Can Multimodal LLMs do Visual Temporal Understanding and Reasoning? The answer is No!
作者: Mohamed Fazli Imam, Chenyang Lyu, Alham Fikri Aji
分类: cs.CV, cs.CL
发布日期: 2025-01-18 (更新: 2025-02-18)
备注: Our dataset can be found at \url{https://huggingface.co/datasets/fazliimam/temporal-vqa}
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
揭示多模态大语言模型在视觉时序理解与推理上的局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉时序理解 时间推理 评估基准 TemporalVQA
📋 核心要点
- 现有MLLM在视觉问答等任务表现出色,但在视觉时序理解方面能力不足,难以理解真实世界动态。
- 论文提出TemporalVQA基准,包含时序顺序理解和延时估计两部分,用于评估MLLM的时序推理能力。
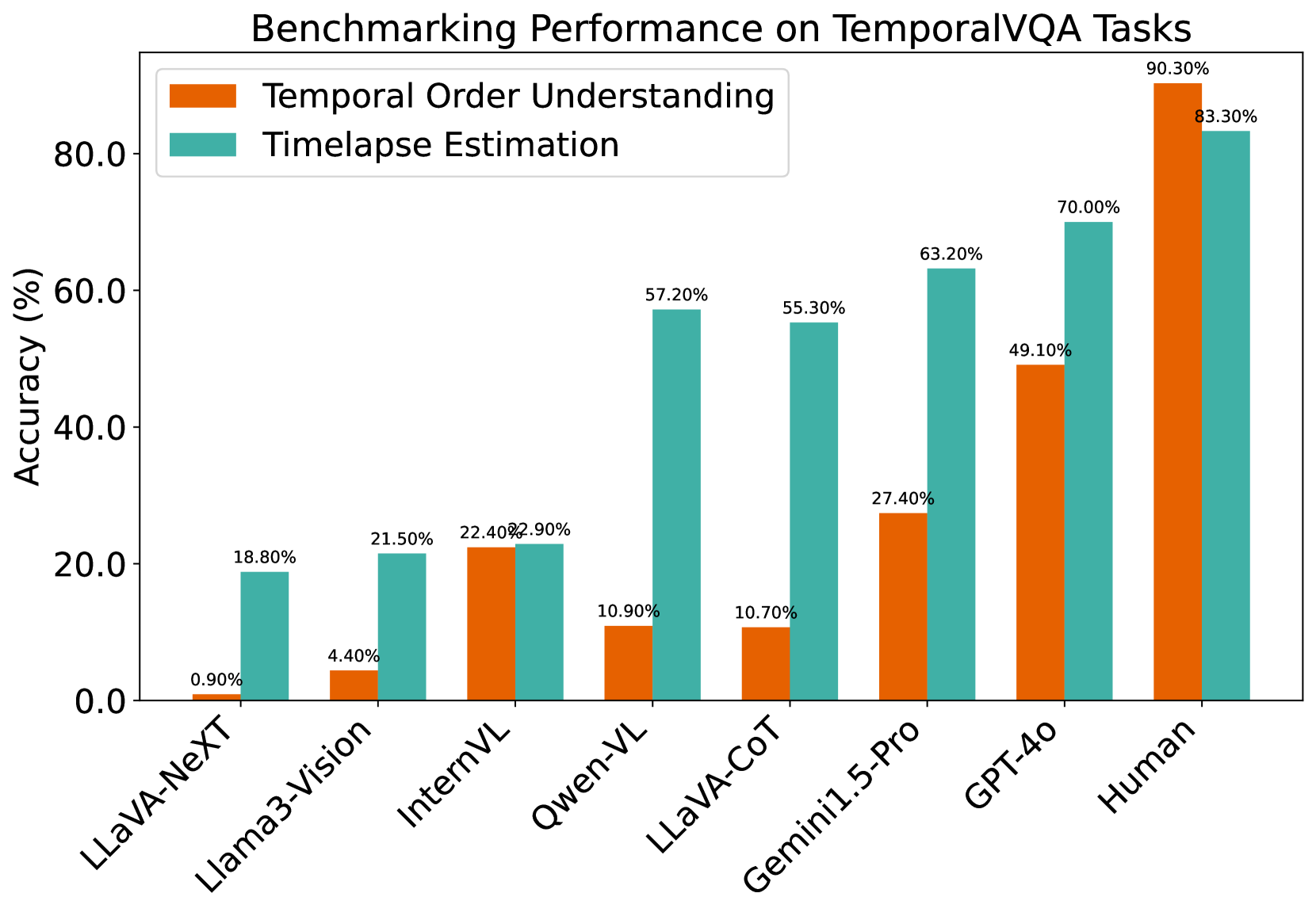
- 实验表明,即使是GPT-4o等先进MLLM在TemporalVQA上也表现出显著局限性,开源模型表现更差。
📝 摘要(中文)
多模态大语言模型(MLLMs)通过利用基础大语言模型(LLMs),在视觉问答(VQA)等任务中取得了显著进展。然而,它们在视觉时序理解等特定领域的能力仍未被充分探索,而视觉时序理解对于理解真实世界的动态至关重要。为了解决这个问题,我们提出了一个具有挑战性的评估基准TemporalVQA,它由两部分组成:1)时序顺序理解和2)延时估计。第一部分要求MLLM通过分析时间上连续的视频帧来确定事件的顺序。第二部分呈现具有不同时间差的图像对,以多项选择题的形式,要求MLLM估计图像之间的时间间隔,选项范围从几秒到几年。我们对包括GPT-4o和Gemini-1.5-Pro等先进MLLM的评估表明,它们面临着重大挑战:GPT-4o在时序顺序任务中仅达到49.1%的平均一致性准确率,在延时估计中达到70%,而开源模型的表现甚至更差。这些发现强调了当前MLLM在视觉时序理解和推理方面的局限性,突出了进一步提高其时序能力的必要性。我们的数据集可在https://huggingface.co/datasets/fazliimam/temporal-vqa找到。
🔬 方法详解
问题定义:论文旨在评估和揭示当前多模态大语言模型(MLLMs)在视觉时序理解和推理方面的能力局限性。现有方法虽然在静态图像理解和视觉问答等任务上取得了进展,但缺乏对时间维度信息的有效处理,导致无法准确理解和推理视频中的事件顺序和时间间隔。这种局限性阻碍了MLLMs在需要理解动态场景的应用中的发展。
核心思路:论文的核心思路是通过构建一个专门的评估基准TemporalVQA,来系统地测试MLLMs在视觉时序理解方面的能力。TemporalVQA包含两个子任务:时序顺序理解和延时估计,分别考察模型对事件发生顺序的判断能力和对时间流逝的感知能力。通过在这两个任务上的评估,可以更全面地了解MLLMs在处理时间信息方面的优势和不足。
技术框架:TemporalVQA基准包含两个主要模块:1) 时序顺序理解:该模块提供一系列时间上连续的视频帧,要求模型判断事件发生的正确顺序。这需要模型能够理解帧之间的细微差别,并推断出事件的演变过程。2) 延时估计:该模块提供图像对,图像之间存在不同的时间间隔(从秒到年),模型需要从多个选项中选择正确的时间间隔。这需要模型能够感知不同时间尺度下的视觉变化,并将其与时间流逝联系起来。
关键创新:该论文的关键创新在于提出了TemporalVQA,这是一个专门用于评估MLLMs视觉时序理解能力的基准。与现有的VQA数据集不同,TemporalVQA侧重于考察模型对时间信息的处理能力,填补了现有评估体系的空白。此外,该基准包含两个具有挑战性的子任务,可以更全面地评估MLLMs在不同时间尺度下的推理能力。
