染分支基于物理的水下图像形成模型,利用估计的深度信息和介质参数,进行场景的渲染。这两个分支相互协作,共同完成水下场景的重建。
关键创新:该方法最重要的创新点在于不需要ground-truth深度信息进行训练。传统的MVSNet方法通常需要大量的深度真值数据进行监督学习,而该方法通过结合物理模型,可以实现自监督的训练。此外,利用介质子网估计介质参数,并结合颜色MLP进行渲染,能够更准确地恢复水下场景的真实颜色。
关键设计:介质子网用于估计水下介质的散射和吸收系数等参数。颜色MLP用于将深度信息和介质参数映射到最终的颜色值。损失函数的设计需要同时考虑深度估计的准确性和渲染结果的真实性。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在渲染质量和训练效率方面均优于现有方法。该方法能够高质量地合成散射介质中的新视角,并通过去除介质来清晰地恢复视图。与传统的MVSNet方法相比,该方法不需要深度真值数据,从而大大缩短了训练时间。具体的性能数据和对比结果在论文中有详细展示。
🎯 应用场景
该研究成果可应用于水下机器人导航、水下考古、海洋生物研究、水下环境监测等领域。通过快速准确地重建水下场景,可以帮助人们更好地了解和探索水下世界,具有重要的科学价值和实际应用前景。未来,该技术有望进一步推广到其他散射介质环境的重建中。
📄 摘要(原文)
Underwater scene reconstruction poses a substantial challenge because of the intricate interplay between light and the medium, resulting in scattering and absorption effects that make both depth estimation and rendering more complex. While recent Neural Radiance Fields (NeRF) based methods for underwater scenes achieve high-quality results by modeling and separating the scattering medium, they still suffer from slow training and rendering speeds. To address these limitations, we propose a novel method that integrates Multi-View Stereo (MVS) with a physics-based underwater image formation model. Our approach consists of two branches: one for depth estimation using the traditional cost volume pipeline of MVS, and the other for rendering based on the physics-based image formation model. The depth branch improves scene geometry, while the medium branch determines the scattering parameters to achieve precise scene rendering. Unlike traditional MVSNet methods that rely on ground-truth depth, our method does not necessitate the use of depth truth, thus allowing for expedited training and rendering processes. By leveraging the medium subnet to estimate the medium parameters and combining this with a color MLP for rendering, we restore the true colors of underwater scenes and achieve higher-fidelity geometric representations. Experimental results show that our method enables high-quality synthesis of novel views in scattering media, clear views restoration by removing the medium, and outperforms existing methods in rendering quality and training efficiency.