Eagle 2: Building Post-Training Data Strategies from Scratch for Frontier Vision-Language Models
作者: Zhiqi Li, Guo Chen, Shilong Liu, Shihao Wang, Vibashan VS, Yishen Ji, Shiyi Lan, Hao Zhang, Yilin Zhao, Subhashree Radhakrishnan, Nadine Chang, Karan Sapra, Amala Sanjay Deshmukh, Tuomas Rintamaki, Matthieu Le, Ilia Karmanov, Lukas Voegtle, Philipp Fischer, De-An Huang, Timo Roman, Tong Lu, Jose M. Alvarez, Bryan Catanzaro, Jan Kautz, Andrew Tao, Guilin Liu, Zhiding Yu
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-01-20
💡 一句话要点
Eagle2:从零构建后训练数据策略,提升前沿视觉-语言模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 后训练 数据策略 多模态学习 开源模型
📋 核心要点
- 开源VLM模型性能与闭源模型仍有差距,且训练数据策略细节通常不公开。
- 论文核心在于从数据角度出发,设计有效的后训练数据策略,提升VLM性能。
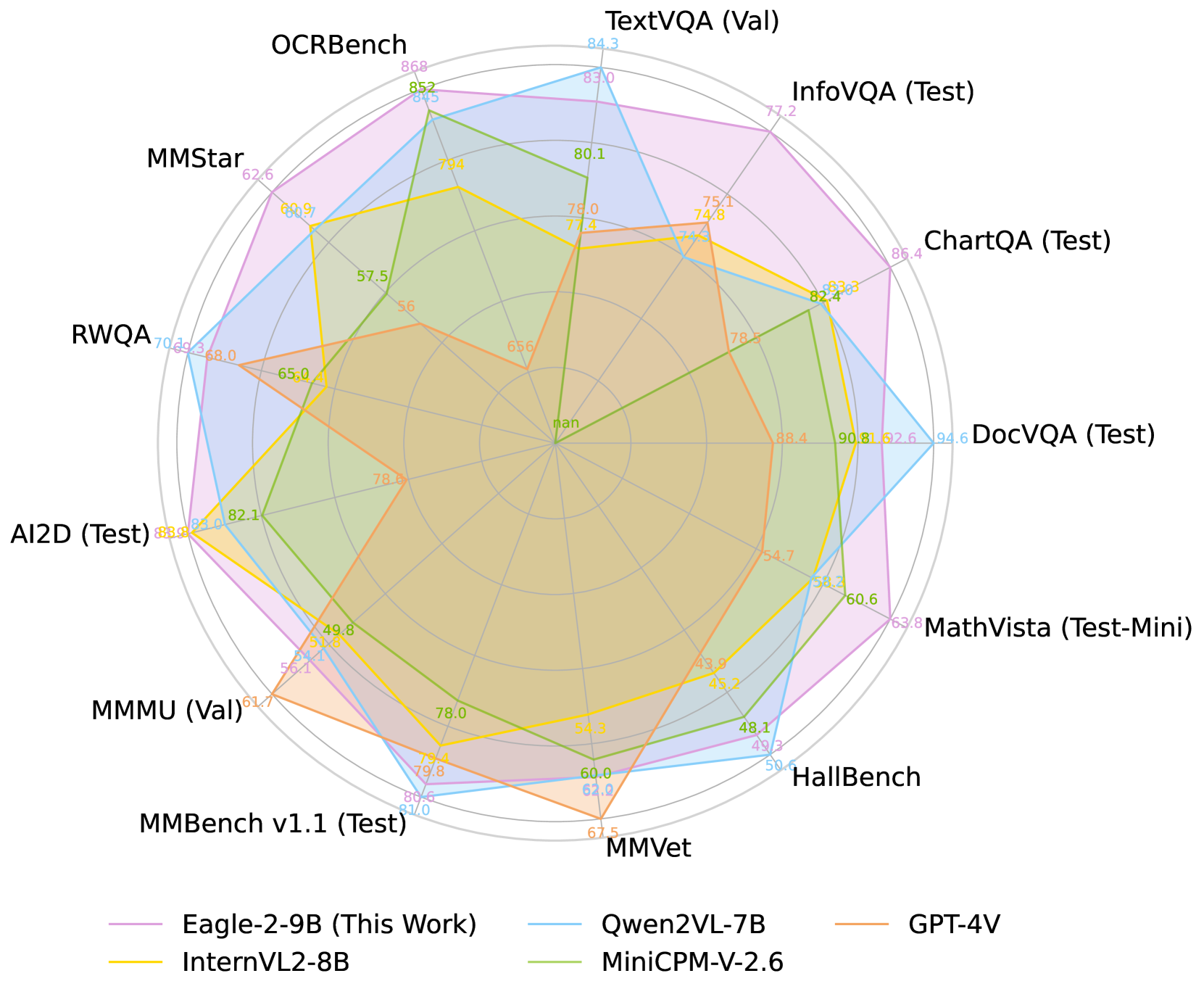
- 提出的Eagle2系列模型在多项多模态benchmark上达到SOTA,性能媲美70B参数模型。
