FoundationStereo: Zero-Shot Stereo Matching
作者: Bowen Wen, Matthew Trepte, Joseph Aribido, Jan Kautz, Orazio Gallo, Stan Birchfield
分类: cs.CV, cs.LG, cs.RO
发布日期: 2025-01-17 (更新: 2025-04-04)
备注: CVPR 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出FoundationStereo,实现立体匹配的零样本泛化能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 立体匹配 零样本学习 深度估计 基础模型 合成数据
📋 核心要点
- 现有深度立体匹配方法依赖于特定领域的微调,零样本泛化能力不足。
- FoundationStereo通过大规模合成数据训练、自动数据清洗和架构设计,提升零样本泛化能力。
- 该方法在多个领域表现出强大的鲁棒性和准确性,为零样本立体深度估计设立新标准。
📝 摘要(中文)
深度立体匹配通过特定领域的微调在基准数据集上取得了显著进展。然而,对于立体匹配而言,实现强大的零样本泛化能力(这是其他计算机视觉任务中基础模型的标志)仍然具有挑战性。我们提出了FoundationStereo,这是一个用于立体深度估计的基础模型,旨在实现强大的零样本泛化。为此,我们首先构建了一个大规模(100万个立体图像对)的合成训练数据集,该数据集具有高度的多样性和逼真的光照效果,然后采用自动自校正流程来消除模糊样本。我们还设计了许多网络架构组件来增强可扩展性,包括一个侧调优特征骨干网络,该网络可以从视觉基础模型中调整丰富的单目先验知识,以缓解sim-to-real的差距,以及用于有效成本量滤波的远程上下文推理。这些组件共同实现了跨域的强大鲁棒性和准确性,为零样本立体深度估计建立了一个新的标准。
🔬 方法详解
问题定义:现有的深度立体匹配方法在特定数据集上表现出色,但泛化能力差,难以直接应用于新的、未见过的场景。这是因为它们过度拟合了训练数据的特定领域特征,缺乏对不同场景的适应性。因此,如何提升立体匹配模型的零样本泛化能力,使其能够直接应用于各种真实场景,是一个重要的挑战。
核心思路:FoundationStereo的核心思路是利用大规模合成数据训练,并结合有效的网络架构设计,使模型能够学习到更通用的立体匹配特征。通过构建一个包含多样化场景和光照条件的大规模合成数据集,模型可以接触到更广泛的视觉信息。同时,通过自动数据清洗,可以去除模糊或不准确的样本,提高训练数据的质量。此外,利用从视觉基础模型中提取的单目先验知识,可以弥合合成数据和真实数据之间的差距。
技术框架:FoundationStereo的整体框架包括以下几个主要模块:1) 大规模合成数据生成模块,用于生成包含多样化场景和光照条件的立体图像对;2) 自动数据清洗模块,用于去除模糊或不准确的样本;3) 侧调优特征骨干网络,用于从视觉基础模型中提取单目先验知识,并将其融入到立体匹配模型中;4) 远程上下文推理模块,用于有效过滤成本量,提高深度估计的准确性。
关键创新:FoundationStereo的关键创新在于以下几个方面:1) 大规模合成数据的构建和自动数据清洗流程,保证了训练数据的多样性和质量;2) 侧调优特征骨干网络,有效利用了视觉基础模型的单目先验知识,弥合了sim-to-real的差距;3) 远程上下文推理模块,提高了深度估计的准确性。
