FLORA: Formal Language Model Enables Robust Training-free Zero-shot Object Referring Analysis
作者: Zhe Chen, Zijing Chen
分类: cs.CV
发布日期: 2025-01-17
💡 一句话要点
提出FLORA,利用形式语言模型实现鲁棒的无训练零样本对象指代表达式理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对象指代表达式理解 零样本学习 形式语言模型 大型语言模型 贝叶斯推理
📋 核心要点
- 现有对象指代表达式理解方法依赖大量标注数据和耗时训练,泛化能力受限。
- FLORA利用形式语言模型规范LLM输出,结合贝叶斯推理,实现无训练的零样本ORA。
- 实验表明,FLORA显著提升了现有 grounding 检测器的零样本性能,最高提升约45%。
📝 摘要(中文)
对象指代表达式理解(ORA)需要在图像中根据自然语言描述识别和定位特定对象。与通用对象检测不同,ORA需要精确的语言理解和视觉定位,因此更复杂。虽然最近预训练的大型视觉 grounding 检测器取得了显著进展,但它们严重依赖大量标注数据和耗时的学习。为了解决这些问题,我们提出了一种新颖的、无训练的零样本ORA框架,称为FLORA。FLORA利用大型语言模型(LLM)的推理能力,并集成了一个形式语言模型(FLM),该模型在结构化的、基于规则的描述中规范语言,以提供有效的零样本ORA。我们的FLM能够对对象描述进行有效的、逻辑驱动的解释,而无需任何训练过程。基于FLM规范的LLM输出,我们进一步设计了一个贝叶斯推理框架,并采用适当的现成解释模型来完成推理,从而提供针对LLM幻觉的良好鲁棒性,并在无训练的情况下实现令人信服的ORA性能。在实践中,我们的FLORA将现有预训练 grounding 检测器的零样本性能提高了约45%。在不同具有挑战性的数据集上的全面评估也证实,FLORA在与零样本ORA相关的检测和分割任务中始终优于当前最先进的零样本方法。我们相信,我们对LLM输出的概率解析和推理提高了零样本ORA的可靠性和可解释性。代码将在发表后发布。
🔬 方法详解
问题定义:论文旨在解决零样本对象指代表达式理解(ORA)问题。现有方法依赖大量标注数据进行训练,计算成本高昂,且难以泛化到未见过的场景。这些方法在处理复杂或模糊的指代表达式时,容易出现性能下降的情况。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大推理能力,并引入形式语言模型(FLM)来规范LLM的输出,从而实现无需训练的零样本ORA。通过FLM,可以对指代表达式进行逻辑驱动的解析,减少LLM的幻觉问题,提高ORA的准确性和鲁棒性。
技术框架:FLORA框架主要包含以下几个阶段:1) 使用LLM生成对指代表达式的理解;2) 使用FLM对LLM的输出进行规范化,生成结构化的逻辑表示;3) 利用贝叶斯推理框架,结合现成的解释模型,对图像中的对象进行定位和分割;4) 输出最终的ORA结果。
关键创新:论文的关键创新在于引入了形式语言模型(FLM)来规范LLM的输出。FLM通过预定义的规则和语法,将自然语言描述转换为结构化的逻辑表达式,从而减少了LLM的歧义性和不确定性。这种方法与传统的端到端训练方法不同,它利用了LLM的先验知识和推理能力,实现了真正的零样本学习。
关键设计:FLM的设计是关键。它需要能够准确地捕捉指代表达式的语义信息,并将其转换为可用于推理的逻辑形式。贝叶斯推理框架的设计也至关重要,它需要能够有效地融合来自LLM、FLM和视觉模型的证据,从而做出准确的预测。论文中使用了现成的解释模型,例如目标检测器和分割模型,这些模型的选择也会影响最终的性能。
🖼️ 关键图片
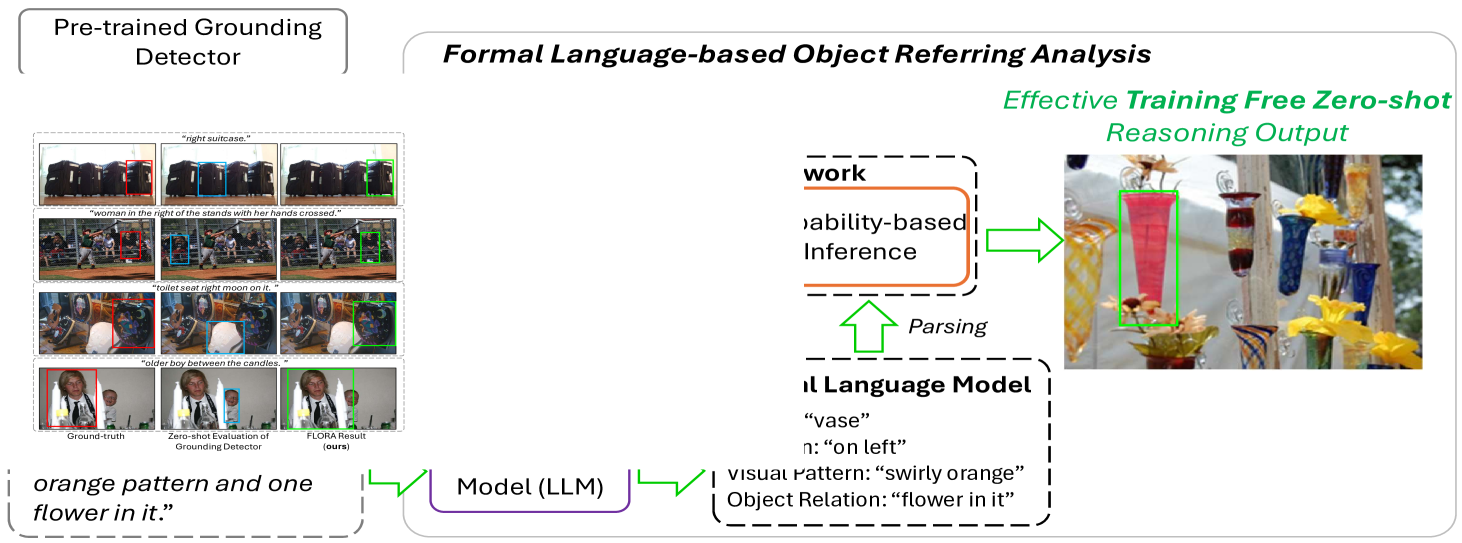


📊 实验亮点
FLORA在多个具有挑战性的数据集上进行了评估,结果表明,它在零样本ORA任务中显著优于当前最先进的方法。具体而言,FLORA将现有预训练 grounding 检测器的零样本性能提高了约45%。实验结果还表明,FLORA对LLM的幻觉具有良好的鲁棒性,能够有效地处理复杂和模糊的指代表达式。
🎯 应用场景
FLORA在机器人导航、智能监控、图像搜索、辅助驾驶等领域具有广泛的应用前景。它可以帮助机器人理解人类指令,在复杂环境中定位目标物体;可以用于智能监控系统,自动识别和跟踪特定对象;可以提升图像搜索引擎的准确性和效率;还可以应用于辅助驾驶系统,帮助车辆理解交通场景中的指代表达式。