关键设计:在时序顺序理解任务中,关键设计在于选择具有明确时间顺序的视频片段,并确保帧之间的差异足够细微,以考验模型的辨别能力。在延时估计任务中,关键设计在于选择具有代表性的图像对,图像之间的时间间隔覆盖了从秒到年的多个尺度,并提供合理的选项范围,以避免模型通过简单的猜测获得高分。此外,评估指标采用平均一致性准确率,以衡量模型在多个时间顺序判断中的一致性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,即使是GPT-4o和Gemini-1.5-Pro等先进MLLM在TemporalVQA基准上也表现出显著的局限性。GPT-4o在时序顺序任务中仅达到49.1%的平均一致性准确率,在延时估计中达到70%,而开源模型的表现更差。这些结果表明,当前MLLM在视觉时序理解和推理方面仍有很大的提升空间。
🎯 应用场景
该研究成果可应用于视频监控、自动驾驶、医疗影像分析等领域。例如,在视频监控中,模型可以理解事件发生的先后顺序,从而更准确地识别异常行为。在自动驾驶中,模型可以估计不同物体之间的时间间隔,从而更好地预测交通状况。在医疗影像分析中,模型可以分析病灶随时间的变化,从而辅助医生进行诊断。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have achieved significant advancements in tasks like Visual Question Answering (VQA) by leveraging foundational Large Language Models (LLMs). However, their abilities in specific areas such as visual temporal understanding, which is crucial for comprehending real-world dynamics, remain underexplored. To address this, we propose a challenging evaluation benchmark named TemporalVQA, consisting of two parts: 1) Temporal Order Understanding and 2) Time-lapse Estimation. The first part requires MLLMs to determine the sequence of events by analyzing temporally consecutive video frames. The second part presents image pairs with varying time differences, framed as multiple-choice questions, asking MLLMs to estimate the time-lapse between images with options ranging from seconds to years. Our evaluations of advanced MLLMs, including models like GPT-4o and Gemini-1.5-Pro, reveal significant challenges: GPT-4o achieved only 49.1% average consistent accuracy in temporal order task and 70% in time-lapse estimation, with open-source models performing even poorly. These findings underscore the limitations of current MLLMs in visual temporal understanding and reasoning, highlighting the need for further improvements for their temporal capability. Our dataset can be found at https://huggingface.co/datasets/fazliimam/temporal-vqa.