Patch-aware Vector Quantized Codebook Learning for Unsupervised Visual Defect Detection
作者: Qisen Cheng, Shuhui Qu, Janghwan Lee
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-01-15
备注: 7 pages, Accepted to 36th IEEE ICTAI 2024
💡 一句话要点
提出基于Patch感知的向量量化码本学习方法,用于无监督视觉缺陷检测
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 无监督学习 视觉缺陷检测 向量量化 变分自编码器 码本学习 Patch感知 工业质检
📋 核心要点
- 无监督缺陷检测面临表达能力和紧凑性的挑战,现有方法难以平衡,易导致模式崩溃,影响检测精度。
- 提出Patch感知的动态码分配方案,使模型能够根据上下文进行码本选择,优化空间表征,提升正常与缺陷的区分度。
- 实验结果表明,该方法在MVTecAD、BTAD和MTSD等数据集上取得了state-of-the-art的性能。
📝 摘要(中文)
无监督视觉缺陷检测在工业应用中至关重要,它需要一个能够捕获正常数据特征并检测偏差的表征空间。在表达性和紧凑性之间取得平衡具有挑战性;过度表达的空间可能导致效率低下和模式崩溃,从而损害检测精度。本文提出了一种新方法,使用增强的VQ-VAE框架,并针对无监督缺陷检测进行了优化。我们的模型引入了一种patch感知的动态码分配方案,从而能够进行上下文相关的码分配,以优化空间表征。这种策略增强了正常-缺陷区分,并提高了推理过程中的检测精度。在MVTecAD、BTAD和MTSD数据集上的实验表明,我们的方法实现了最先进的性能。
🔬 方法详解
问题定义:论文旨在解决无监督视觉缺陷检测问题。现有方法在学习正常样本的表征时,难以在表达能力和紧凑性之间取得平衡。过度表达的模型容易过拟合正常样本,导致对细微缺陷的敏感度降低,同时也会增加计算复杂度。此外,现有方法可能存在模式崩溃问题,即模型只学习到部分正常样本的特征,从而无法有效区分正常样本和缺陷样本。
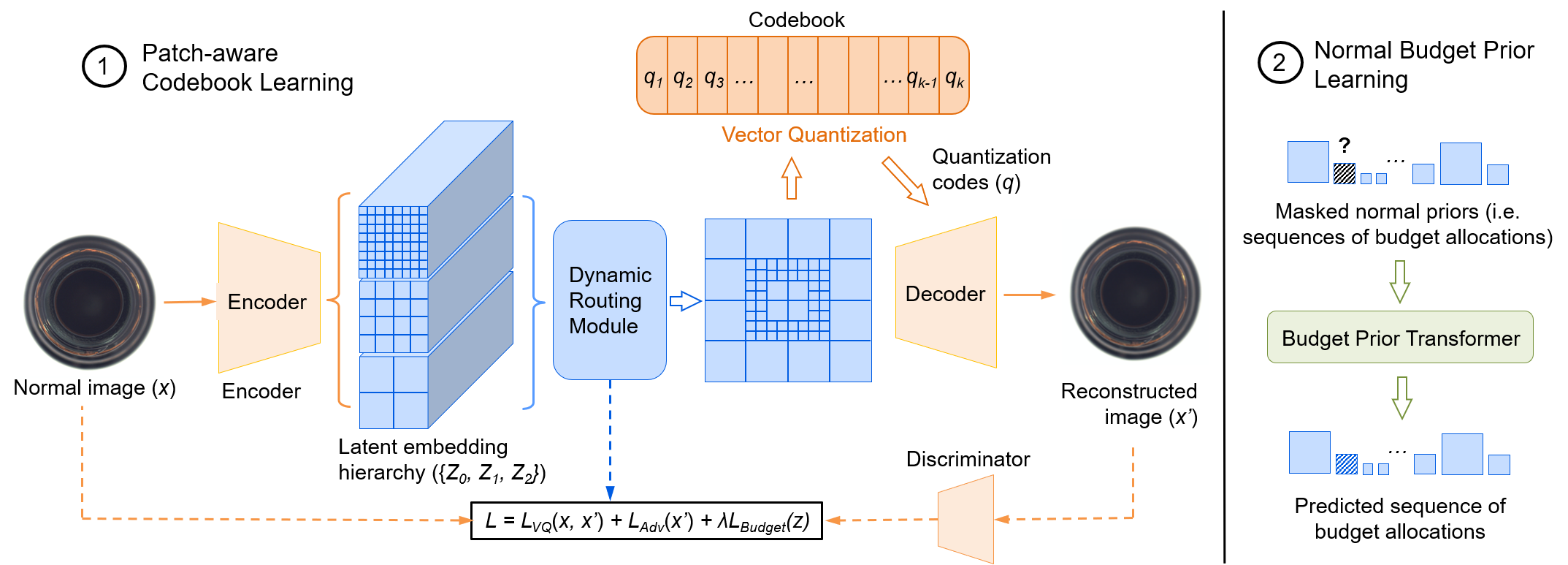
核心思路:论文的核心思路是利用向量量化变分自编码器(VQ-VAE)学习正常样本的紧凑表征,并通过引入patch感知的动态码本分配机制,增强模型对局部上下文信息的感知能力。通过这种方式,模型能够更准确地捕捉正常样本的特征,并有效区分正常样本和缺陷样本。
技术框架:该方法基于VQ-VAE框架,主要包含编码器、码本和解码器三个模块。编码器将输入图像编码为潜在表示,然后通过向量量化操作,将潜在表示映射到码本中的一个码字。解码器则根据选定的码字重构输入图像。关键在于引入了patch感知的动态码本分配机制,使得不同的图像区域可以根据其局部上下文信息选择不同的码字。
