Spatio-temporal Graph Learning on Adaptive Mined Key Frames for High-performance Multi-Object Tracking
作者: Futian Wang, Fengxiang Liu, Xiao Wang
分类: cs.CV, cs.AI
发布日期: 2025-01-17
💡 一句话要点
提出基于自适应关键帧挖掘的时空图学习多目标跟踪方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 多目标跟踪 图卷积网络 强化学习 关键帧提取 时空图学习
📋 核心要点
- 现有方法难以准确捕捉多目标跟踪中对象间的时空关系,且易受遮挡影响。
- 提出自适应关键帧挖掘策略,利用强化学习提取关键帧,并使用图卷积网络进行帧内特征融合。
- 在MOT17数据集上取得了显著成果,HOTA达到68.6,IDF1达到81.0,证明了方法的有效性。
📝 摘要(中文)
在多目标跟踪领域,准确捕捉视频序列中对象之间的时空关系仍然是一个重大挑战。对象之间频繁发生的相互遮挡进一步加剧了这一问题,导致现有方法出现跟踪错误和性能下降。为了应对这些挑战,我们提出了一种新颖的自适应关键帧挖掘策略,以解决当前跟踪方法的局限性。具体来说,我们引入了一个关键帧提取(KFE)模块,该模块利用强化学习来适应性地分割视频,从而引导跟踪器利用视频内容的内在逻辑。这种方法使我们能够捕获不同对象之间的结构化空间关系以及对象在帧之间的时间关系。为了解决对象遮挡问题,我们开发了一个帧内特征融合(IFF)模块。与主要关注帧间特征融合的传统基于图的方法不同,我们的IFF模块使用图卷积网络(GCN)来促进帧内目标和周围对象之间的信息交换。这项创新显著提高了目标的可区分性,并减轻了由于遮挡导致的跟踪丢失和外观相似性。通过结合长短轨迹的优势并考虑对象之间的空间关系,我们提出的跟踪器在MOT17数据集上取得了令人印象深刻的结果,即68.6 HOTA、81.0 IDF1、66.6 AssA和893 IDS,证明了其有效性和准确性。
🔬 方法详解
问题定义:多目标跟踪(MOT)旨在识别和跟踪视频序列中的多个目标。现有方法在处理目标遮挡、外观相似以及复杂场景时面临挑战,尤其是在准确建模目标间的时空关系方面存在不足。传统方法往往难以有效区分被遮挡的目标,导致跟踪失败或身份切换(ID switch)。
核心思路:本文的核心思路是通过自适应地挖掘关键帧,并利用图卷积网络(GCN)进行帧内特征融合,从而更有效地建模目标间的时空关系,提高目标区分度,减轻遮挡带来的负面影响。关键帧提取旨在保留视频中的重要信息,减少计算量,同时GCN用于在帧内进行信息交互,增强目标特征表示。
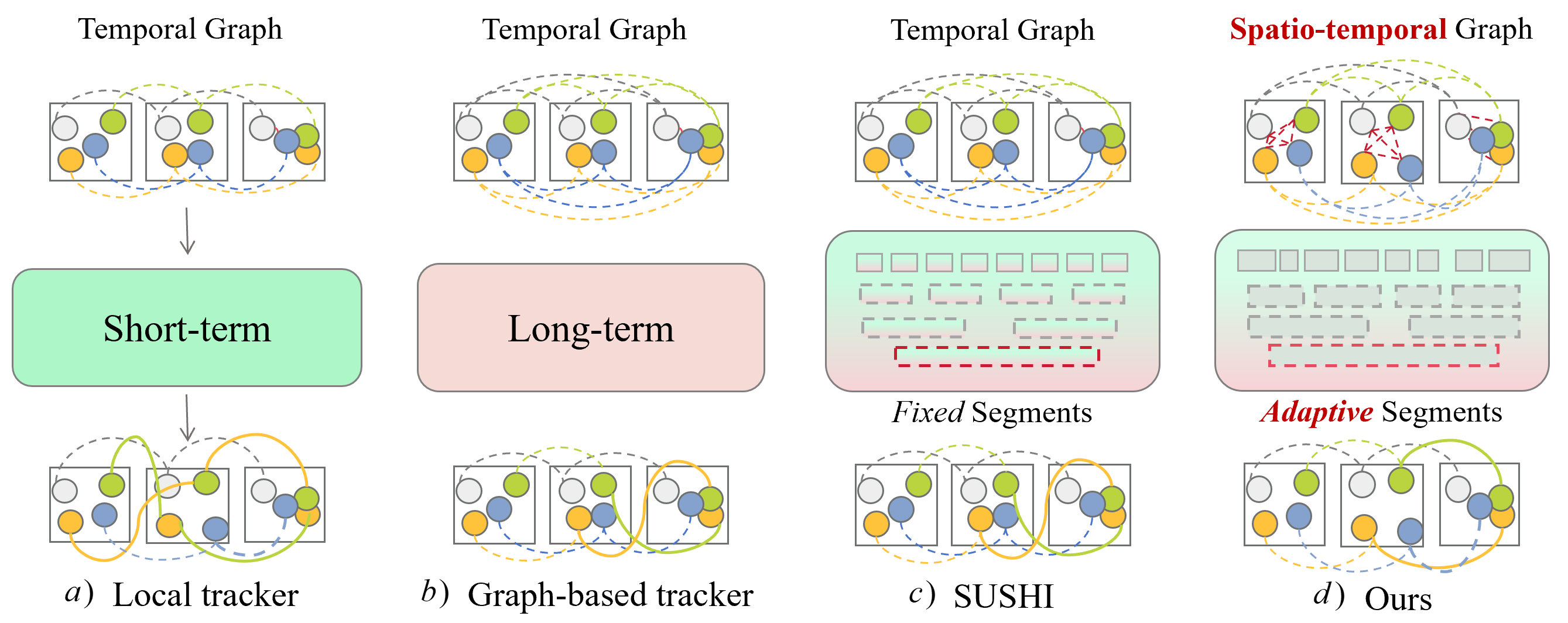
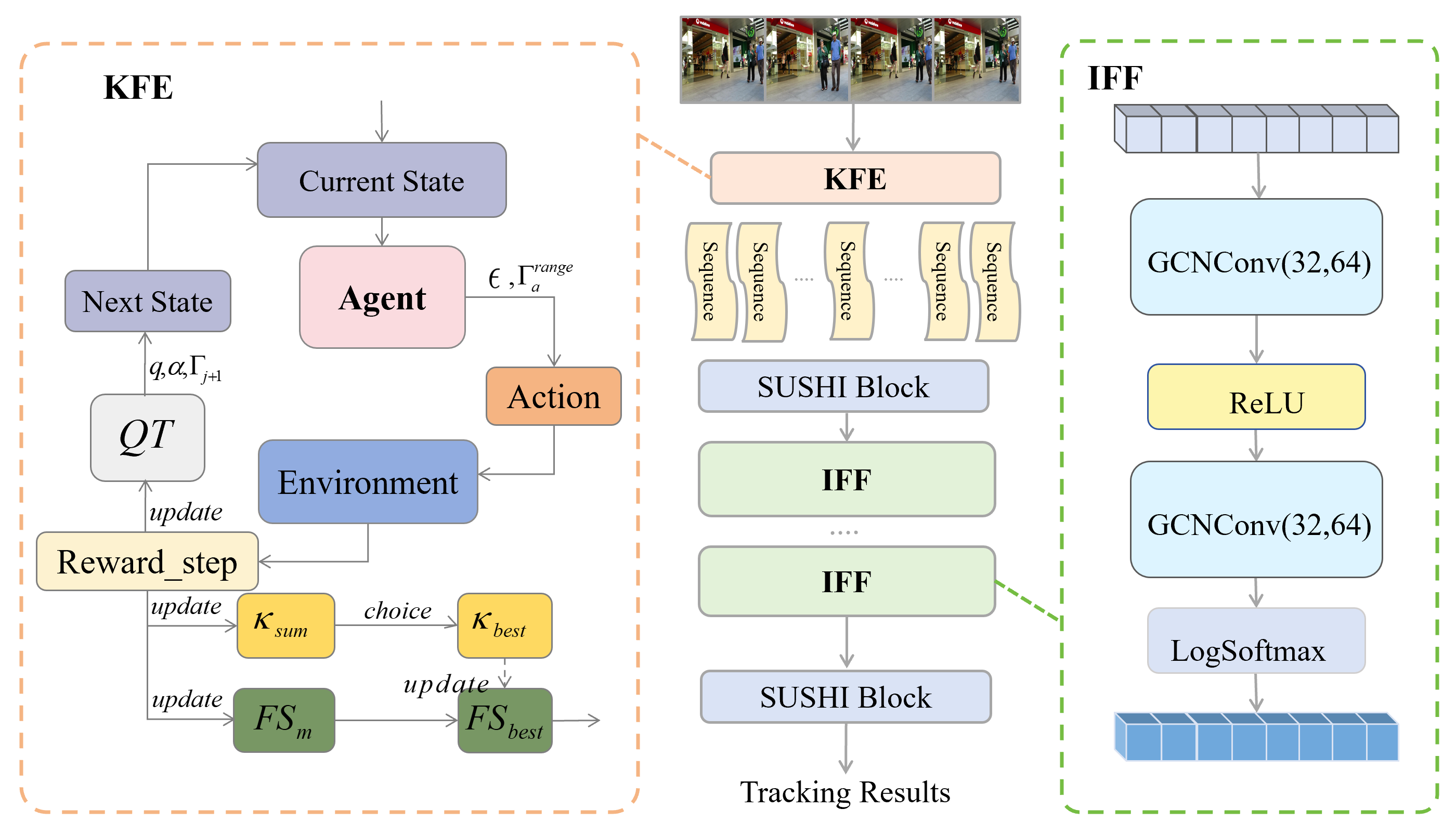
