Teaching Large Language Models to Regress Accurate Image Quality Scores using Score Distribution
作者: Zhiyuan You, Xin Cai, Jinjin Gu, Tianfan Xue, Chao Dong
分类: cs.CV
发布日期: 2025-01-20 (更新: 2025-11-27)
备注: Accepted by CVPR 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出DeQA-Score模型,利用大语言模型回归精确的图像质量评分,并解决数据集差异问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像质量评估 多模态大语言模型 分数回归 分布学习 保真度损失 Thurstone模型 跨数据集学习
📋 核心要点
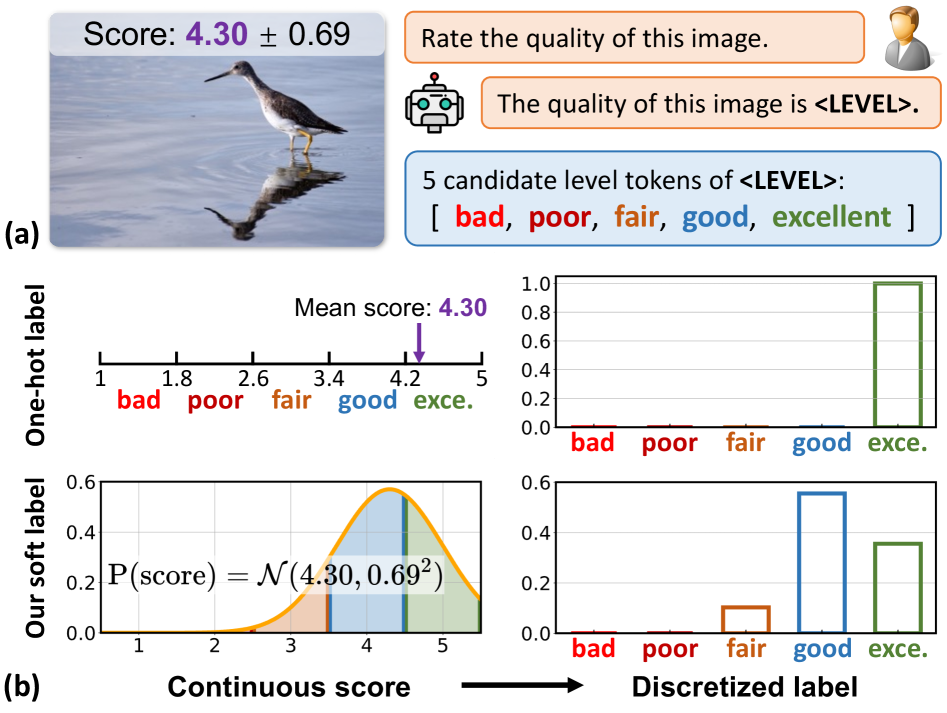
- 现有基于MLLM的图像质量评估方法在准确评分方面存在不足,主要原因是连续的质量分数与MLLM离散的token输出不匹配。
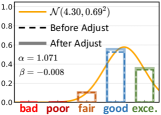
- 论文提出一种基于分布的方法,将质量分数分布离散化为软标签,保留分数分布的特征,从而提高评分精度并保持图像间的关系。
- 引入基于Thurstone模型的保真度损失,解决不同IQA数据集分布差异问题,促进跨数据集的联合训练,提升模型泛化能力。
📝 摘要(中文)
随着多模态大语言模型(MLLM)的快速发展,基于MLLM的图像质量评估(IQA)方法在语言质量描述方面表现出良好的性能。然而,目前的方法在准确评估图像质量方面仍然存在不足。本文旨在利用MLLM回归精确的质量分数。一个关键的挑战是质量分数本质上是连续的,通常被建模为高斯分布,而MLLM生成离散的token输出。这种不匹配需要对分数进行离散化。以往的方法将平均分数离散化为one-hot标签,导致信息丢失,无法捕捉图像间的关系。我们提出了一种基于分布的方法,将分数分布离散化为软标签。该方法保留了分数分布的特征,实现了高精度,并保持了图像间的关系。此外,为了解决数据集差异问题,即不同的IQA数据集表现出不同的分布,我们引入了一种基于Thurstone模型的保真度损失。这种损失捕捉了数据集内的关系,促进了跨多个IQA数据集的联合训练。基于这些设计,我们开发了用于分数回归的基于分布的图像质量评估模型(DeQA-Score)。在多个基准测试上的实验表明,DeQA-Score在分数回归方面稳定地优于基线方法。此外,DeQA-Score可以预测与人类标注紧密对齐的分数分布。代码和模型权重已在https://depictqa.github.io/deqa-score/发布。
🔬 方法详解
问题定义:现有基于多模态大语言模型(MLLM)的图像质量评估(IQA)方法,在将连续的图像质量分数映射到离散的token输出时,通常采用将平均分数离散化为one-hot标签的方法。这种方法会造成信息损失,无法捕捉图像之间的相对质量关系,并且忽略了质量评分的分布特性。此外,不同的IQA数据集具有不同的分数分布,直接混合训练会导致模型性能下降。
核心思路:论文的核心思路是将连续的图像质量分数分布进行离散化,生成软标签,而不是简单的one-hot标签。通过保留分数分布的特征,模型可以更好地学习图像之间的相对质量关系。同时,引入保真度损失,使得模型能够适应不同IQA数据集的分布差异,从而实现跨数据集的联合训练。
技术框架:DeQA-Score模型主要包含以下几个阶段:1)图像特征提取:使用预训练的视觉模型提取图像特征。2)文本提示构建:构建包含图像描述和质量评估任务的文本提示。3)多模态融合:将图像特征和文本提示输入到多模态大语言模型中进行融合。4)分数分布预测:MLLM输出离散的token序列,通过线性层映射到离散化的分数分布。5)损失函数计算:计算预测分数分布与真实分数分布之间的交叉熵损失,以及保真度损失。
关键创新:论文的关键创新在于:1)使用软标签表示图像质量分数分布,保留了更多的信息,提高了评分精度。2)引入保真度损失,解决了不同IQA数据集分布差异的问题,实现了跨数据集的联合训练。3)将Thurstone模型应用于IQA领域,用于建模数据集内的图像质量关系。
关键设计:1)分数分布离散化:将连续的质量分数范围划分为若干个离散的区间,每个区间对应一个token。2)保真度损失:基于Thurstone模型,计算数据集中图像对之间的相对质量差异,并与模型预测的相对质量差异进行比较,从而约束模型学习数据集内的图像质量关系。3)损失函数:总损失函数由交叉熵损失和保真度损失加权组成。权重系数用于平衡两个损失函数的重要性。
