Text-driven Adaptation of Foundation Models for Few-shot Surgical Workflow Analysis
作者: Tingxuan Chen, Kun Yuan, Vinkle Srivastav, Nassir Navab, Nicolas Padoy
分类: cs.CV, cs.AI
发布日期: 2025-01-16 (更新: 2025-03-03)
🔗 代码/项目: GITHUB
💡 一句话要点
提出Surg-FTDA,用于少量样本的手术流程分析,降低数据依赖。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 手术流程分析 少量样本学习 文本驱动自适应 模态对齐 深度学习
📋 核心要点
- 现有手术流程分析方法依赖大量标注数据,面临成本高、扩展性差和依赖专家标注的挑战。
- Surg-FTDA通过少量样本选择的模态对齐和文本驱动的自适应,减少对配对图像-文本数据的依赖。
- 实验结果表明,Surg-FTDA在图像描述、三元组识别和阶段识别等任务上优于基线方法。
📝 摘要(中文)
本研究旨在解决手术流程分析中对大规模标注数据集的依赖问题,这些数据集成本高昂、可扩展性差,且依赖专家标注。为此,我们提出了Surg-FTDA(少量样本文本驱动的自适应方法),旨在用最少的图像-标签配对数据处理各种手术流程分析任务。我们的方法包含两个关键组成部分:首先,基于少量样本选择的模态对齐,选择一小部分图像,并将其嵌入与下游任务的文本嵌入对齐,从而弥合模态差距。其次,文本驱动的自适应仅利用文本数据来训练解码器,无需配对的图像-文本数据。然后,将此解码器应用于对齐的图像嵌入,从而无需显式的图像-文本对即可执行与图像相关的任务。在生成任务(图像描述)和判别任务(三元组识别和阶段识别)上的评估结果表明,Surg-FTDA优于基线方法,并且在下游任务中具有良好的泛化能力。我们提出了一种文本驱动的自适应方法,该方法减轻了模态差距,并以最小的对大型带注释数据集的依赖性来处理手术工作流程分析中的多个下游任务。
🔬 方法详解
问题定义:手术流程分析旨在提高手术效率和安全性,但现有方法严重依赖大规模标注数据集。这些数据集的构建成本高昂,可扩展性差,并且需要领域专家的手动标注,限制了其在实际场景中的应用。因此,如何利用少量标注数据甚至无标注数据进行有效的手术流程分析是一个亟待解决的问题。
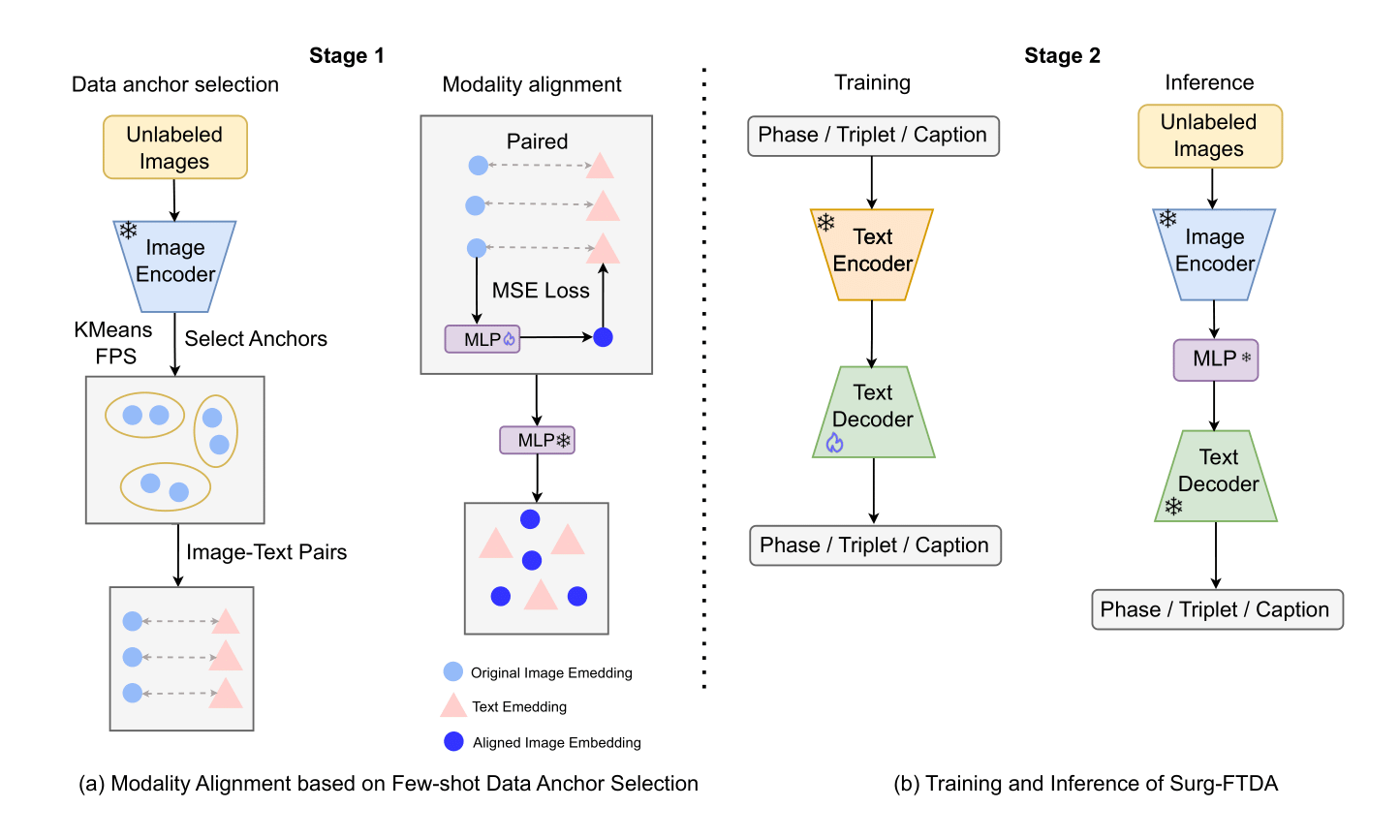
核心思路:Surg-FTDA的核心思路是利用文本信息作为桥梁,将图像特征与下游任务联系起来,从而减少对图像-标签配对数据的依赖。具体来说,该方法首先通过少量样本选择进行模态对齐,然后利用文本数据训练解码器,实现文本驱动的自适应。这种设计能够有效地利用文本信息,弥合图像和文本之间的模态差距,从而实现少量样本甚至无样本的手术流程分析。
技术框架:Surg-FTDA的整体框架包含两个主要模块:1) 少量样本选择的模态对齐:该模块从少量标注数据中选择最具代表性的样本,并将这些样本的图像嵌入与下游任务的文本嵌入对齐。2) 文本驱动的自适应:该模块利用大量的文本数据训练一个解码器,该解码器能够将图像嵌入转换为下游任务所需的输出。整个流程首先使用少量图像数据和文本数据进行模态对齐,然后仅使用文本数据训练解码器,最后将训练好的解码器应用于对齐的图像嵌入,完成下游任务。
关键创新:Surg-FTDA最重要的技术创新点在于其文本驱动的自适应方法。与传统的依赖大量图像-文本配对数据的方法不同,Surg-FTDA仅利用文本数据训练解码器,从而大大减少了对标注数据的需求。此外,该方法通过少量样本选择进行模态对齐,有效地弥合了图像和文本之间的模态差距,提高了模型的泛化能力。
关键设计:在少量样本选择的模态对齐模块中,可以使用不同的选择策略,例如基于聚类的选择或基于信息量的选择。在文本驱动的自适应模块中,可以使用不同的解码器结构,例如Transformer解码器或LSTM解码器。损失函数的设计也至关重要,可以使用对比损失或三元组损失来优化模态对齐,并使用交叉熵损失或均方误差损失来训练解码器。具体的参数设置需要根据具体的任务和数据集进行调整。