📝 摘要(中文)
近年来,开源视觉-语言模型(VLM)在能力上取得了显著进展,逐渐逼近专有前沿模型。然而,大多数开源模型仅发布最终模型权重,而数据策略和实现的关键细节在很大程度上是不透明的。本文从数据中心角度研究VLM的后训练,展示了数据策略在开发前沿VLM中的关键作用。通过从零开始研究和构建我们的后训练数据策略,我们分享了开发过程的详细见解,旨在促进开源社区中具有竞争力的模型的发展。我们提出的数据策略,结合训练方法和模型设计,产生了一系列高性能的VLM,名为Eagle2。具体而言,Eagle2-9B在各种多模态基准测试中取得了最先进的结果,与某些高达70B参数的竞争模型相媲美。
🔬 方法详解
问题定义:现有开源视觉-语言模型(VLM)虽然在性能上有所提升,但与闭源前沿模型相比仍存在差距。一个关键问题是,开源模型通常只发布最终的模型权重,而用于训练这些模型的关键数据策略和实现细节却鲜为人知。这使得开源社区难以复现和进一步改进这些模型,阻碍了开源VLM的发展。
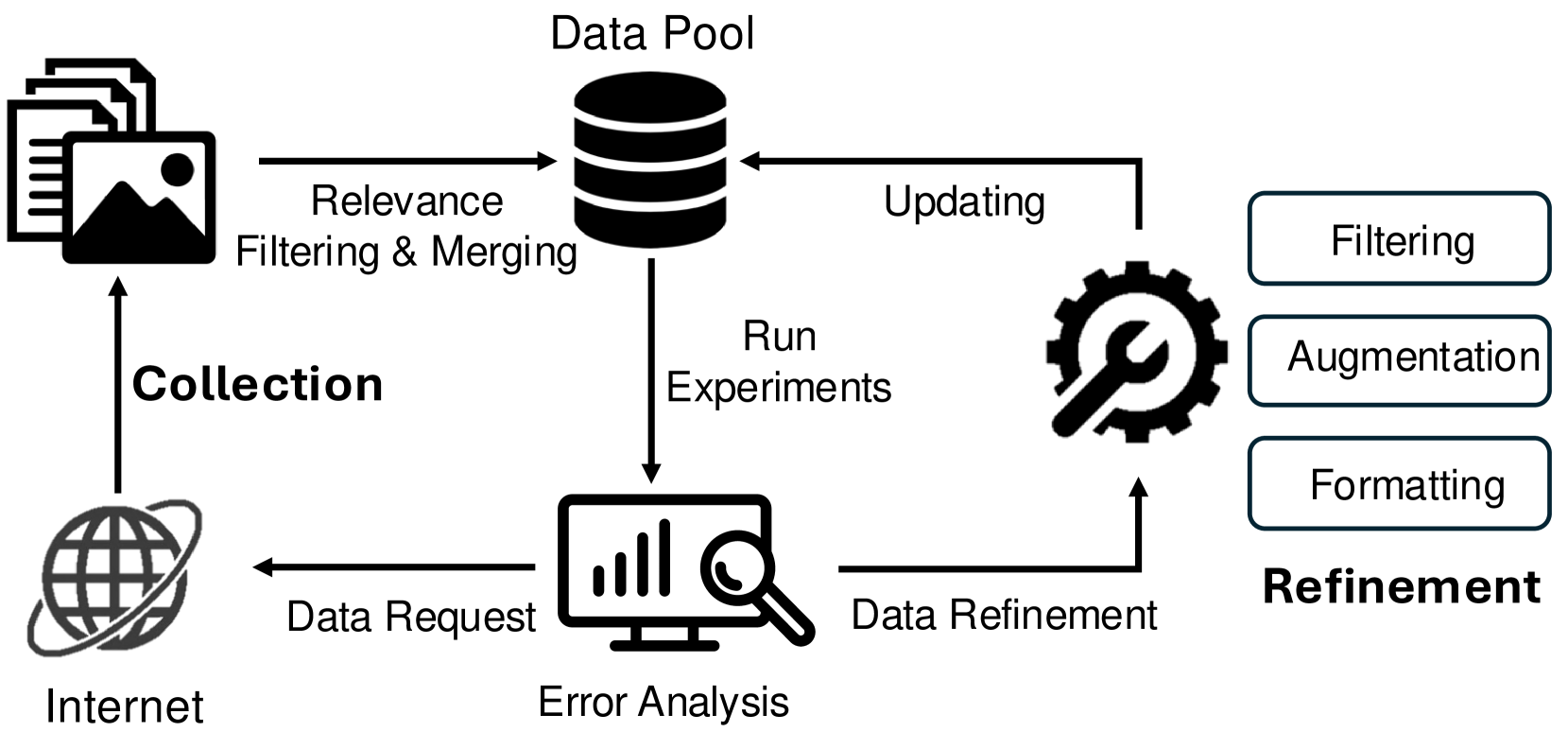
核心思路:本文的核心思路是从数据角度出发,强调数据策略在VLM后训练中的重要性。作者认为,精心设计的后训练数据策略可以显著提升VLM的性能,使其能够与更大规模的闭源模型相媲美。因此,他们致力于从零开始构建一套有效的后训练数据策略,并公开其详细的设计和实现过程。
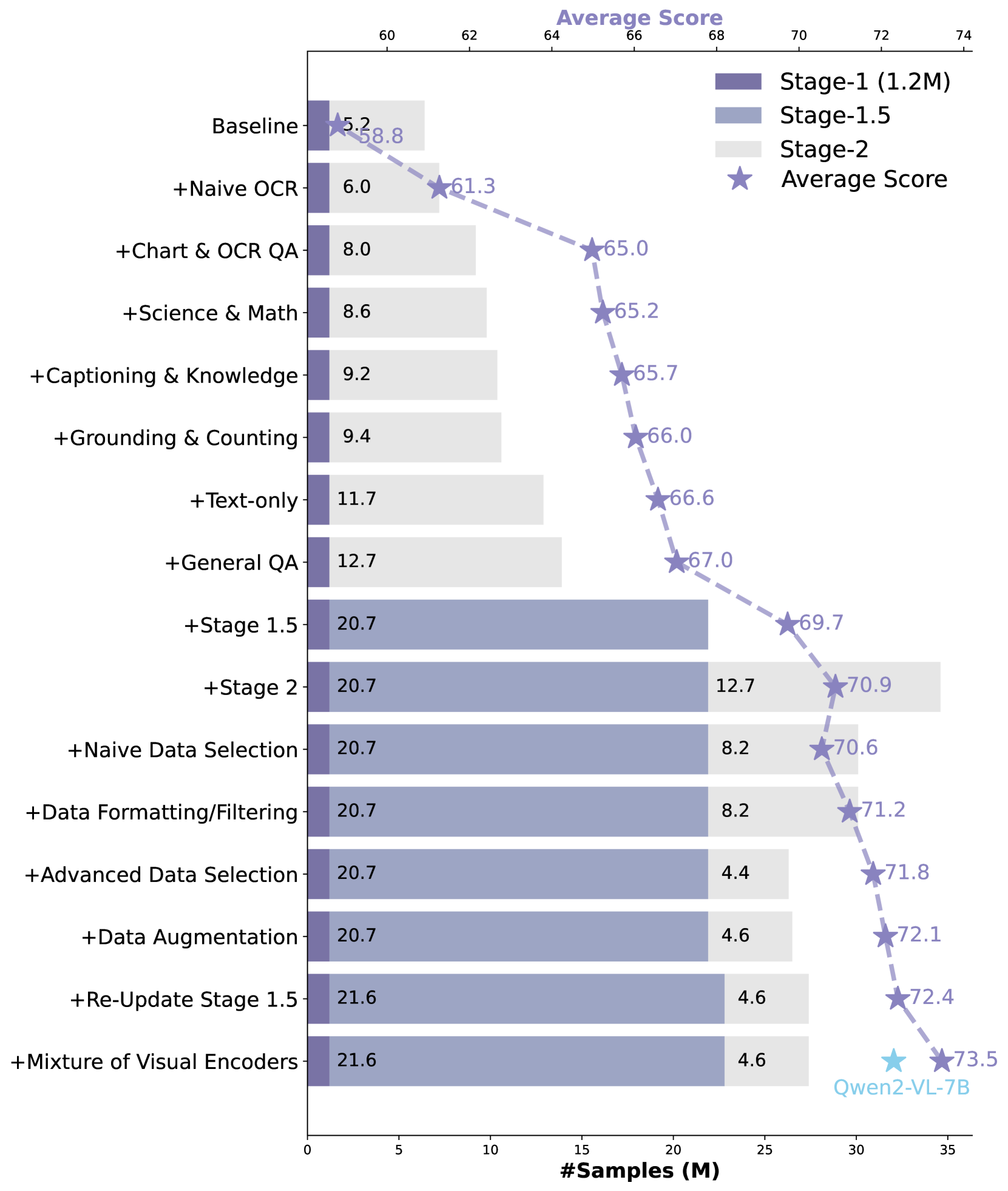
技术框架:Eagle2的技术框架主要包括以下几个关键部分:首先是模型设计,选择合适的模型架构作为基础。其次是构建后训练数据策略,这包括数据收集、数据清洗、数据增强和数据选择等步骤。然后是训练方法,包括损失函数的设计、优化器的选择和训练参数的调整。最后是模型评估,使用各种多模态benchmark来评估模型的性能。