技术框架:该跟踪器主要包含两个核心模块:关键帧提取(KFE)模块和帧内特征融合(IFF)模块。KFE模块使用强化学习来动态选择关键帧,从而捕获视频内容的关键信息。IFF模块则利用GCN在每一帧内进行目标特征融合,增强目标表示。整体流程为:首先,使用KFE模块提取关键帧;然后,对每个关键帧中的目标进行检测和特征提取;接着,利用IFF模块进行帧内特征融合;最后,使用匈牙利算法等方法进行帧间关联,完成多目标跟踪。
关键创新:该论文的关键创新在于以下两点:一是提出了基于强化学习的自适应关键帧提取策略,能够根据视频内容动态选择关键帧,避免了传统方法中固定间隔采样带来的信息损失或冗余计算。二是引入了帧内特征融合模块,利用GCN在帧内进行目标间的信息交互,增强了目标特征的区分性,有效缓解了遮挡问题。与现有方法相比,该方法更注重利用帧内信息来提升跟踪性能。
关键设计:KFE模块使用强化学习,奖励函数的设计至关重要,需要平衡跟踪精度和计算效率。IFF模块中GCN的结构设计,包括层数、卷积核大小等,会影响特征融合的效果。此外,损失函数的设计也需要考虑目标区分性和跟踪稳定性。具体参数设置和网络结构细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片

📊 实验亮点
该方法在MOT17数据集上取得了显著的性能提升,HOTA指标达到68.6,IDF1指标达到81.0,AssA指标达到66.6,IDS指标为893。这些结果表明,该方法在多目标跟踪的准确性和鲁棒性方面具有显著优势,尤其是在处理遮挡和复杂场景时表现出色。相较于其他基线方法,该方法在各项指标上均有明显提升(具体提升幅度未知)。
🎯 应用场景
该研究成果可应用于智能监控、自动驾驶、机器人导航等领域。在智能监控中,可以更准确地跟踪人群和车辆,提高安全性和效率。在自动驾驶中,可以更可靠地识别和跟踪行人、车辆等目标,提升驾驶安全性。在机器人导航中,可以帮助机器人更好地理解周围环境,实现更精准的定位和导航。
📄 摘要(原文)
In the realm of multi-object tracking, the challenge of accurately capturing the spatial and temporal relationships between objects in video sequences remains a significant hurdle. This is further complicated by frequent occurrences of mutual occlusions among objects, which can lead to tracking errors and reduced performance in existing methods. Motivated by these challenges, we propose a novel adaptive key frame mining strategy that addresses the limitations of current tracking approaches. Specifically, we introduce a Key Frame Extraction (KFE) module that leverages reinforcement learning to adaptively segment videos, thereby guiding the tracker to exploit the intrinsic logic of the video content. This approach allows us to capture structured spatial relationships between different objects as well as the temporal relationships of objects across frames. To tackle the issue of object occlusions, we have developed an Intra-Frame Feature Fusion (IFF) module. Unlike traditional graph-based methods that primarily focus on inter-frame feature fusion, our IFF module uses a Graph Convolutional Network (GCN) to facilitate information exchange between the target and surrounding objects within a frame. This innovation significantly enhances target distinguishability and mitigates tracking loss and appearance similarity due to occlusions. By combining the strengths of both long and short trajectories and considering the spatial relationships between objects, our proposed tracker achieves impressive results on the MOT17 dataset, i.e., 68.6 HOTA, 81.0 IDF1, 66.6 AssA, and 893 IDS, proving its effectiveness and accuracy.