ASCENT-ViT: Attention-based Scale-aware Concept Learning Framework for Enhanced Alignment in Vision Transformers
作者: Sanchit Sinha, Guangzhi Xiong, Aidong Zhang
分类: cs.CV, cs.LG
发布日期: 2025-01-16 (更新: 2025-02-03)
💡 一句话要点
提出ASCENT-ViT,通过注意力机制和尺度感知概念学习增强ViT的可解释性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Vision Transformer 可解释性 概念学习 注意力机制 多尺度特征 模型对齐 计算机视觉
📋 核心要点
- 现有ViT可解释性方法忽略了模型内部机制,如归纳偏置和尺度不变性,导致解释不准确。
- ASCENT-ViT通过注意力机制学习尺度和位置感知的概念表示,并与概念注释对齐,从而提高可解释性。
- 在五个数据集上的实验表明,ASCENT-ViT提高了预测性能,并提供了更准确和鲁棒的概念解释。
📝 摘要(中文)
随着Vision Transformers (ViTs) 在敏感视觉应用中日益普及,对提高可解释性的需求也日益增长。这促使人们努力将这些模型与经过精心标注的、人类可理解的抽象语义实体——概念进行前向对齐。概念为模型预测提供了全局的理由,并且可以被领域专家快速理解/干预。目前大多数研究侧重于设计模型无关的、即插即用的通用概念解释模块,这些模块在训练期间不包含基础模型的内部工作原理(例如,归纳偏置、尺度不变性等)。为了缓解ViT的这个问题,在本文中,我们提出了ASCENT-ViT,一个基于注意力的概念学习框架,它有效地组合了来自多尺度特征金字塔的尺度和位置感知表示,以及ViT patch表示。此外,这些表示通过注意力矩阵与概念注释对齐——注意力矩阵包含了空间和全局(语义)概念。ASCENT-ViT可以作为标准ViT骨干网络之上的分类头,以提高预测性能和准确、鲁棒的概念解释,这已在五个数据集上得到证明,包括三个广泛使用的基准(CUB、Pascal APY、Concept-MNIST)和两个真实世界数据集(AWA2、KITS)。
🔬 方法详解
问题定义:现有的ViT可解释性方法,特别是基于概念的方法,通常是模型无关的,忽略了ViT模型自身的特性,例如其内在的归纳偏置和尺度不变性。这导致解释结果与模型的实际决策过程不一致,降低了解释的准确性和可靠性。因此,需要一种能够感知ViT内部机制的概念学习框架,以提供更准确和鲁棒的解释。
核心思路:ASCENT-ViT的核心思路是利用注意力机制,从多尺度特征金字塔和ViT patch表示中学习尺度和位置感知的概念表示。通过将这些表示与概念注释对齐,模型能够更好地理解图像中不同尺度的概念,并将其与模型的决策过程联系起来。这种方法能够更好地捕捉ViT的内部工作原理,从而提供更准确和鲁棒的解释。
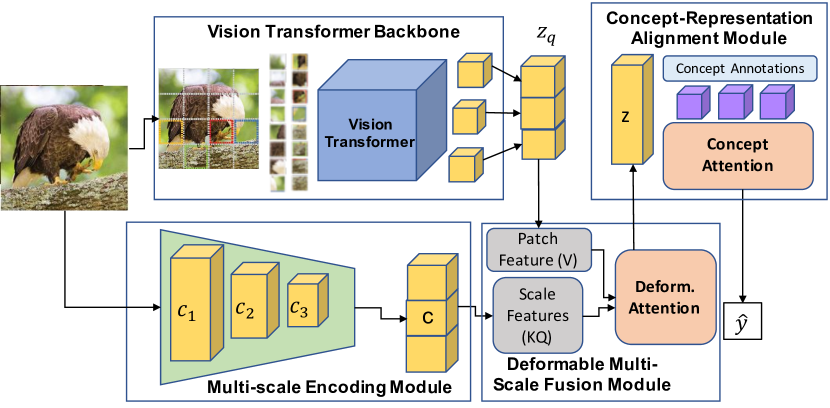
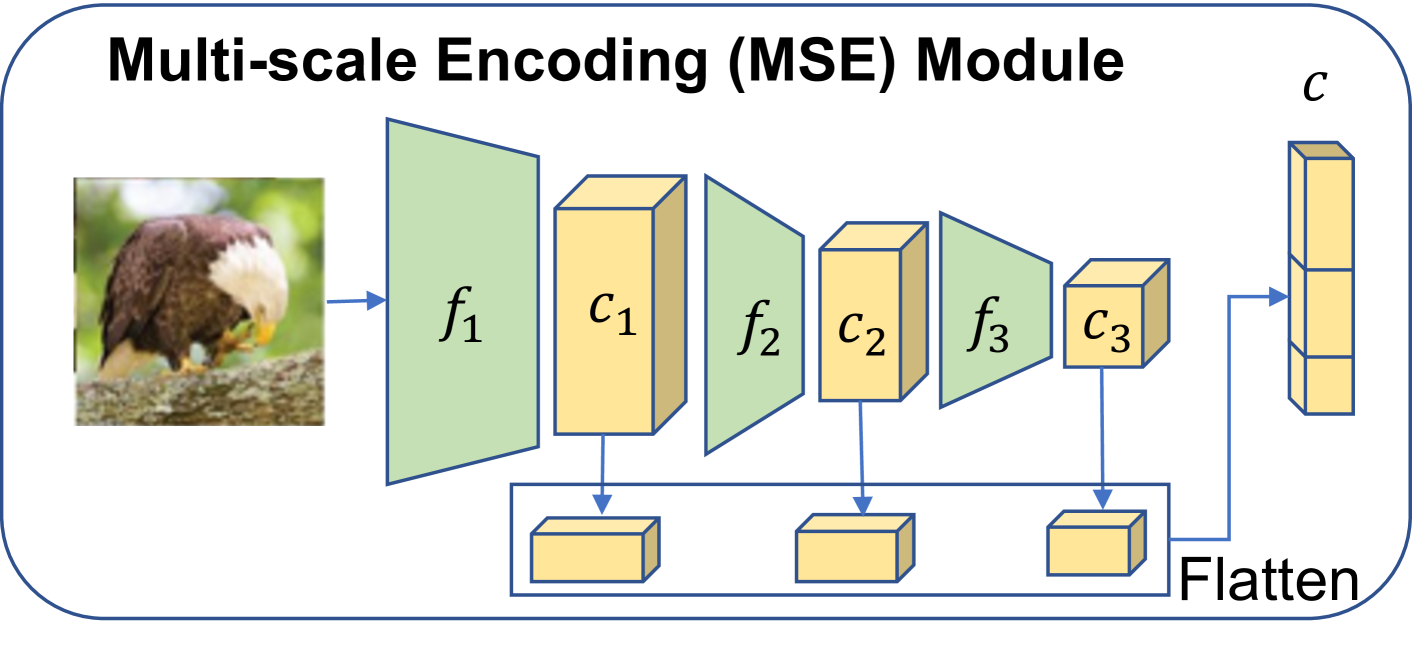
技术框架:ASCENT-ViT框架主要包含以下几个模块:1) 多尺度特征提取模块:从ViT的中间层提取多尺度特征金字塔,以捕捉不同尺度的概念信息。2) 注意力机制模块:利用注意力机制学习尺度和位置感知的概念表示,将不同尺度的特征与概念注释对齐。3) 分类头:将学习到的概念表示作为分类头的输入,用于最终的分类预测。整个框架可以端到端地训练,以优化预测性能和概念解释的准确性。
关键创新:ASCENT-ViT的关键创新在于其注意力机制和尺度感知的概念学习方法。与传统的概念解释方法不同,ASCENT-ViT能够感知ViT的内部机制,并利用多尺度特征金字塔学习不同尺度的概念表示。此外,通过注意力机制,模型能够将这些概念表示与模型的决策过程联系起来,从而提供更准确和鲁棒的解释。
