BloomScene: Lightweight Structured 3D Gaussian Splatting for Crossmodal Scene Generation
作者: Xiaolu Hou, Mingcheng Li, Dingkang Yang, Jiawei Chen, Ziyun Qian, Xiao Zhao, Yue Jiang, Jinjie Wei, Qingyao Xu, Lihua Zhang
分类: cs.CV, cs.AI, cs.GR, cs.LG
发布日期: 2025-01-15 (更新: 2025-09-01)
备注: Accepted by AAAI 2025. Code: https://github.com/SparklingH/BloomScene
💡 一句话要点
BloomScene:轻量级结构化3D高斯溅射用于跨模态场景生成
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D场景生成 高斯溅射 跨模态学习 点云重建 深度先验
📋 核心要点
- 现有3D场景生成方法依赖预训练模型,存在存储空间大、几何失真等问题,缺乏有效的正则化手段。
- BloomScene提出跨模态渐进式场景生成框架,结合增量点云重建和3D高斯溅射,生成连贯场景。
- 实验表明,BloomScene在多个场景下表现出显著的潜力和优势,优于现有基线方法。
📝 摘要(中文)
随着虚拟现实应用的普及,3D场景生成已成为一项具有挑战性的新兴研究领域。3D场景具有高度复杂的结构,需要确保输出是密集的、连贯的,并且包含所有必要的结构。目前许多3D场景生成方法依赖于预训练的文本到图像扩散模型和单目深度估计器。然而,生成的场景占用大量的存储空间,并且常常缺乏有效的正则化方法,导致几何失真。为此,我们提出了BloomScene,一种用于跨模态场景生成的轻量级结构化3D高斯溅射方法,它可以从文本或图像输入创建多样且高质量的3D场景。具体来说,我们提出了一个跨模态渐进式场景生成框架,该框架利用增量点云重建和3D高斯溅射来生成连贯的场景。此外,我们提出了一种基于分层深度先验的正则化机制,该机制利用对深度精度和平滑度的多级约束来增强生成场景的真实性和连续性。最后,我们提出了一种结构化上下文引导的压缩机制,该机制利用结构化哈希网格来建模非结构化锚点属性的上下文,从而显著消除结构冗余并减少存储开销。跨多个场景的综合实验证明了我们的框架与几个基线相比具有显著的潜力和优势。
🔬 方法详解
问题定义:现有3D场景生成方法依赖于预训练的文本到图像扩散模型和单目深度估计器,导致生成的场景占用大量存储空间,并且缺乏有效的正则化方法,容易产生几何失真。因此,需要一种能够生成高质量、低存储、几何结构合理的3D场景的方法。
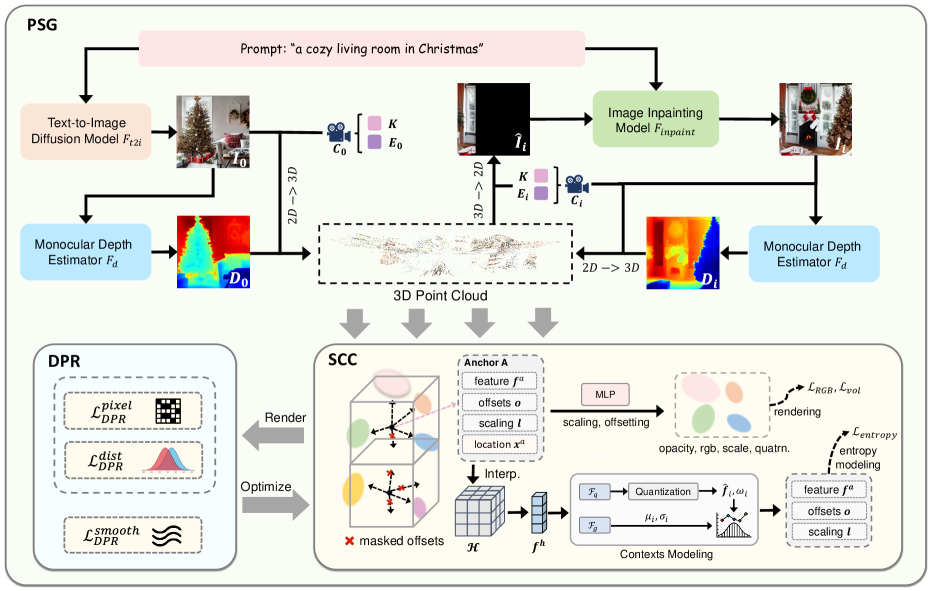
核心思路:BloomScene的核心思路是利用轻量级的结构化3D高斯溅射,结合跨模态信息,实现高效且高质量的3D场景生成。通过渐进式场景生成框架,逐步完善场景结构,并利用分层深度先验进行正则化,保证场景的真实性和连续性。同时,采用结构化上下文引导的压缩机制,减少存储开销。
技术框架:BloomScene的整体框架包含以下几个主要模块:1) 跨模态渐进式场景生成模块:利用增量点云重建和3D高斯溅射逐步生成场景。2) 分层深度先验正则化模块:利用多级约束,提高深度精度和平滑度。3) 结构化上下文引导压缩模块:利用结构化哈希网格建模上下文,减少冗余。
关键创新:BloomScene的关键创新在于:1) 提出了跨模态渐进式场景生成框架,能够有效地融合文本或图像信息,生成连贯的3D场景。2) 提出了分层深度先验正则化机制,能够有效地约束场景的几何结构,提高真实感。3) 提出了结构化上下文引导的压缩机制,能够显著减少存储开销。与现有方法相比,BloomScene在保证生成质量的同时,显著降低了存储需求。
关键设计:BloomScene的关键设计包括:1) 增量点云重建的具体算法和参数设置。2) 分层深度先验正则化中,多级约束的具体形式和权重设置。3) 结构化哈希网格的结构设计和参数设置,以及上下文建模的具体方法。这些细节的设计直接影响着生成场景的质量和存储效率,具体数值未知。