关键设计:在网络结构方面,FoundationStereo采用了侧调优的特征骨干网络,该网络可以从预训练的视觉基础模型中提取特征,并将其与立体匹配网络的特征进行融合。在损失函数方面,使用了标准的L1损失函数来衡量预测深度和真实深度之间的差异。此外,还使用了数据增强技术,如随机裁剪、颜色抖动等,来提高模型的鲁棒性。
🖼️ 关键图片
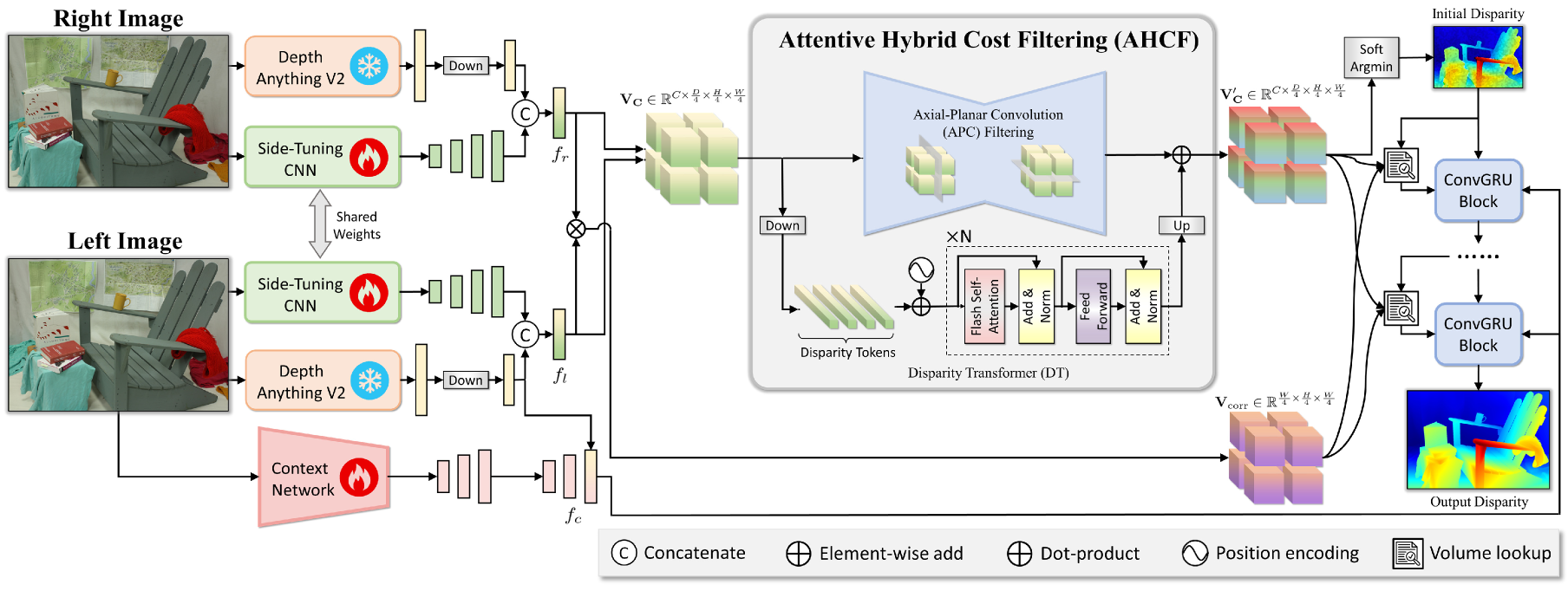


📊 实验亮点
FoundationStereo在多个零样本立体匹配基准测试中取得了显著的性能提升。实验结果表明,该方法在Middlebury、KITTI等数据集上均优于现有的零样本立体匹配方法,尤其是在具有挑战性的场景中,其鲁棒性和准确性得到了显著提升。这表明FoundationStereo具有很强的泛化能力,能够适应不同的场景和光照条件。
🎯 应用场景
FoundationStereo在自动驾驶、机器人导航、三维重建等领域具有广泛的应用前景。它可以帮助自动驾驶系统更准确地感知周围环境,提高导航的安全性;可以帮助机器人更好地理解场景,实现更智能的交互;可以用于构建高质量的三维模型,应用于虚拟现实、增强现实等领域。该研究的突破将推动立体视觉技术在实际场景中的应用。
📄 摘要(原文)
Tremendous progress has been made in deep stereo matching to excel on benchmark datasets through per-domain fine-tuning. However, achieving strong zero-shot generalization - a hallmark of foundation models in other computer vision tasks - remains challenging for stereo matching. We introduce FoundationStereo, a foundation model for stereo depth estimation designed to achieve strong zero-shot generalization. To this end, we first construct a large-scale (1M stereo pairs) synthetic training dataset featuring large diversity and high photorealism, followed by an automatic self-curation pipeline to remove ambiguous samples. We then design a number of network architecture components to enhance scalability, including a side-tuning feature backbone that adapts rich monocular priors from vision foundation models to mitigate the sim-to-real gap, and long-range context reasoning for effective cost volume filtering. Together, these components lead to strong robustness and accuracy across domains, establishing a new standard in zero-shot stereo depth estimation. Project page: https://nvlabs.github.io/FoundationStereo/