DEFOM-Stereo: Depth Foundation Model Based Stereo Matching
作者: Hualie Jiang, Zhiqiang Lou, Laiyan Ding, Rui Xu, Minglang Tan, Wenjie Jiang, Rui Huang
分类: cs.CV
发布日期: 2025-01-16 (更新: 2025-04-23)
备注: https://insta360-research-team.github.io/DEFOM-Stereo/
期刊: CVPR 2025
💡 一句话要点
DEFOM-Stereo:基于深度基础模型的立体匹配方法,提升零样本泛化能力。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 立体匹配 深度估计 深度基础模型 单目深度估计 零样本学习
📋 核心要点
- 传统立体匹配方法在遮挡和弱纹理区域表现不佳,限制了其在复杂环境中的应用。
- DEFOM-Stereo利用深度基础模型提供的单目深度线索,增强立体匹配的鲁棒性和泛化能力。
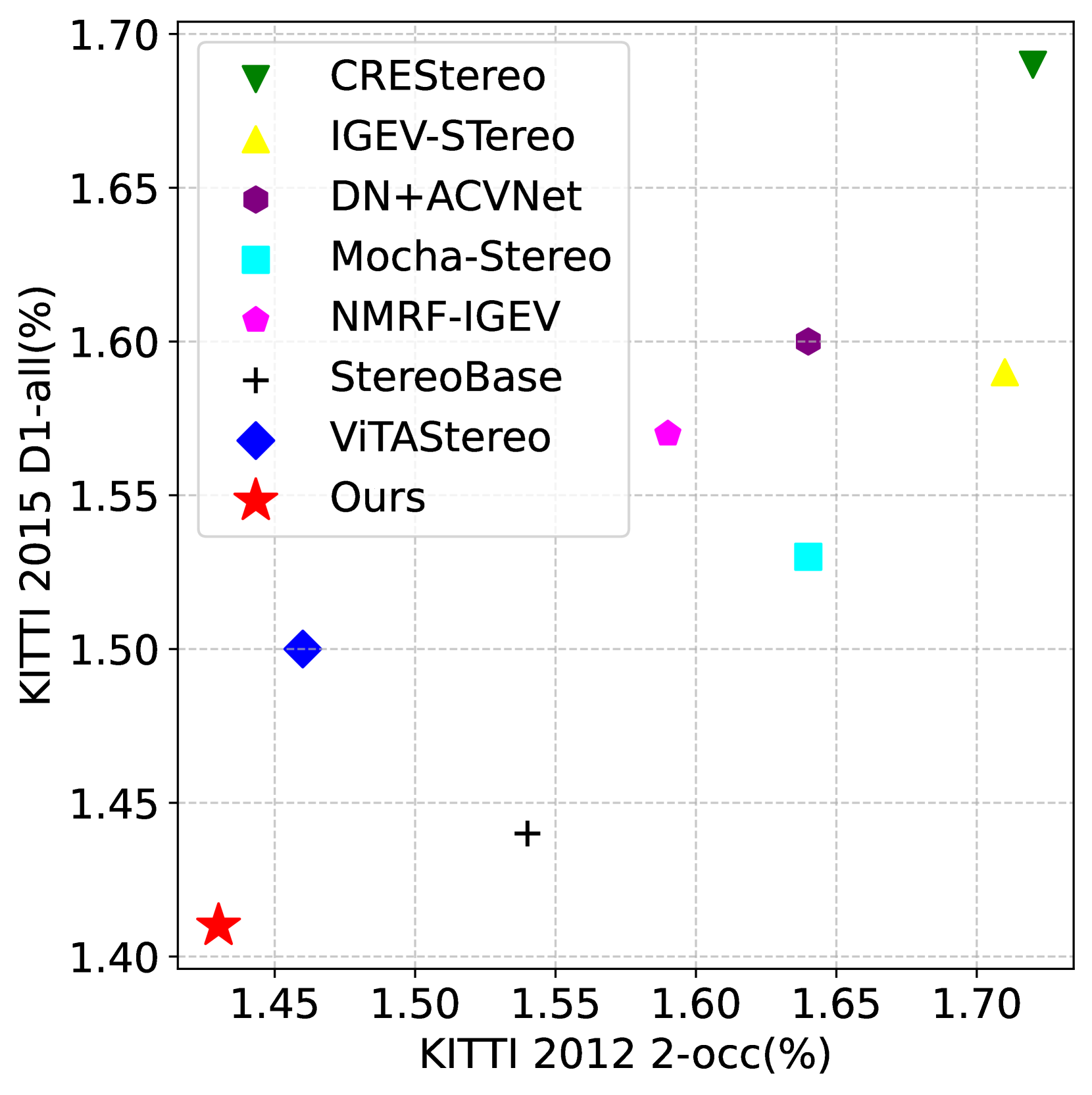
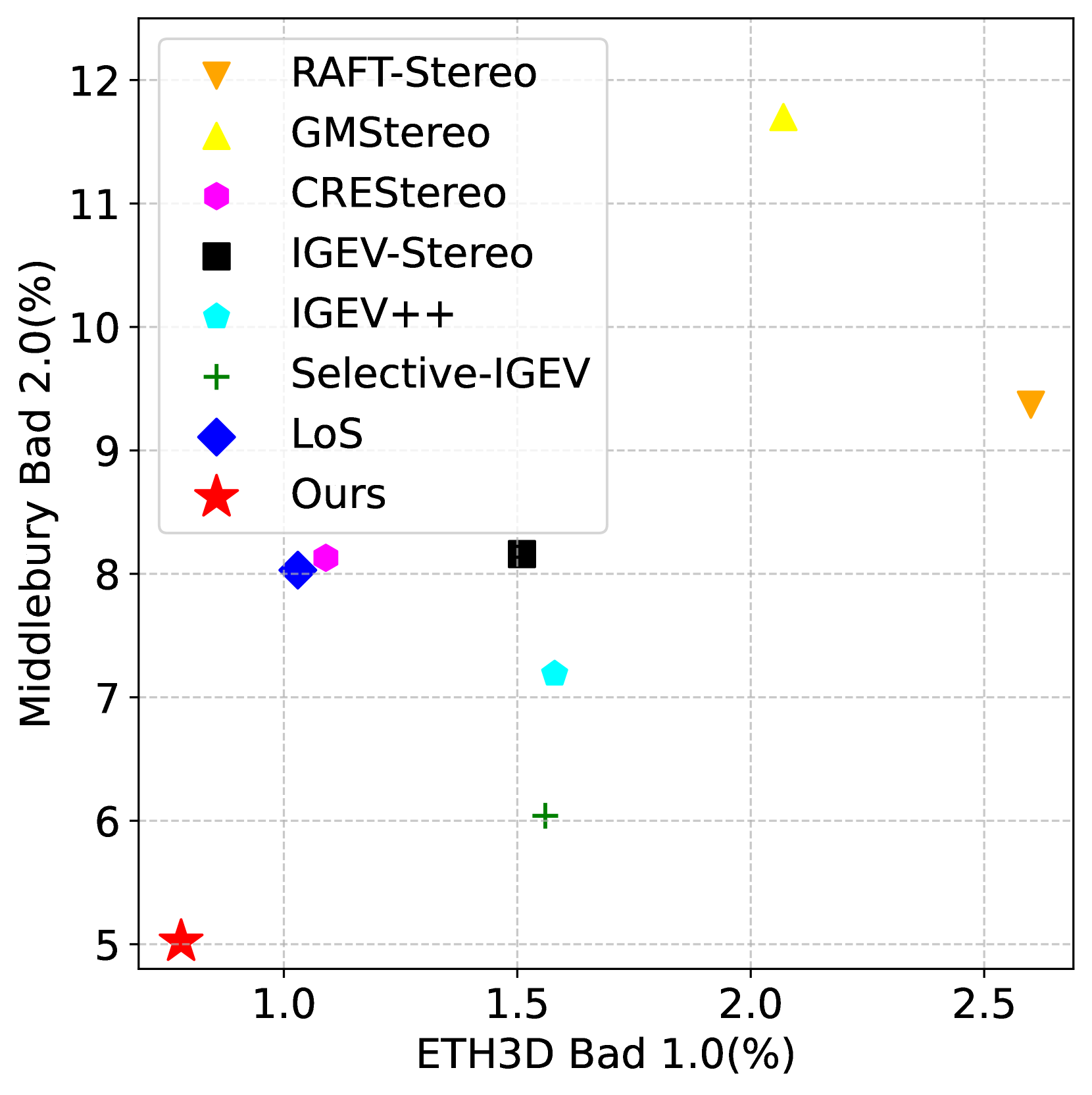
- 实验结果表明,DEFOM-Stereo在多个数据集上超越现有方法,并在零样本场景下表现出更强的泛化性。
📝 摘要(中文)
立体匹配是计算机视觉和机器人技术中用于度量深度估计的关键技术。现实世界中的遮挡和非纹理等挑战阻碍了从双目匹配线索中准确估计视差。最近,单目相对深度估计已经展示了使用视觉基础模型的卓越泛化能力。因此,为了促进具有单目深度线索的鲁棒立体匹配,我们将一个鲁棒的单目相对深度模型整合到循环立体匹配框架中,构建了一个新的基于深度基础模型的立体匹配框架,即DEFOM-Stereo。