Visual RAG: Expanding MLLM visual knowledge without fine-tuning
作者: Mirco Bonomo, Simone Bianco
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-01-18
💡 一句话要点
提出Visual RAG,无需微调即可扩展MLLM的视觉知识
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉检索增强生成 多模态大语言模型 上下文学习 图像分类 零样本学习
📋 核心要点
- 现有MLLM依赖大量演示示例进行上下文学习,且上下文窗口有限,限制了其在新任务和领域的泛化能力。
- Visual RAG通过检索与查询相关的少量演示示例来增强MLLM的知识,使其能够通过类比学习,无需微调即可适应新任务。
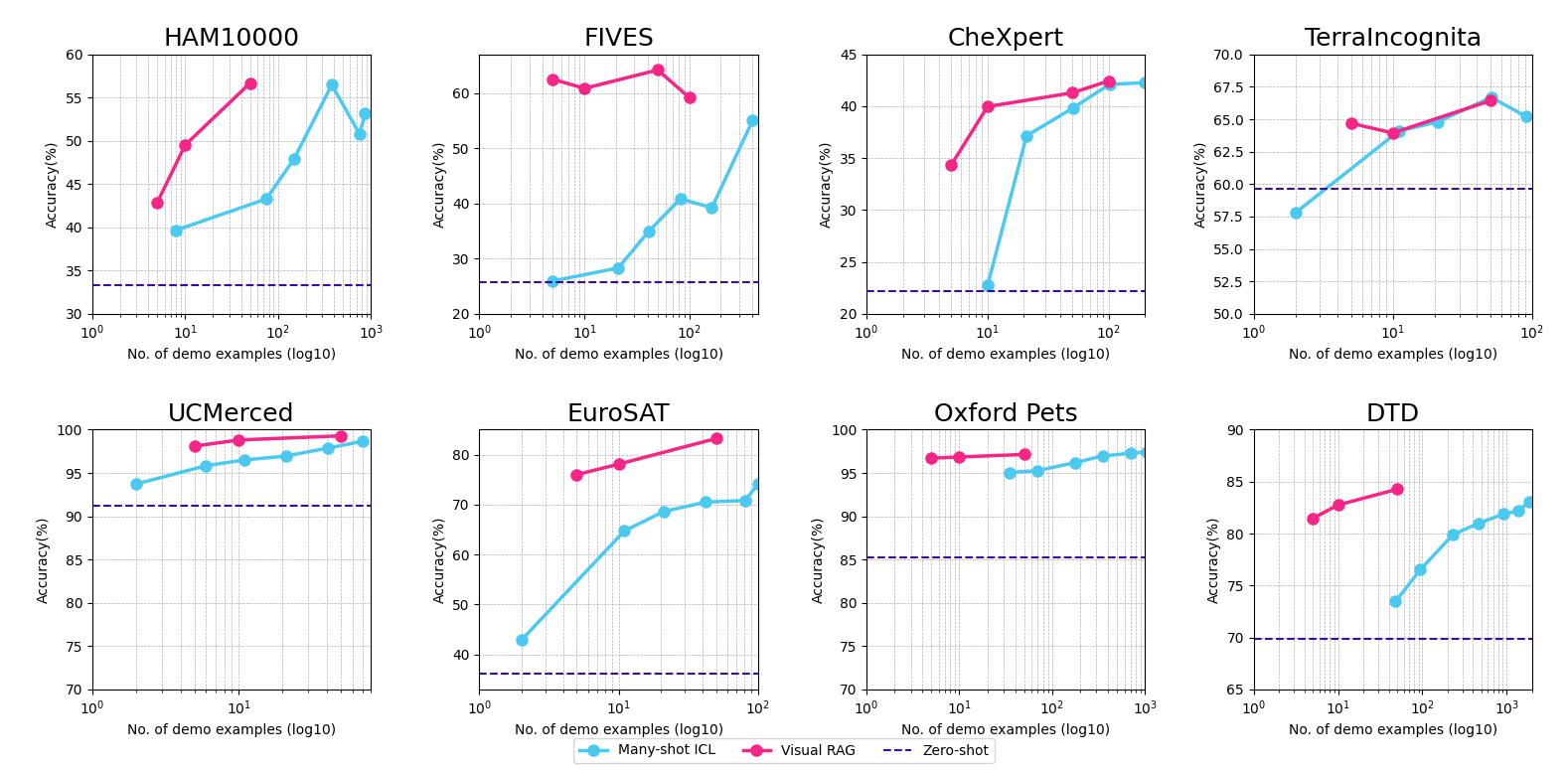
- 实验表明,Visual RAG在多个图像分类数据集上,使用更少的演示示例,达到了与多样本ICL相当甚至更高的准确率。
📝 摘要(中文)
多模态大型语言模型(MLLM)在需要跨视觉和文本模态进行推理的计算机视觉任务中取得了显著的性能,但其能力受限于预训练数据,需要进行大量的微调才能更新。最近的研究探索了使用上下文学习(ICL)来克服这些挑战,通过提供一组演示示例作为上下文来增强MLLM在多个任务中的性能,表明多样本ICL比少样本ICL带来显著的改进。然而,对大量演示示例的依赖以及有限的MLLM上下文窗口带来了重大障碍。本文旨在通过引入一种新颖的方法Visual RAG来解决这些挑战,该方法协同结合了MLLM从上下文中学习的能力和检索机制。该方法的核心在于确保通过仅选择与查询最相关的演示示例来增强MLLM的知识,从而推动其通过类比进行学习。通过依赖于推理时动态提供的新信息,最终的系统不受限于从训练数据中提取的知识,而是可以快速轻松地更新,而无需进行微调。此外,这大大降低了提高模型图像分类性能的计算成本,并将模型知识扩展到其未训练过的新视觉领域和任务。在涵盖多个领域和图像分类任务的八个不同的最先进数据集上进行的大量实验表明,与最新的技术(即多样本ICL)相比,所提出的Visual RAG能够获得非常接近甚至更高的准确率(平均提高约+2%),同时使用更小的演示示例集(平均仅约23%)。
🔬 方法详解
问题定义:MLLM在视觉任务中表现出色,但其知识受限于预训练数据,需要大量微调才能适应新任务和领域。现有的上下文学习方法(ICL)虽然可以缓解这个问题,但需要大量的演示示例,这不仅增加了计算成本,也受限于MLLM有限的上下文窗口。因此,如何在不进行微调的情况下,高效地扩展MLLM的视觉知识,是一个亟待解决的问题。
核心思路:Visual RAG的核心思路是利用检索增强生成(RAG)的思想,从海量的示例库中检索与当前查询最相关的少量示例,并将这些示例作为上下文提供给MLLM,使其能够通过类比学习,从而扩展其知识。这样,MLLM就可以在推理时动态地获取新信息,而无需进行耗时的微调。
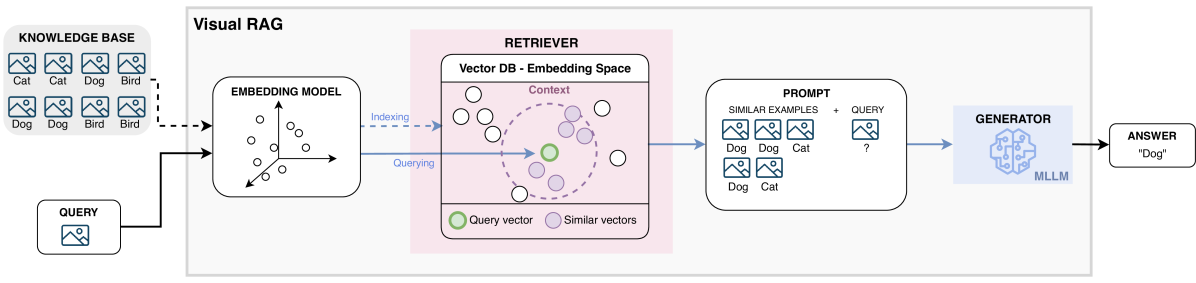
技术框架:Visual RAG的整体框架包含以下几个主要模块:1) 示例库构建:构建包含大量图像及其对应标签的示例库。2) 特征提取:使用预训练的视觉模型(如CLIP)提取图像的视觉特征。3) 检索模块:根据查询图像的视觉特征,从示例库中检索最相似的K个示例。4) 上下文构建:将检索到的示例及其标签作为上下文,构建提示(Prompt)。5) MLLM推理:将构建好的提示输入MLLM,进行图像分类。
关键创新:Visual RAG的关键创新在于将RAG的思想引入到视觉任务中,并将其与MLLM的上下文学习能力相结合。与传统的ICL方法相比,Visual RAG无需依赖大量的演示示例,而是通过检索的方式动态地获取最相关的示例,从而大大提高了效率和泛化能力。与微调方法相比,Visual RAG无需进行耗时的模型训练,可以快速适应新任务和领域。
关键设计:Visual RAG的关键设计包括:1) 特征提取器的选择:选择合适的预训练视觉模型(如CLIP)来提取图像的视觉特征,以保证检索的准确性。2) 检索算法的选择:选择高效的检索算法(如ANN)来加速检索过程。3) 上下文构建方式:设计合理的上下文构建方式,以充分利用检索到的示例信息。4) K值的选择:选择合适的K值,以平衡检索的准确性和计算成本。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Visual RAG在八个不同的图像分类数据集上,与最新的多样本ICL方法相比,能够获得非常接近甚至更高的准确率(平均提高约+2%),同时使用的演示示例数量平均仅为多样本ICL的23%。这表明Visual RAG在提高模型性能的同时,显著降低了计算成本。