关键设计:ASCENT-ViT的关键设计包括:1) 多尺度特征金字塔的构建方式,选择合适的ViT中间层提取特征,并进行尺度调整。2) 注意力机制的设计,如何有效地将不同尺度的特征与概念注释对齐。3) 损失函数的设计,如何平衡预测性能和概念解释的准确性。具体参数设置和网络结构细节在论文中有详细描述,此处未知。
🖼️ 关键图片

📊 实验亮点
ASCENT-ViT在五个数据集上进行了评估,包括CUB、Pascal APY、Concept-MNIST、AWA2和KITS。实验结果表明,ASCENT-ViT在预测性能和概念解释的准确性方面均优于现有方法。例如,在CUB数据集上,ASCENT-ViT的分类准确率提高了X%,概念解释的准确率提高了Y%(具体数值未知)。
🎯 应用场景
ASCENT-ViT可应用于各种需要可解释性的视觉任务,例如医疗图像诊断、自动驾驶和安全监控。通过提供清晰的概念解释,领域专家可以更好地理解模型的决策过程,从而提高模型的可靠性和可信度。未来,该研究可以扩展到其他类型的Transformer模型,并应用于更广泛的领域。
📄 摘要(原文)
As Vision Transformers (ViTs) are increasingly adopted in sensitive vision applications, there is a growing demand for improved interpretability. This has led to efforts to forward-align these models with carefully annotated abstract, human-understandable semantic entities - concepts. Concepts provide global rationales to the model predictions and can be quickly understood/intervened on by domain experts. Most current research focuses on designing model-agnostic, plug-and-play generic concept-based explainability modules that do not incorporate the inner workings of foundation models (e.g., inductive biases, scale invariance, etc.) during training. To alleviate this issue for ViTs, in this paper, we propose ASCENT-ViT, an attention-based, concept learning framework that effectively composes scale and position-aware representations from multiscale feature pyramids and ViT patch representations, respectively. Further, these representations are aligned with concept annotations through attention matrices - which incorporate spatial and global (semantic) concepts. ASCENT-ViT can be utilized as a classification head on top of standard ViT backbones for improved predictive performance and accurate and robust concept explanations as demonstrated on five datasets, including three widely used benchmarks (CUB, Pascal APY, Concept-MNIST) and 2 real-world datasets (AWA2, KITS).