One-D-Piece: Image Tokenizer Meets Quality-Controllable Compression
作者: Keita Miwa, Kento Sasaki, Hidehisa Arai, Tsubasa Takahashi, Yu Yamaguchi
分类: cs.CV, cs.LG
发布日期: 2025-01-17
备注: Our Project Page: https://turingmotors.github.io/one-d-piece-tokenizer
💡 一句话要点
One-D-Piece:面向质量可控压缩的可变长图像Token化方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 图像Token化 可变长度编码 图像压缩 质量可控 尾部Token丢弃 计算机视觉 重建质量
📋 核心要点
- 现有图像Token化方法需要大量Token来捕获图像信息,效率较低,无法根据图像内容自适应调整Token数量。
- 论文提出One-D-Piece,通过“尾部Token丢弃”正则化,使关键信息集中在Token序列头部,实现可变长度Token化。
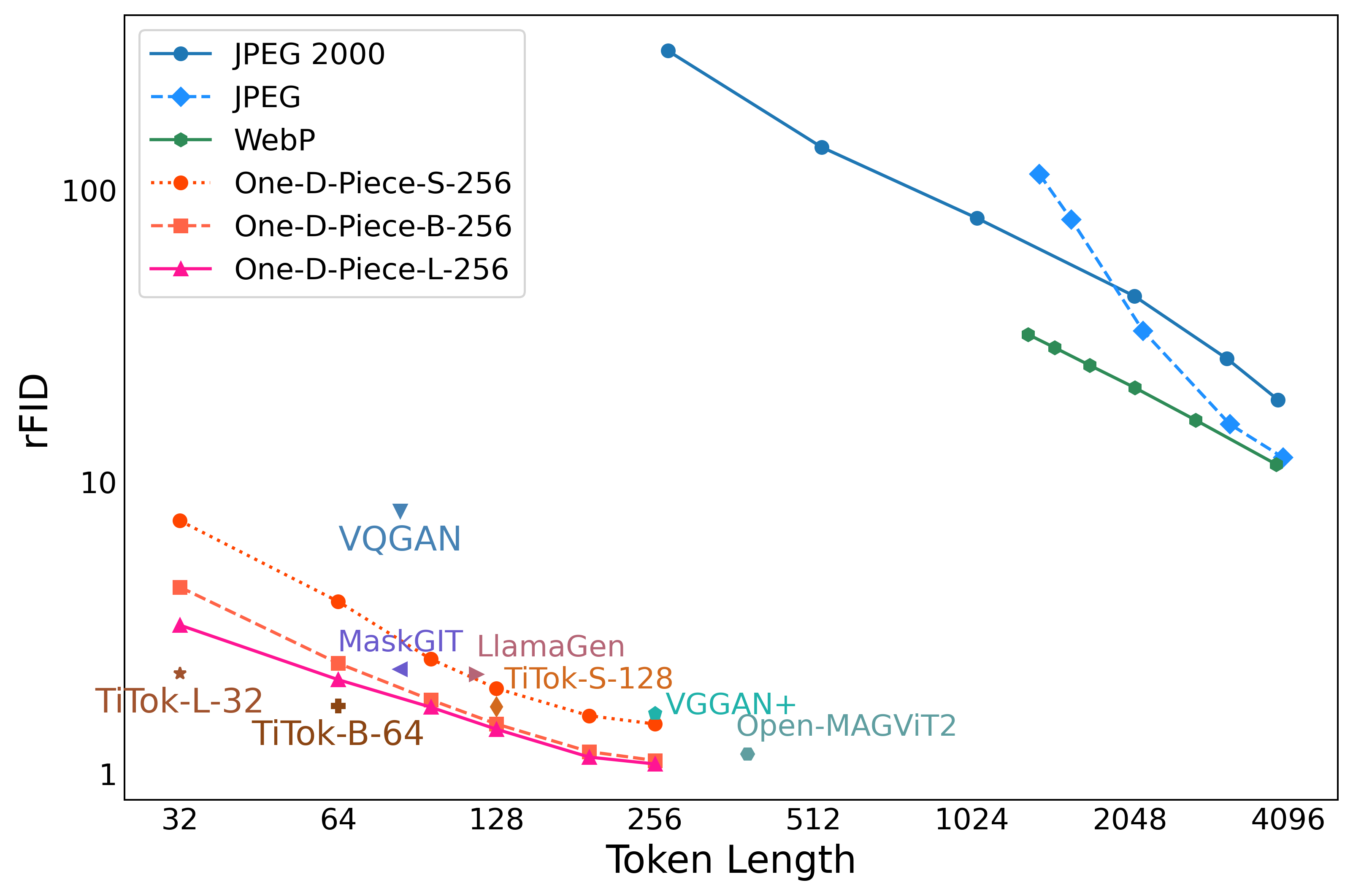
- 实验表明,该方法在更小字节下,重建质量优于JPEG和WebP,且在图像分类、检测等下游任务中表现出良好的适应性。
📝 摘要(中文)
本文提出了一种名为One-D-Piece的离散图像Token化方法,旨在实现可变长度的Token化,从而达到质量可控的压缩。为了实现可变的压缩率,本文在离散一维图像Token化器中引入了一种简单而有效的正则化机制,称为“尾部Token丢弃”(Tail Token Drop)。该方法鼓励关键信息集中在Token序列的头部,从而支持可变Token化,同时保持了最先进的重建质量。在多个重建质量指标上评估了本文的Token化器,结果表明,在更小的字节大小下,它比现有的质量可控压缩方法(包括JPEG和WebP)提供了明显更好的感知质量。此外,本文还在各种下游计算机视觉任务(包括图像分类、目标检测、语义分割和深度估计)上评估了本文的Token化器,证实了与其他变速率方法相比,它对众多应用的适应性。本文的方法展示了可变长度离散图像Token化的多功能性,在压缩效率和重建性能方面建立了一种新的范例。最后,本文通过对Token化器的详细分析验证了尾部Token丢弃的有效性。
🔬 方法详解
问题定义:现有图像Token化方法通常采用固定长度的Token序列,无法根据图像内容的复杂程度自适应地分配Token数量。对于信息量较少的图像,固定长度Token化会造成冗余;而对于信息量丰富的图像,则可能无法充分表达。这种固定长度的限制导致了Token分配的低效性,影响了压缩效率和重建质量。
核心思路:论文的核心思路是设计一种可变长度的图像Token化方法,允许根据图像内容动态调整Token数量。通过鼓励关键信息集中在Token序列的头部,并允许丢弃尾部的Token,从而实现质量可控的压缩。这种方法旨在提高压缩效率,同时保持良好的重建质量。