🖼️ 关键图片

📊 实验亮点
DeQA-Score模型在多个IQA基准测试中表现出优异的性能,显著优于现有的基于MLLM的IQA方法。实验结果表明,DeQA-Score能够更准确地预测图像质量分数,并且预测的分数分布与人类标注更加一致。此外,保真度损失的引入有效地提高了模型在跨数据集上的泛化能力。
🎯 应用场景
该研究成果可应用于各种需要图像质量评估的场景,例如图像增强、图像压缩、图像传输、图像检索等。通过准确评估图像质量,可以优化图像处理算法,提高用户体验,并为图像质量控制提供依据。未来,该方法可以扩展到视频质量评估领域,并应用于更广泛的多媒体应用中。
📄 摘要(原文)
With the rapid advancement of Multi-modal Large Language Models (MLLMs), MLLM-based Image Quality Assessment (IQA) methods have shown promising performance in linguistic quality description. However, current methods still fall short in accurately scoring image quality. In this work, we aim to leverage MLLMs to regress accurate quality scores. A key challenge is that the quality score is inherently continuous, typically modeled as a Gaussian distribution, whereas MLLMs generate discrete token outputs. This mismatch necessitates score discretization. Previous approaches discretize the mean score into a one-hot label, resulting in information loss and failing to capture inter-image relationships. We propose a distribution-based approach that discretizes the score distribution into a soft label. This method preserves the characteristics of the score distribution, achieving high accuracy and maintaining inter-image relationships. Moreover, to address dataset variation, where different IQA datasets exhibit various distributions, we introduce a fidelity loss based on Thurstone's model. This loss captures intra-dataset relationships, facilitating co-training across multiple IQA datasets. With these designs, we develop the distribution-based Depicted image Quality Assessment model for Score regression (DeQA-Score). Experiments across multiple benchmarks show that DeQA-Score stably outperforms baselines in score regression. Also, DeQA-Score can predict the score distribution that closely aligns with human annotations. Codes and model weights have been released in https://depictqa.github.io/deqa-score/.