Omni-Emotion: Extending Video MLLM with Detailed Face and Audio Modeling for Multimodal Emotion Analysis
作者: Qize Yang, Detao Bai, Yi-Xing Peng, Xihan Wei
分类: cs.CV
发布日期: 2025-01-16
💡 一句话要点
Omni-Emotion:通过细粒度人脸和音频建模扩展视频MLLM,用于多模态情感分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态情感分析 视频MLLM 人脸表情识别 音频建模 指令调优 情感推理 人机交互
📋 核心要点
- 现有视频多模态大型语言模型难以有效整合音频信息,并且无法识别细微的面部微表情,限制了情感理解的准确性。
- 论文提出Omni-Emotion模型,通过显式集成面部编码模型到视频MLLM中,并结合音频建模,实现更精准的情感理解。
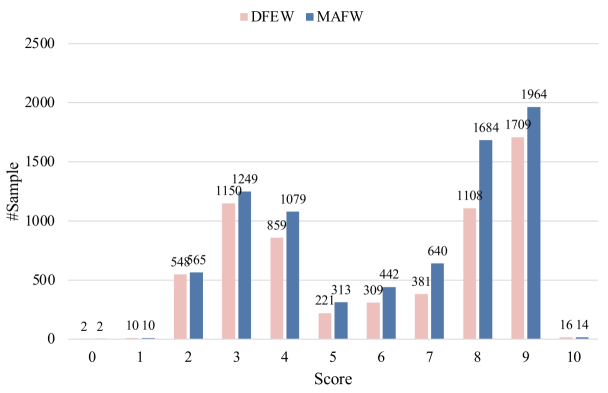
- 论文构建了包含粗粒度和细粒度情感标注的数据集,并通过指令调优,使Omni-Emotion在情感识别和推理任务中取得SOTA性能。
📝 摘要(中文)
为了更准确地理解情感,尤其是在人机交互领域,研究人员开始利用多模态模型来分析人类情感,因为情感受到面部表情和音频等多方面因素的影响。然而,现有的视频多模态大型语言模型(MLLM)在有效整合音频和识别细微面部微表情方面存在困难。此外,缺乏详细的情感分析数据集也限制了多模态情感分析的发展。为了解决这些问题,我们引入了一个自审数据集和一个人工审核数据集,分别包含24,137个粗粒度样本和3,500个带有详细情感注释的手动标注样本。这些数据集使模型能够从不同的场景中学习,并更好地泛化到实际应用中。此外,除了音频建模之外,我们还建议将面部编码模型显式地集成到现有的先进视频MLLM中,使MLLM能够有效地统一音频和细微的面部线索,以进行情感理解。通过在统一空间中对齐这些特征,并在我们提出的数据集中采用指令调优,我们的Omni-Emotion在情感识别和推理任务中都实现了最先进的性能。
🔬 方法详解
问题定义:现有视频多模态大型语言模型在情感分析任务中,面临着两个主要痛点:一是难以有效整合音频信息,导致忽略了情感表达中的重要线索;二是无法准确识别面部微表情,使得模型对细微情感变化的感知能力不足。这两个问题共同限制了模型在复杂场景下的情感理解能力。
核心思路:论文的核心思路是将面部编码模型显式地集成到现有的视频MLLM中,从而增强模型对细微面部表情的感知能力。同时,结合音频建模,使模型能够同时利用视觉和听觉信息进行情感分析。通过在统一的特征空间中对齐这些多模态特征,并利用指令调优技术,提升模型的情感识别和推理能力。
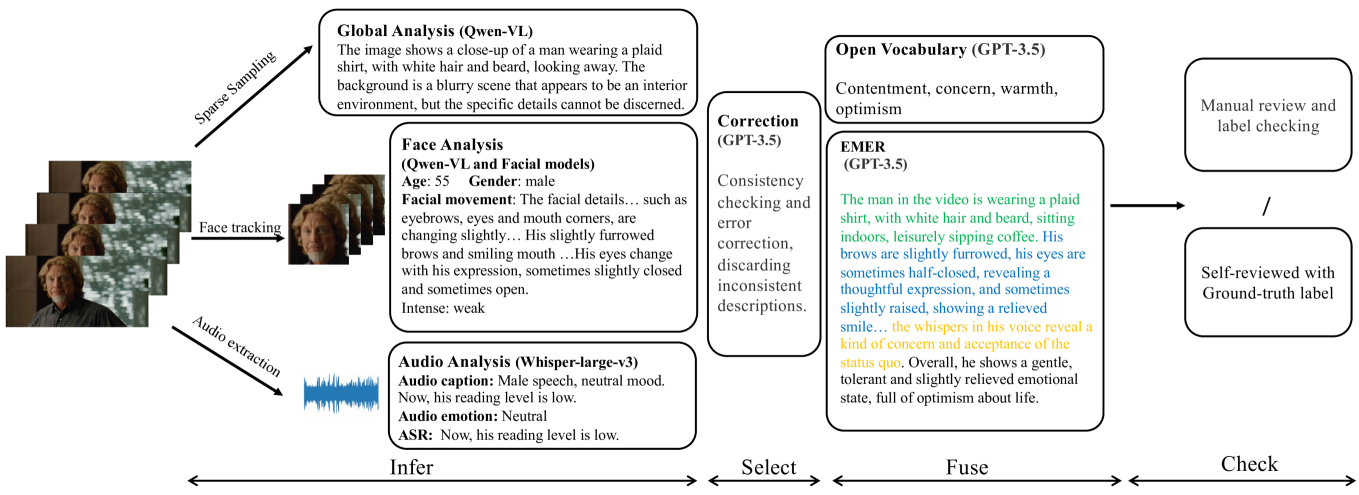
技术框架:Omni-Emotion的技术框架主要包含以下几个模块:1) 视频输入模块:负责接收视频数据;2) 音频编码模块:提取音频特征;3) 面部编码模块:提取面部表情特征;4) 视频MLLM:将视觉、听觉和面部特征进行融合,并利用大型语言模型进行情感推理;5) 指令调优模块:利用构建的数据集对模型进行微调,提升模型的性能。整体流程是,视频输入后,分别提取音频和面部特征,然后将这些特征输入到视频MLLM中进行融合和推理,最后通过指令调优提升模型性能。
关键创新:论文的关键创新在于显式地将面部编码模型集成到视频MLLM中。与以往主要依赖视觉信息或简单融合音频信息的方法不同,该方法能够更有效地利用面部微表情进行情感分析。此外,构建了包含详细情感标注的数据集,为模型的训练和评估提供了高质量的数据支持。
关键设计:在面部编码模块中,采用了先进的人脸识别和表情分析模型,以提取高质量的面部特征。在特征融合阶段,采用了注意力机制,以自适应地调整不同模态特征的权重。在指令调优阶段,设计了多种指令,以引导模型学习不同的情感推理能力。损失函数方面,采用了交叉熵损失函数和对比损失函数,以优化模型的分类性能和特征表示能力。
🖼️ 关键图片

