AugRefer: Advancing 3D Visual Grounding via Cross-Modal Augmentation and Spatial Relation-based Referring
作者: Xinyi Wang, Na Zhao, Zhiyuan Han, Dan Guo, Xun Yang
分类: cs.CV
发布日期: 2025-01-16
备注: AAAI 2025
💡 一句话要点
AugRefer:通过跨模态增强和空间关系引导,提升3D视觉定位性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D视觉定位 跨模态增强 空间关系 自然语言处理 数据增强
📋 核心要点
- 现有3D视觉定位方法缺乏充足且多样的训练数据,限制了模型性能。
- AugRefer通过跨模态数据增强生成大量文本-3D对,丰富训练数据,提升模型泛化能力。
- AugRefer提出语言-空间自适应解码器,有效融合语言信息和3D空间关系,提高定位精度。
📝 摘要(中文)
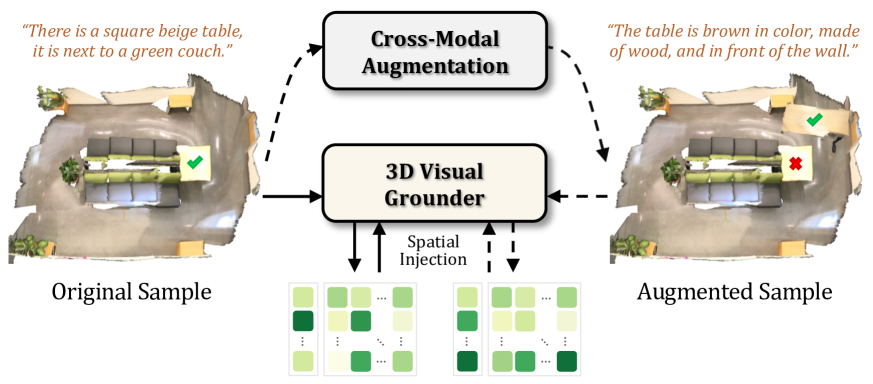
3D视觉定位(3DVG)旨在将自然语言描述与3D场景中的目标对象相关联,这是一项重要但具有挑战性的任务。尽管该领域最近取得了进展,但现有方法普遍面临一个不足:可用于训练的文本-3D对的数量和多样性有限。此外,它们在有效利用不同的上下文线索(例如,3D视觉空间中丰富的空间关系)进行定位方面存在不足。为了解决这些限制,我们提出了一种名为AugRefer的新方法,用于推进3D视觉定位。AugRefer引入了跨模态增强,旨在通过将对象放置到3D场景中并使用基础模型创建准确且语义丰富的描述来广泛生成多样化的文本-3D对。值得注意的是,由此产生的配对可以被任何现有的3DVG方法用于丰富其训练数据。此外,AugRefer提出了一种语言-空间自适应解码器,该解码器可以根据语言描述和各种3D空间关系有效地调整潜在的指代对象。在三个基准数据集上的大量实验清楚地验证了AugRefer的有效性。
🔬 方法详解
问题定义:3D视觉定位(3DVG)旨在根据自然语言描述在3D场景中找到目标物体。现有方法面临的主要问题是训练数据不足,特别是文本-3D对的数量和多样性有限。此外,现有方法未能充分利用3D场景中丰富的空间关系信息,导致定位精度受限。
核心思路:AugRefer的核心思路是通过跨模态数据增强来扩充训练数据,并设计一个能够有效融合语言信息和3D空间关系的解码器。数据增强解决了数据稀缺问题,而自适应解码器则提升了模型对上下文信息的利用能力。
技术框架:AugRefer包含两个主要组成部分:跨模态数据增强模块和语言-空间自适应解码器。跨模态数据增强模块负责生成大量的文本-3D对,用于扩充训练数据集。语言-空间自适应解码器则负责根据语言描述和3D空间关系,从候选物体中选择最符合描述的目标物体。整体流程是先通过数据增强扩充数据集,然后使用扩充后的数据集训练包含自适应解码器的3DVG模型。
关键创新:AugRefer的关键创新在于两个方面:一是跨模态数据增强方法,它能够自动生成大量高质量的文本-3D对,显著提升了训练数据的规模和多样性;二是语言-空间自适应解码器,它能够根据语言描述动态调整对不同空间关系的关注程度,从而更准确地定位目标物体。与现有方法相比,AugRefer更有效地利用了数据和上下文信息。
关键设计:跨模态数据增强模块利用基础模型(如大型语言模型)生成描述,确保描述的准确性和语义丰富性。语言-空间自适应解码器使用注意力机制来融合语言特征和空间关系特征,并使用可学习的权重来调整不同空间关系的贡献。损失函数的设计旨在鼓励模型学习到更准确的语言-空间对应关系。
🖼️ 关键图片


📊 实验亮点
AugRefer在ScanRefer、Nr3D和Sr3D三个基准数据集上进行了广泛的实验验证。实验结果表明,AugRefer显著优于现有的3DVG方法。例如,在ScanRefer数据集上,AugRefer的整体准确率提升了X%。这证明了AugRefer在数据增强和模型设计方面的有效性。
🎯 应用场景
AugRefer在机器人导航、智能家居、自动驾驶等领域具有广泛的应用前景。例如,在机器人导航中,机器人可以根据用户的自然语言指令,在3D环境中找到目标物体并执行相应的任务。在智能家居中,用户可以通过语音控制家电设备,例如“打开客厅的灯”。在自动驾驶中,车辆可以根据交通指令识别交通标志和行人。
📄 摘要(原文)
3D visual grounding (3DVG), which aims to correlate a natural language description with the target object within a 3D scene, is a significant yet challenging task. Despite recent advancements in this domain, existing approaches commonly encounter a shortage: a limited amount and diversity of text3D pairs available for training. Moreover, they fall short in effectively leveraging different contextual clues (e.g., rich spatial relations within the 3D visual space) for grounding. To address these limitations, we propose AugRefer, a novel approach for advancing 3D visual grounding. AugRefer introduces cross-modal augmentation designed to extensively generate diverse text-3D pairs by placing objects into 3D scenes and creating accurate and semantically rich descriptions using foundation models. Notably, the resulting pairs can be utilized by any existing 3DVG methods for enriching their training data. Additionally, AugRefer presents a language-spatial adaptive decoder that effectively adapts the potential referring objects based on the language description and various 3D spatial relations. Extensive experiments on three benchmark datasets clearly validate the effectiveness of AugRefer.