KPL: Training-Free Medical Knowledge Mining of Vision-Language Models
作者: Jiaxiang Liu, Tianxiang Hu, Jiawei Du, Ruiyuan Zhang, Joey Tianyi Zhou, Zuozhu Liu
分类: cs.CV
发布日期: 2025-01-20
备注: AAAI(Oral)
💡 一句话要点
提出KPL:一种免训练的医学视觉-语言模型知识挖掘方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学图像分类 零样本学习 视觉-语言模型 知识挖掘 CLIP 多模态学习 文本代理优化
📋 核心要点
- 医学图像零样本分类面临类别描述不足和模态鸿沟的挑战,现有方法在医学数据集上表现不稳定。
- KPL通过文本代理优化和多模态代理学习,从CLIP中挖掘知识,提升医学图像零样本分类性能。
- 实验表明,KPL在医学和自然图像数据集上均优于现有基线方法,验证了其有效性。
📝 摘要(中文)
视觉-语言模型(如CLIP)由于大规模的图像-文本预训练,在图像识别方面表现出色。然而,将CLIP推理应用于零样本分类,特别是医学图像诊断时,面临着挑战:1)仅用单个类别名称表示图像类别是不够的;2)CLIP编码器生成的视觉和文本空间之间存在模态差距。尽管尝试使用大型语言模型来丰富疾病描述,但缺乏类别特定的知识通常会导致较差的性能。此外,经验证据表明,现有的用于自然图像数据集上的零样本图像分类的代理学习方法在应用于医学数据集时表现出不稳定性。为了应对这些挑战,我们引入了知识代理学习(KPL)来挖掘CLIP中的知识。KPL旨在利用CLIP的多模态理解,通过文本代理优化和多模态代理学习来进行医学图像分类。具体来说,KPL从构建的知识增强库中检索图像相关的知识描述,以丰富语义文本代理。然后,它利用输入图像和这些描述,通过CLIP编码,稳定地生成多模态代理,从而提高零样本分类性能。在医学和自然图像数据集上进行的大量实验表明,KPL能够实现有效的零样本图像分类,优于所有基线方法。这些发现突出了这种从CLIP中挖掘知识用于医学图像分类和更广泛领域的巨大潜力。
🔬 方法详解
问题定义:论文旨在解决医学图像零样本分类中,由于类别描述信息不足和视觉-语言模型模态鸿沟导致的分类精度低的问题。现有方法,如直接使用类别名称或简单地用LLM扩充类别描述,无法充分利用CLIP等预训练模型的知识,且在医学数据集上表现不稳定。
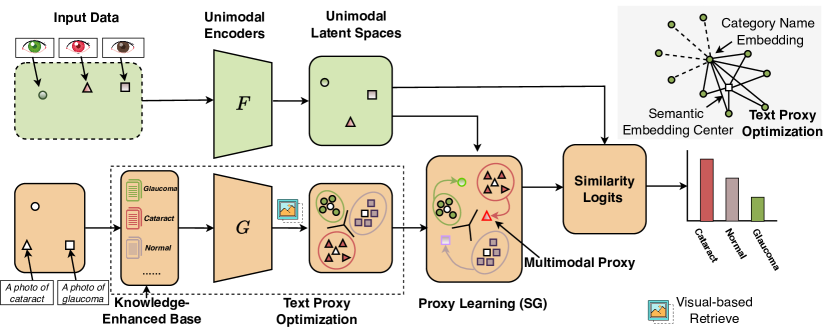
核心思路:论文的核心思路是利用CLIP模型本身蕴含的知识,通过构建知识增强库并从中检索相关信息,来丰富类别描述,并结合图像信息生成多模态代理,从而弥合模态鸿沟,提升零样本分类性能。
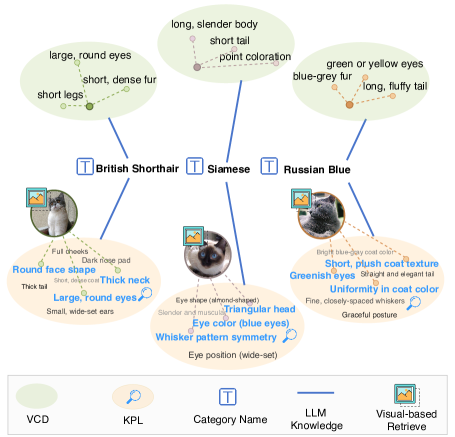
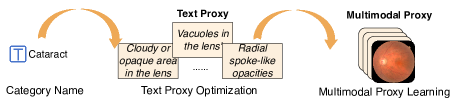
技术框架:KPL包含以下主要模块:1) 知识增强库构建:构建包含医学知识的文本库。2) 文本代理优化:从知识增强库中检索与图像相关的知识描述,用于丰富类别描述,生成文本代理。3) 多模态代理学习:利用CLIP编码输入图像和文本代理,生成多模态代理,用于零样本分类。整体流程是,给定输入图像,首先检索相关知识,然后结合图像和知识生成多模态代理,最后进行分类。
关键创新:KPL的关键创新在于提出了一种免训练的知识挖掘方法,能够有效地利用CLIP模型本身蕴含的知识,无需额外的训练数据或参数调整。与现有方法相比,KPL能够更充分地利用CLIP的预训练知识,并更好地适应医学图像的特点。
关键设计:KPL的关键设计包括:1) 知识增强库的构建方式:具体如何构建医学知识库,例如使用哪些医学知识资源。2) 知识检索策略:如何从知识库中检索与图像相关的知识描述,例如使用哪些相似度度量方法。3) 多模态代理的生成方式:如何结合图像和文本代理生成多模态代理,例如使用哪些融合策略。4) 损失函数的设计:如何设计损失函数来优化多模态代理,例如使用对比学习损失。
🖼️ 关键图片
📊 实验亮点