在特征提取阶段,我们通过整合来自传统CNN和DEFOM的特征,构建了组合的上下文和匹配特征编码器。在更新阶段,我们使用DEFOM预测的深度来初始化循环视差,并引入尺度更新模块来以正确的尺度细化视差。经验证,与SOTA方法相比,DEFOM-Stereo具有更强的零样本泛化能力。此外,DEFOM-Stereo在KITTI 2012、KITTI 2015、Middlebury和ETH3D基准测试中取得了最佳性能,在许多指标上排名第一。在鲁棒视觉挑战赛的联合评估中,我们的模型同时优于先前模型在各个基准测试上的表现,进一步证明了其出色的能力。
🔬 方法详解
问题定义:立体匹配旨在从左右图像中估计视差,进而计算场景深度。现有方法在遮挡、弱纹理等情况下容易失效,且泛化能力有限,难以适应未见过的场景。
核心思路:利用单目深度估计的最新进展,特别是深度基础模型(DEFOM)在单目深度估计上的强大泛化能力,将其融入到立体匹配框架中,以提供更可靠的深度先验信息,从而提升立体匹配的鲁棒性和泛化性。
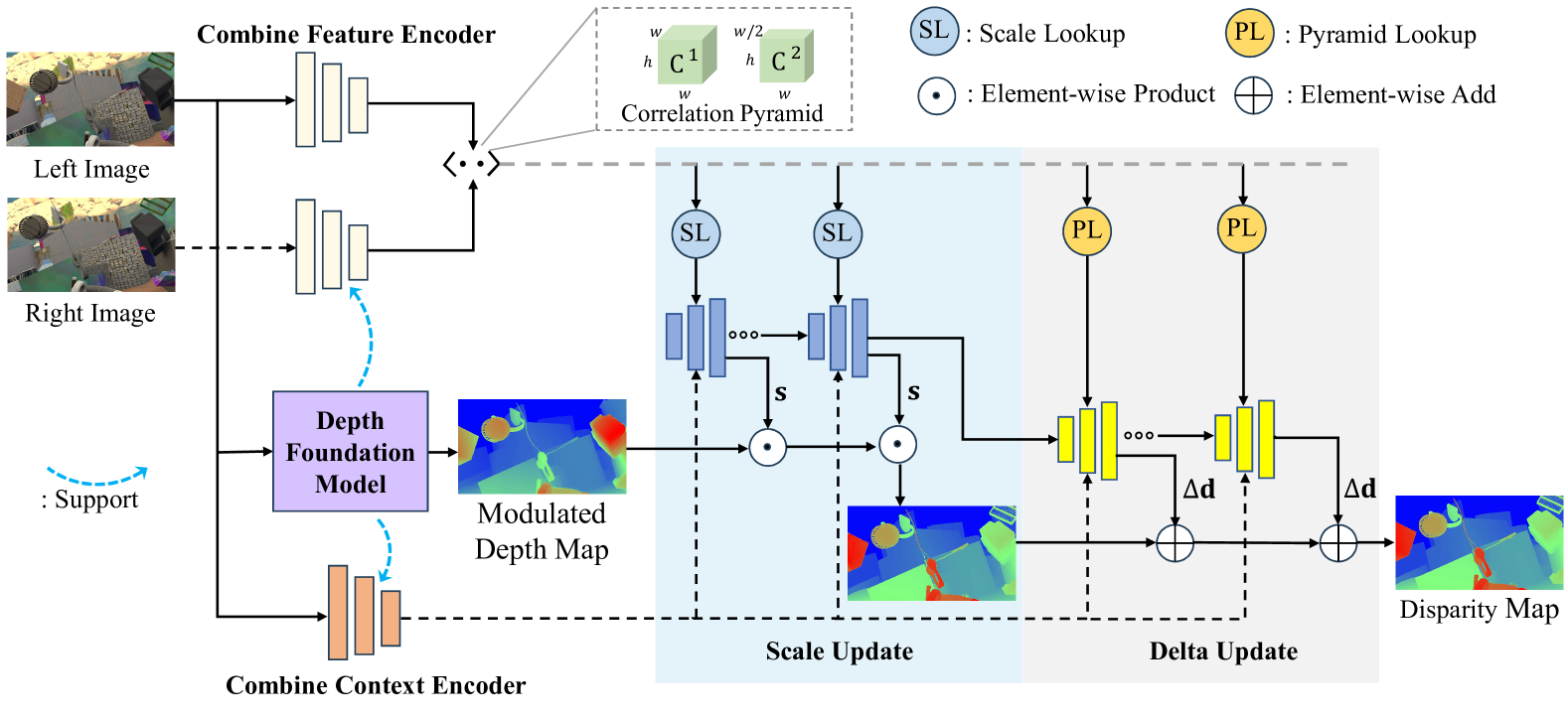
技术框架:DEFOM-Stereo包含特征提取和视差更新两个主要阶段。在特征提取阶段,使用CNN和DEFOM提取图像特征,并进行融合。在视差更新阶段,利用DEFOM的深度预测结果初始化视差,并通过循环更新和尺度调整模块逐步优化视差图。
关键创新:将单目深度基础模型引入立体匹配框架,利用其强大的单目深度估计能力来辅助立体匹配,显著提升了立体匹配的鲁棒性和零样本泛化能力。尺度更新模块的设计,能够有效修正视差的尺度,进一步提升精度。
关键设计:特征提取阶段,将CNN提取的局部特征与DEFOM提取的全局上下文特征进行融合,以获得更全面的图像表示。视差更新阶段,采用循环神经网络结构,逐步迭代优化视差图。尺度更新模块通过学习一个尺度因子来调整视差的尺度,使其与真实深度更加一致。