📄 摘要(原文)
Object Referring Analysis (ORA), commonly known as referring expression comprehension, requires the identification and localization of specific objects in an image based on natural descriptions. Unlike generic object detection, ORA requires both accurate language understanding and precise visual localization, making it inherently more complex. Although recent pre-trained large visual grounding detectors have achieved significant progress, they heavily rely on extensively labeled data and time-consuming learning. To address these, we introduce a novel, training-free framework for zero-shot ORA, termed FLORA (Formal Language for Object Referring and Analysis). FLORA harnesses the inherent reasoning capabilities of large language models (LLMs) and integrates a formal language model - a logical framework that regulates language within structured, rule-based descriptions - to provide effective zero-shot ORA. More specifically, our formal language model (FLM) enables an effective, logic-driven interpretation of object descriptions without necessitating any training processes. Built upon FLM-regulated LLM outputs, we further devise a Bayesian inference framework and employ appropriate off-the-shelf interpretive models to finalize the reasoning, delivering favorable robustness against LLM hallucinations and compelling ORA performance in a training-free manner. In practice, our FLORA boosts the zero-shot performance of existing pretrained grounding detectors by up to around 45%. Our comprehensive evaluation across different challenging datasets also confirms that FLORA consistently surpasses current state-of-the-art zero-shot methods in both detection and segmentation tasks associated with zero-shot ORA. We believe our probabilistic parsing and reasoning of the LLM outputs elevate the reliability and interpretability of zero-shot ORA. We shall release codes upon publication.