🖼️ 关键图片


📊 实验亮点
Surg-FTDA在图像描述、三元组识别和阶段识别等任务上进行了评估,实验结果表明,该方法优于现有的基线方法。具体性能提升数据在论文中给出,证明了Surg-FTDA在少量样本手术流程分析方面的有效性和泛化能力。该方法显著降低了对大规模标注数据的依赖,具有重要的实际应用价值。
🎯 应用场景
Surg-FTDA可应用于多种手术流程分析任务,如手术阶段识别、手术步骤预测、手术风险评估等。该研究成果有助于降低手术流程分析的成本,提高手术效率和安全性,并为智能手术机器人的研发提供技术支持。未来,该方法有望推广到其他医疗图像分析领域,例如疾病诊断和治疗方案制定。
📄 摘要(原文)
Purpose: Surgical workflow analysis is crucial for improving surgical efficiency and safety. However, previous studies rely heavily on large-scale annotated datasets, posing challenges in cost, scalability, and reliance on expert annotations. To address this, we propose Surg-FTDA (Few-shot Text-driven Adaptation), designed to handle various surgical workflow analysis tasks with minimal paired image-label data. Methods: Our approach has two key components. First, Few-shot selection-based modality alignment selects a small subset of images and aligns their embeddings with text embeddings from the downstream task, bridging the modality gap. Second, Text-driven adaptation leverages only text data to train a decoder, eliminating the need for paired image-text data. This decoder is then applied to aligned image embeddings, enabling image-related tasks without explicit image-text pairs. Results: We evaluate our approach to generative tasks (image captioning) and discriminative tasks (triplet recognition and phase recognition). Results show that Surg-FTDA outperforms baselines and generalizes well across downstream tasks. Conclusion: We propose a text-driven adaptation approach that mitigates the modality gap and handles multiple downstream tasks in surgical workflow analysis, with minimal reliance on large annotated datasets. The code and dataset will be released in https://github.com/CAMMA-public/Surg-FTDA