🖼️ 关键图片
📊 实验亮点
DEFOM-Stereo在KITTI 2012、KITTI 2015、Middlebury和ETH3D等多个数据集上取得了领先的性能,并在许多指标上排名第一。尤其值得一提的是,该方法在零样本场景下表现出显著的泛化能力提升,超越了现有的SOTA方法,证明了其在实际应用中的潜力。
🎯 应用场景
DEFOM-Stereo在机器人导航、自动驾驶、三维重建等领域具有广泛的应用前景。该方法能够提升深度估计的准确性和鲁棒性,尤其是在复杂和未知的环境中,从而提高相关系统的性能和可靠性。此外,该方法在虚拟现实、增强现实等领域也有潜在的应用价值。
📄 摘要(原文)
Stereo matching is a key technique for metric depth estimation in computer vision and robotics. Real-world challenges like occlusion and non-texture hinder accurate disparity estimation from binocular matching cues. Recently, monocular relative depth estimation has shown remarkable generalization using vision foundation models. Thus, to facilitate robust stereo matching with monocular depth cues, we incorporate a robust monocular relative depth model into the recurrent stereo-matching framework, building a new framework for depth foundation model-based stereo-matching, DEFOM-Stereo. In the feature extraction stage, we construct the combined context and matching feature encoder by integrating features from conventional CNNs and DEFOM. In the update stage, we use the depth predicted by DEFOM to initialize the recurrent disparity and introduce a scale update module to refine the disparity at the correct scale. DEFOM-Stereo is verified to have much stronger zero-shot generalization compared with SOTA methods. Moreover, DEFOM-Stereo achieves top performance on the KITTI 2012, KITTI 2015, Middlebury, and ETH3D benchmarks, ranking $1^{st}$ on many metrics. In the joint evaluation under the robust vision challenge, our model simultaneously outperforms previous models on the individual benchmarks, further demonstrating its outstanding capabilities.