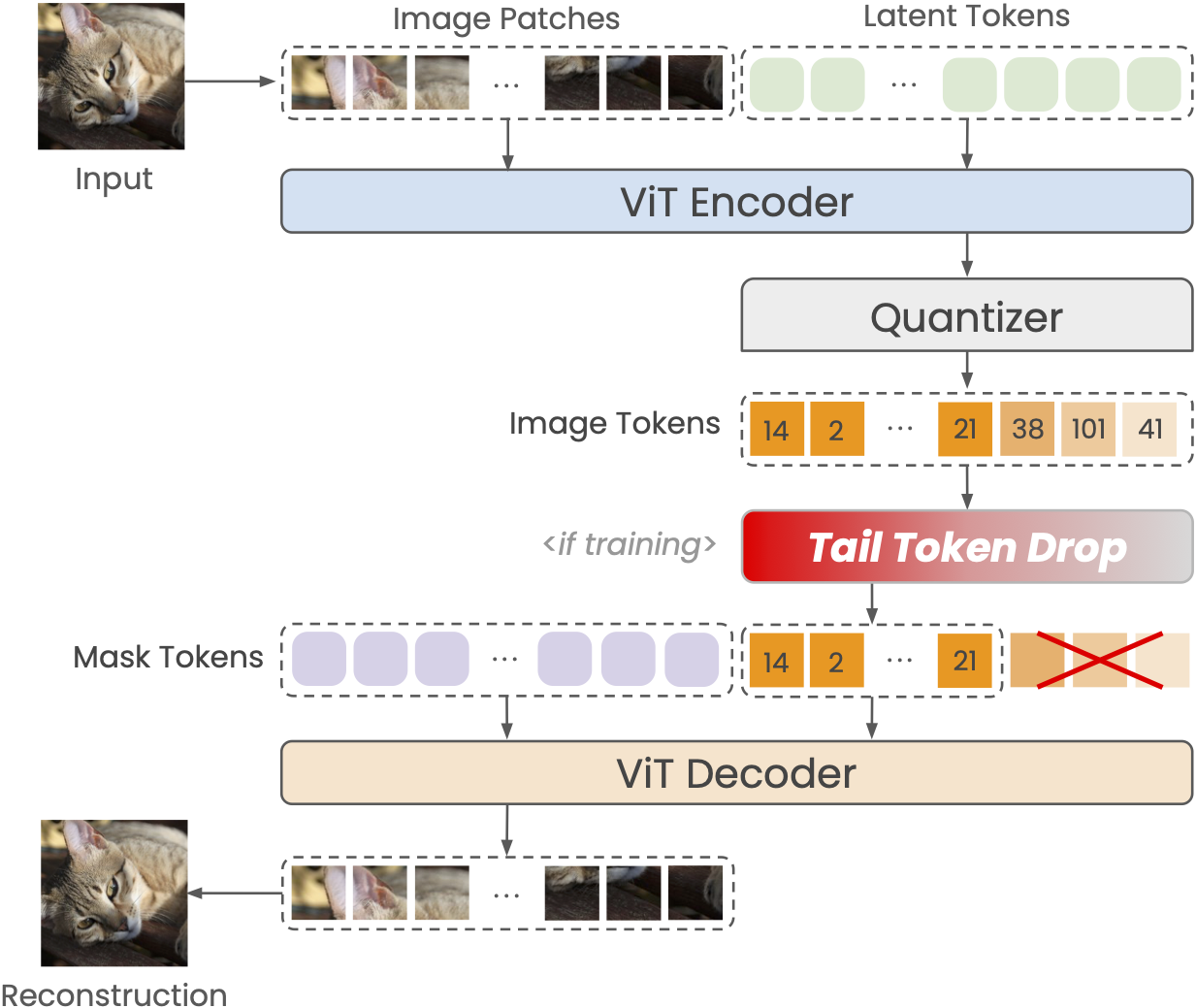
技术框架:One-D-Piece的整体框架基于离散一维图像Token化器。首先,图像被编码成一个Token序列。然后,通过引入“尾部Token丢弃”正则化机制,鼓励关键信息集中在Token序列的头部。在解码阶段,根据所需的压缩率,可以选择性地丢弃尾部的Token,并使用剩余的Token重建图像。整个流程包括编码、正则化、截断(可选)和解码四个主要阶段。
关键创新:最重要的技术创新点是“尾部Token丢弃”正则化机制。与现有方法不同,该机制不是简单地对所有Token进行同等处理,而是有选择性地保留头部Token,丢弃尾部Token。这种方法能够有效地控制压缩率,同时最大限度地保留图像的关键信息。与固定长度Token化方法相比,One-D-Piece能够更灵活地适应不同复杂度的图像。
关键设计:在“尾部Token丢弃”正则化机制中,一个关键的设计是损失函数的设计,它需要鼓励信息集中在头部Token。具体的实现细节,例如损失函数的具体形式、Token序列的长度、以及丢弃Token的比例等,都会影响最终的性能。此外,编码器和解码器的网络结构也需要精心设计,以确保能够有效地提取和重建图像信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,One-D-Piece在重建质量方面优于JPEG和WebP等传统压缩方法,尤其是在感知质量方面有显著提升。在相同的字节大小下,One-D-Piece能够提供更清晰、更逼真的图像重建效果。此外,在图像分类、目标检测、语义分割和深度估计等下游任务中,One-D-Piece也表现出良好的性能,证明了其作为通用图像表示的有效性。
🎯 应用场景
One-D-Piece具有广泛的应用前景,包括图像压缩、图像检索、图像编辑和计算机视觉任务预训练等。该方法可以用于开发更高效的图像压缩算法,降低存储和传输成本。此外,可变长度的Token化表示可以用于图像检索,提高检索效率和准确性。在图像编辑领域,可以基于Token序列进行局部修改,实现精细化的图像编辑。最后,One-D-Piece可以作为计算机视觉任务的预训练模型,提高下游任务的性能。
📄 摘要(原文)
Current image tokenization methods require a large number of tokens to capture the information contained within images. Although the amount of information varies across images, most image tokenizers only support fixed-length tokenization, leading to inefficiency in token allocation. In this study, we introduce One-D-Piece, a discrete image tokenizer designed for variable-length tokenization, achieving quality-controllable mechanism. To enable variable compression rate, we introduce a simple but effective regularization mechanism named "Tail Token Drop" into discrete one-dimensional image tokenizers. This method encourages critical information to concentrate at the head of the token sequence, enabling support of variadic tokenization, while preserving state-of-the-art reconstruction quality. We evaluate our tokenizer across multiple reconstruction quality metrics and find that it delivers significantly better perceptual quality than existing quality-controllable compression methods, including JPEG and WebP, at smaller byte sizes. Furthermore, we assess our tokenizer on various downstream computer vision tasks, including image classification, object detection, semantic segmentation, and depth estimation, confirming its adaptability to numerous applications compared to other variable-rate methods. Our approach demonstrates the versatility of variable-length discrete image tokenization, establishing a new paradigm in both compression efficiency and reconstruction performance. Finally, we validate the effectiveness of tail token drop via detailed analysis of tokenizers.