关键创新:本文最重要的技术创新点在于其从零开始构建的后训练数据策略。与以往的研究不同,本文没有直接使用现有的数据集或数据增强方法,而是深入分析了VLM的训练过程,并根据模型的特点和任务的需求,设计了一套定制化的数据策略。这种数据策略能够有效地提升模型的性能,使其在各种多模态benchmark上取得最先进的结果。
关键设计:具体的数据策略设计细节未知,但可以推测可能包括以下几个方面:1) 数据选择:选择哪些数据进行后训练,例如,选择更具有挑战性的样本或更符合模型目标任务的样本。2) 数据增强:如何对数据进行增强,例如,使用图像变换、文本改写或生成对抗网络等方法来增加数据的多样性。3) 数据混合:如何将不同的数据集混合在一起,例如,使用不同的权重或采样策略来平衡不同数据集的影响。
🖼️ 关键图片
📊 实验亮点
Eagle2-9B模型在多个多模态benchmark上取得了state-of-the-art的结果,性能与参数量高达70B的竞争模型相当。这表明,通过精心设计的数据策略,可以在较小模型上实现与大规模模型相媲美的性能,具有重要的实际意义。
🎯 应用场景
该研究成果可应用于各种需要视觉和语言理解能力的场景,例如智能客服、图像搜索、视频分析、机器人导航等。通过开源Eagle2模型和数据策略,可以促进开源社区在VLM领域的发展,加速相关技术的落地应用,并降低开发成本。
📄 摘要(原文)
Recently, promising progress has been made by open-source vision-language models (VLMs) in bringing their capabilities closer to those of proprietary frontier models. However, most open-source models only publish their final model weights, leaving the critical details of data strategies and implementation largely opaque. In this work, we address VLM post-training from a data-centric perspective, showing the key role of data strategy in developing frontier VLMs. By studying and building our post-training data strategy from scratch, we share detailed insights into the development processes, aiming to benefit the development of competitive models for the open-source community. Our introduced data strategy, together with training recipes and model design, leads to a family of performant VLMs named Eagle2. Specifically, Eagle2-9B achieves state-of-the-art results across various multimodal benchmarks, matching certain competitive models with up to 70B parameters.