Distilling Multi-modal Large Language Models for Autonomous Driving
作者: Deepti Hegde, Rajeev Yasarla, Hong Cai, Shizhong Han, Apratim Bhattacharyya, Shweta Mahajan, Litian Liu, Risheek Garrepalli, Vishal M. Patel, Fatih Porikli
分类: cs.CV, cs.RO
发布日期: 2025-01-16
💡 一句话要点
DiMA:通过知识蒸馏提升端到端自动驾驶系统效率与安全性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 知识蒸馏 大型语言模型 多模态学习 端到端规划
📋 核心要点
- 端到端自动驾驶系统依赖LLM进行规划,但在实际部署时,LLM的计算成本过高,限制了其应用。
- DiMA通过知识蒸馏,将多模态LLM的知识迁移到高效的视觉规划器,推理时无需LLM,降低计算负担。
- 实验表明,DiMA显著降低了轨迹误差和碰撞率,并在长尾场景和nuScenes基准测试中取得了优异的性能。
📝 摘要(中文)
自动驾驶需要安全的运动规划,尤其是在关键的“长尾”场景中。最近的端到端自动驾驶系统利用大型语言模型(LLM)作为规划器,以提高对罕见事件的泛化能力。然而,在测试时使用LLM会带来很高的计算成本。为了解决这个问题,我们提出了DiMA,一个端到端自动驾驶系统,它保持了无LLM(或基于视觉)规划器的效率,同时利用了LLM的世界知识。DiMA通过一组专门设计的代理任务,将来自多模态LLM的信息提炼到基于视觉的端到端规划器中。在联合训练策略下,一个场景编码器(对两个网络通用)产生语义上接地的结构化表示,并与最终的规划目标对齐。值得注意的是,LLM在推理时是可选的,从而能够在不影响效率的情况下实现鲁棒的规划。使用DiMA进行训练,可使基于视觉的规划器的L2轨迹误差减少37%,碰撞率降低80%,并且在长尾场景中轨迹误差减少44%。DiMA还在nuScenes规划基准上实现了最先进的性能。
🔬 方法详解
问题定义:现有端到端自动驾驶系统利用大型语言模型(LLM)进行规划,以提升对罕见场景的泛化能力。然而,在实际部署时,LLM的计算成本过高,导致推理效率低下,难以满足实时性要求。因此,如何在保持LLM的知识优势的同时,降低计算成本,是当前端到端自动驾驶系统面临的关键问题。
核心思路:DiMA的核心思路是通过知识蒸馏,将多模态LLM的知识迁移到高效的视觉规划器中。具体来说,DiMA设计了一系列代理任务,引导视觉规划器学习LLM的决策逻辑和世界知识。通过联合训练,视觉规划器能够生成与LLM相似的规划结果,从而在推理时摆脱对LLM的依赖,实现高效的自动驾驶。
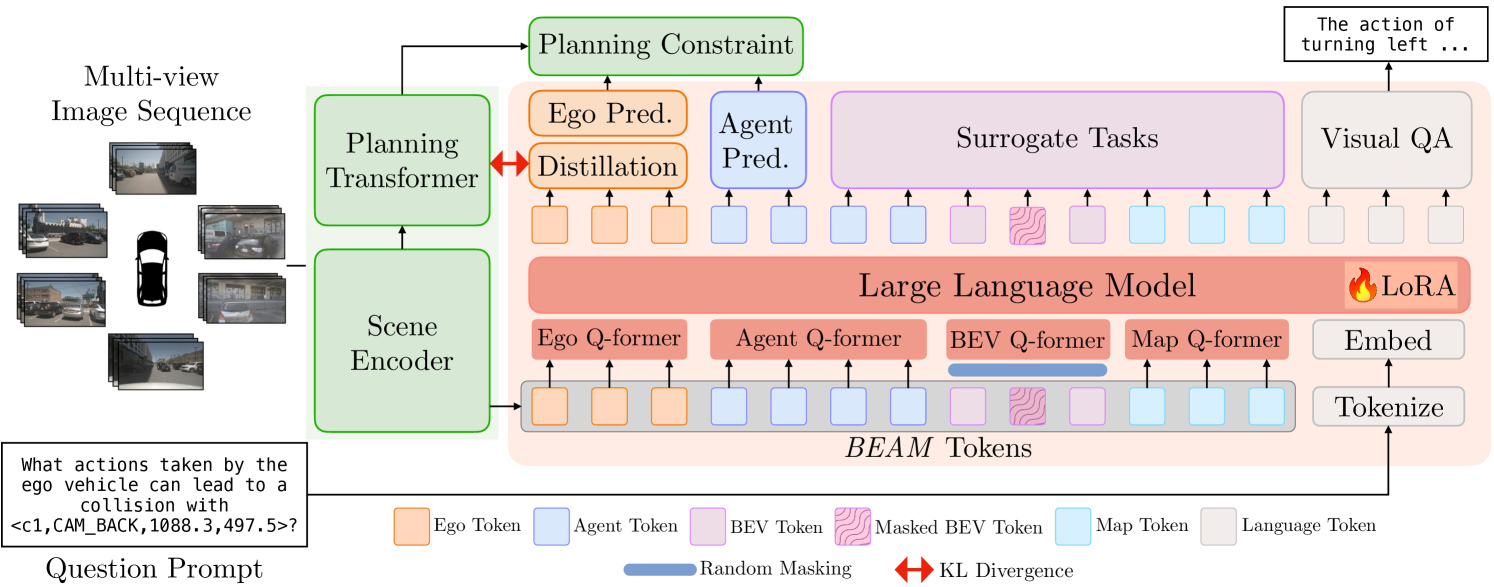
技术框架:DiMA包含一个多模态LLM(教师模型)和一个基于视觉的端到端规划器(学生模型)。整体流程如下:1) 使用多模态LLM对场景进行理解和规划,生成轨迹作为指导。2) 使用场景编码器提取场景的结构化表示,该编码器对LLM和视觉规划器是通用的。3) 通过代理任务,例如轨迹预测、行为预测等,引导视觉规划器学习LLM的规划策略。4) 采用联合训练策略,同时优化场景编码器和视觉规划器,使得场景表示既能反映场景的语义信息,又能与最终的规划目标对齐。在推理阶段,仅使用视觉规划器进行规划,无需LLM。
关键创新:DiMA的关键创新在于其知识蒸馏方法,它通过精心设计的代理任务,有效地将多模态LLM的知识迁移到视觉规划器中。与传统的知识蒸馏方法不同,DiMA的代理任务不仅关注最终的规划结果,还关注中间的决策过程,例如行为预测等。此外,DiMA采用联合训练策略,使得场景编码器能够生成更具语义信息的场景表示,从而提升了视觉规划器的性能。