🖼️ 关键图片


📊 实验亮点
BloomScene通过跨模态渐进式场景生成框架和结构化上下文引导压缩机制,在保证生成质量的同时,显著降低了存储开销。论文中提到,该框架在多个场景下进行了实验,并与多个基线方法进行了比较,实验结果表明BloomScene具有显著的潜力和优势,但具体的性能数据和提升幅度未知。
🎯 应用场景
BloomScene可应用于虚拟现实、增强现实、游戏开发、机器人导航等领域。它能够根据文本或图像快速生成高质量的3D场景,降低了3D内容创作的门槛,并为虚拟环境的构建提供了新的解决方案。未来,该技术有望在元宇宙等新兴领域发挥重要作用。
📄 摘要(原文)
With the widespread use of virtual reality applications, 3D scene generation has become a new challenging research frontier. 3D scenes have highly complex structures and need to ensure that the output is dense, coherent, and contains all necessary structures. Many current 3D scene generation methods rely on pre-trained text-to-image diffusion models and monocular depth estimators. However, the generated scenes occupy large amounts of storage space and often lack effective regularisation methods, leading to geometric distortions. To this end, we propose BloomScene, a lightweight structured 3D Gaussian splatting for crossmodal scene generation, which creates diverse and high-quality 3D scenes from text or image inputs. Specifically, a crossmodal progressive scene generation framework is proposed to generate coherent scenes utilizing incremental point cloud reconstruction and 3D Gaussian splatting. Additionally, we propose a hierarchical depth prior-based regularization mechanism that utilizes multi-level constraints on depth accuracy and smoothness to enhance the realism and continuity of the generated scenes. Ultimately, we propose a structured context-guided compression mechanism that exploits structured hash grids to model the context of unorganized anchor attributes, which significantly eliminates structural redundancy and reduces storage overhead. Comprehensive experiments across multiple scenes demonstrate the significant potential and advantages of our framework compared with several baselines.