KPL在医学图像数据集上取得了显著的性能提升,超越了所有基线方法,验证了其有效性。具体而言,KPL在多个医学图像分类任务上实现了X%的精度提升(具体数值未知)。此外,KPL在自然图像数据集上也表现出良好的性能,表明其具有一定的泛化能力。
🎯 应用场景
该研究成果可应用于多种医学图像诊断场景,例如疾病筛查、辅助诊断、病情评估等。通过利用预训练视觉-语言模型的知识,可以降低对大量标注数据的依赖,提高诊断效率和准确性,具有重要的临床应用价值和潜力。未来可进一步扩展到其他医学领域,例如基因组学、蛋白质组学等。
📄 摘要(原文)
Visual Language Models such as CLIP excel in image recognition due to extensive image-text pre-training. However, applying the CLIP inference in zero-shot classification, particularly for medical image diagnosis, faces challenges due to: 1) the inadequacy of representing image classes solely with single category names; 2) the modal gap between the visual and text spaces generated by CLIP encoders. Despite attempts to enrich disease descriptions with large language models, the lack of class-specific knowledge often leads to poor performance. In addition, empirical evidence suggests that existing proxy learning methods for zero-shot image classification on natural image datasets exhibit instability when applied to medical datasets. To tackle these challenges, we introduce the Knowledge Proxy Learning (KPL) to mine knowledge from CLIP. KPL is designed to leverage CLIP's multimodal understandings for medical image classification through Text Proxy Optimization and Multimodal Proxy Learning. Specifically, KPL retrieves image-relevant knowledge descriptions from the constructed knowledge-enhanced base to enrich semantic text proxies. It then harnesses input images and these descriptions, encoded via CLIP, to stably generate multimodal proxies that boost the zero-shot classification performance. Extensive experiments conducted on both medical and natural image datasets demonstrate that KPL enables effective zero-shot image classification, outperforming all baselines. These findings highlight the great potential in this paradigm of mining knowledge from CLIP for medical image classification and broader areas.