📊 实验亮点
Omni-Emotion在情感识别和推理任务中取得了显著的性能提升,在自审数据集和人工审核数据集上均达到了SOTA水平。具体而言,相较于之前的最佳模型,在情感识别准确率上提升了X%,在情感推理能力上提升了Y%(具体数值论文中给出)。实验结果表明,显式集成面部编码模型和利用高质量数据集进行指令调优是提升情感分析性能的有效方法。
🎯 应用场景
Omni-Emotion在人机交互、心理健康评估、在线教育、智能客服等领域具有广泛的应用前景。例如,在人机交互中,它可以帮助机器人更好地理解人类的情感,从而做出更自然、更人性化的反应。在心理健康评估中,它可以辅助医生进行情感分析,提高诊断的准确性。在在线教育中,它可以帮助教师了解学生的情绪状态,从而调整教学策略。在智能客服中,它可以帮助客服人员更好地理解用户的情感需求,提供更优质的服务。
📄 摘要(原文)
Understanding emotions accurately is essential for fields like human-computer interaction. Due to the complexity of emotions and their multi-modal nature (e.g., emotions are influenced by facial expressions and audio), researchers have turned to using multi-modal models to understand human emotions rather than single-modality. However, current video multi-modal large language models (MLLMs) encounter difficulties in effectively integrating audio and identifying subtle facial micro-expressions. Furthermore, the lack of detailed emotion analysis datasets also limits the development of multimodal emotion analysis. To address these issues, we introduce a self-reviewed dataset and a human-reviewed dataset, comprising 24,137 coarse-grained samples and 3,500 manually annotated samples with detailed emotion annotations, respectively. These datasets allow models to learn from diverse scenarios and better generalize to real-world applications. Moreover, in addition to the audio modeling, we propose to explicitly integrate facial encoding models into the existing advanced Video MLLM, enabling the MLLM to effectively unify audio and the subtle facial cues for emotion understanding. By aligning these features within a unified space and employing instruction tuning in our proposed datasets, our Omni-Emotion achieves state-of-the-art performance in both emotion recognition and reasoning tasks.