关键创新:该方法最重要的创新点在于提出了patch感知的动态码本分配方案。传统的VQ-VAE对所有图像区域使用相同的码本,忽略了不同区域之间的差异。而该方法根据图像的局部上下文信息,动态地为每个patch分配不同的码字,从而更好地捕捉了图像的局部特征。这种方法能够有效提高模型对细微缺陷的敏感度。
关键设计:具体来说,该方法首先将输入图像划分为多个patch,然后使用一个卷积神经网络提取每个patch的特征向量。接着,使用一个注意力机制,根据patch的特征向量计算每个码字的权重,并选择权重最高的码字作为该patch的量化结果。损失函数包括重构损失和量化损失,其中重构损失用于保证重构图像的质量,量化损失用于约束码本的学习。
🖼️ 关键图片


📊 实验亮点
该方法在MVTecAD、BTAD和MTSD等基准数据集上取得了state-of-the-art的性能。例如,在MVTecAD数据集上,该方法在多个类别的缺陷检测任务中均优于现有方法,平均AUROC指标提升显著。实验结果表明,该方法能够有效提高缺陷检测的准确性和鲁棒性。
🎯 应用场景
该研究成果可广泛应用于工业制造领域的表面缺陷检测,例如汽车零部件、电子元件、纺织品等产品的质量控制。通过自动检测产品表面的缺陷,可以提高生产效率、降低人工成本,并提升产品质量。此外,该方法还可以扩展到其他视觉异常检测任务,例如医疗图像分析、安全监控等领域,具有重要的实际应用价值和广阔的发展前景。
📄 摘要(原文)
Unsupervised visual defect detection is critical in industrial applications, requiring a representation space that captures normal data features while detecting deviations. Achieving a balance between expressiveness and compactness is challenging; an overly expressive space risks inefficiency and mode collapse, impairing detection accuracy. We propose a novel approach using an enhanced VQ-VAE framework optimized for unsupervised defect detection. Our model introduces a patch-aware dynamic code assignment scheme, enabling context-sensitive code allocation to optimize spatial representation. This strategy enhances normal-defect distinction and improves detection accuracy during inference. Experiments on MVTecAD, BTAD, and MTSD datasets show our method achieves state-of-the-art performance.