关键设计:DiMA的关键设计包括:1) 场景编码器:采用Transformer结构,用于提取场景的结构化表示。2) 代理任务:包括轨迹预测、行为预测等,用于引导视觉规划器学习LLM的规划策略。3) 损失函数:采用L2损失函数和交叉熵损失函数,分别用于优化轨迹预测和行为预测。4) 训练策略:采用联合训练策略,同时优化场景编码器和视觉规划器。
🖼️ 关键图片


📊 实验亮点
DiMA在nuScenes规划基准上取得了state-of-the-art的性能。与基线方法相比,DiMA使基于视觉的规划器的L2轨迹误差减少了37%,碰撞率降低了80%,并且在长尾场景中轨迹误差减少了44%。这些结果表明,DiMA能够有效地将LLM的知识迁移到视觉规划器中,从而提升自动驾驶系统的性能和安全性。
🎯 应用场景
DiMA的研究成果可应用于各种自动驾驶场景,尤其是在计算资源受限的边缘设备上。通过知识蒸馏,DiMA能够在保证安全性的前提下,显著降低自动驾驶系统的计算成本,加速自动驾驶技术的落地。此外,DiMA的知识迁移方法也可以推广到其他机器人领域,例如无人机、服务机器人等,提升其智能化水平。
📄 摘要(原文)
Autonomous driving demands safe motion planning, especially in critical "long-tail" scenarios. Recent end-to-end autonomous driving systems leverage large language models (LLMs) as planners to improve generalizability to rare events. However, using LLMs at test time introduces high computational costs. To address this, we propose DiMA, an end-to-end autonomous driving system that maintains the efficiency of an LLM-free (or vision-based) planner while leveraging the world knowledge of an LLM. DiMA distills the information from a multi-modal LLM to a vision-based end-to-end planner through a set of specially designed surrogate tasks. Under a joint training strategy, a scene encoder common to both networks produces structured representations that are semantically grounded as well as aligned to the final planning objective. Notably, the LLM is optional at inference, enabling robust planning without compromising on efficiency. Training with DiMA results in a 37% reduction in the L2 trajectory error and an 80% reduction in the collision rate of the vision-based planner, as well as a 44% trajectory error reduction in longtail scenarios. DiMA also achieves state-of-the-art performance on the nuScenes planning benchmark.