🎯 应用场景
Visual RAG可应用于各种图像分类任务,尤其适用于数据量有限或需要快速适应新领域的场景,例如医学图像诊断、遥感图像分析、工业质检等。该方法能够降低模型部署和维护成本,加速模型迭代,并提升模型在实际应用中的泛化能力。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have achieved notable performance in computer vision tasks that require reasoning across visual and textual modalities, yet their capabilities are limited to their pre-trained data, requiring extensive fine-tuning for updates. Recent researches have explored the use of In-Context Learning (ICL) to overcome these challenges by providing a set of demonstrating examples as context to augment MLLMs performance in several tasks, showing that many-shot ICL leads to substantial improvements compared to few-shot ICL. However, the reliance on numerous demonstrating examples and the limited MLLMs context windows presents significant obstacles. This paper aims to address these challenges by introducing a novel approach, Visual RAG, that synergically combines the MLLMs capability to learn from the context, with a retrieval mechanism. The crux of this approach is to ensure to augment the MLLM knowledge by selecting only the most relevant demonstrating examples for the query, pushing it to learn by analogy. In this way, relying on the new information provided dynamically during inference time, the resulting system is not limited to the knowledge extracted from the training data, but can be updated rapidly and easily without fine-tuning. Furthermore, this greatly reduces the computational costs for improving the model image classification performance, and augments the model knowledge to new visual domains and tasks it was not trained for. Extensive experiments on eight different datasets in the state of the art spanning several domains and image classification tasks show that the proposed Visual RAG, compared to the most recent state of the art (i.e., many-shot ICL), is able to obtain an accuracy that is very close or even higher (approx. +2% improvement on average) while using a much smaller set of demonstrating examples (approx. only 23% on average).