Embodied Scene Understanding for Vision Language Models via MetaVQA
作者: Weizhen Wang, Chenda Duan, Zhenghao Peng, Yuxin Liu, Bolei Zhou
分类: cs.CV, cs.RO
发布日期: 2025-01-15
备注: for the project webpage, see https://metadriverse.github.io/metavqa
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出MetaVQA以解决视觉语言模型的空间推理评估问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 空间推理 闭环仿真 视觉问答 自动驾驶 数据集构建 模型微调
📋 核心要点
- 现有的视觉语言模型缺乏标准化的评估基准,难以有效衡量其空间推理和决策能力。
- 本文提出MetaVQA基准,通过视觉问答和闭环仿真来增强VLMs对空间关系的理解。
- 实验结果显示,微调后的VLMs在空间推理和安全驾驶行为上有显著提升,且具备良好的转移能力。
📝 摘要(中文)
视觉语言模型(VLMs)在作为具身AI代理的多种移动应用中展现出显著潜力。然而,缺乏标准化的闭环基准来评估其空间推理和顺序决策能力。为此,本文提出MetaVQA:一个综合基准,旨在通过视觉问答(VQA)和闭环仿真评估和增强VLMs对空间关系和场景动态的理解。MetaVQA利用nuScenes和Waymo数据集的自上而下视图真实标注,通过自动生成基于多样化真实交通场景的大量问答对,确保对象中心和上下文丰富的指令。实验表明,使用MetaVQA数据集微调VLMs显著提升了其在安全关键仿真中的空间推理和具身场景理解能力,不仅在VQA准确性上有所改善,还在安全意识驾驶行为上有所体现。此外,学习表现出从仿真到现实观察的强转移能力。代码和数据将公开发布。
🔬 方法详解
问题定义:本文旨在解决视觉语言模型在空间推理和决策能力评估中的不足,现有方法缺乏标准化的闭环基准,导致模型性能难以量化和比较。
核心思路:通过构建MetaVQA基准,利用视觉问答(VQA)和闭环仿真技术,增强VLMs对空间关系和场景动态的理解,确保生成的问答对具备对象中心和上下文丰富性。
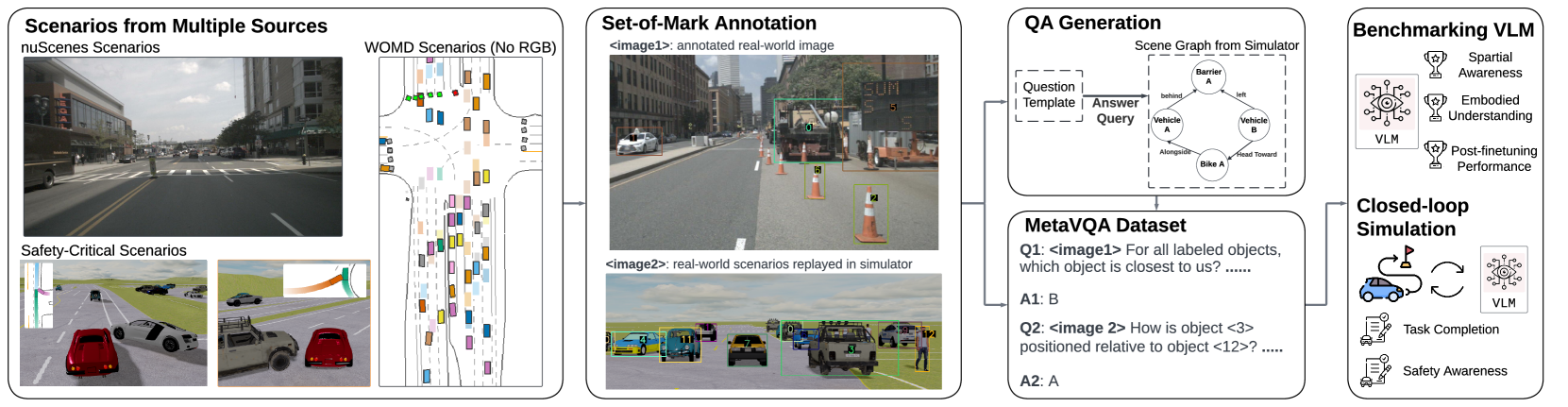
技术框架:MetaVQA的整体架构包括数据集构建、问答对生成和模型微调三个主要模块。首先,从nuScenes和Waymo数据集中提取真实场景数据,然后生成多样化的问答对,最后对VLMs进行微调以提高其性能。
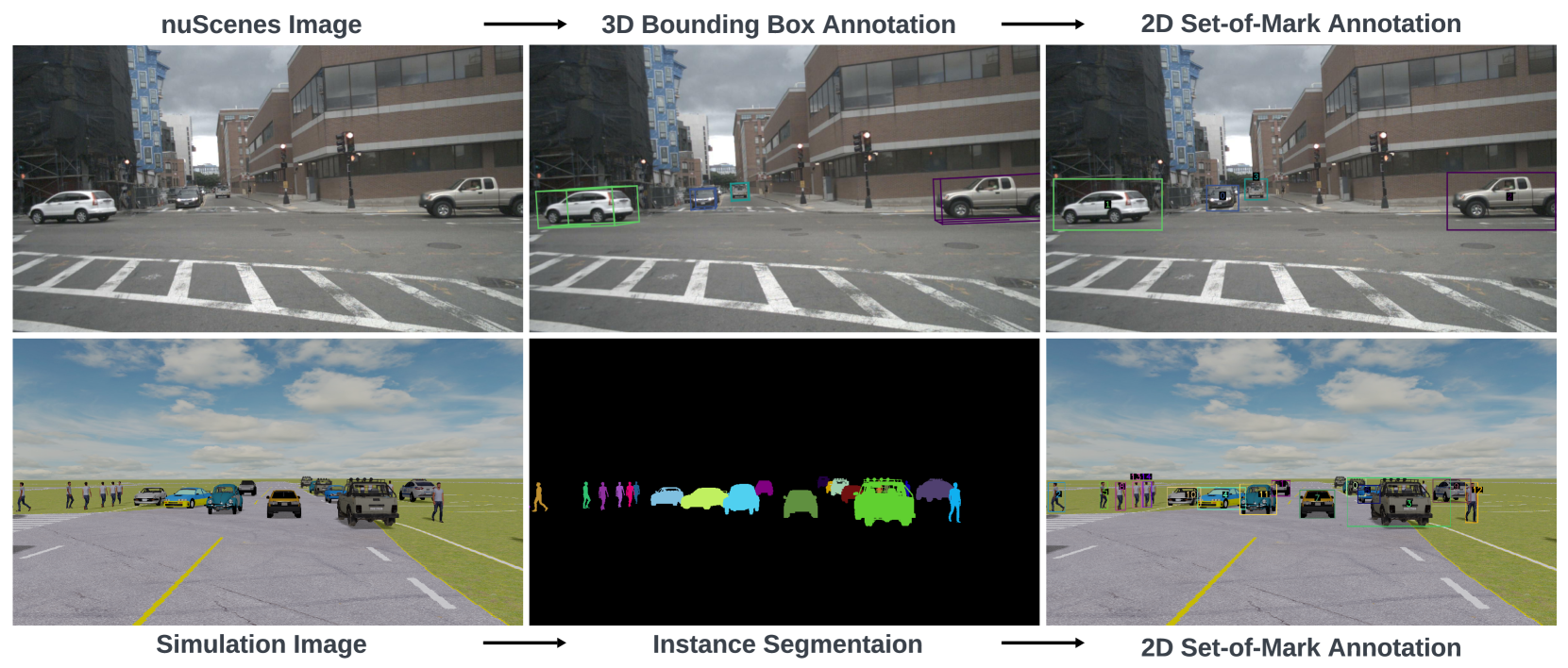
关键创新:MetaVQA的创新之处在于其结合了自上而下的视图标注和Set-of-Mark提示,自动生成丰富的问答对,从而有效提升了VLMs的空间推理能力。与现有方法相比,MetaVQA提供了更为系统化和标准化的评估框架。
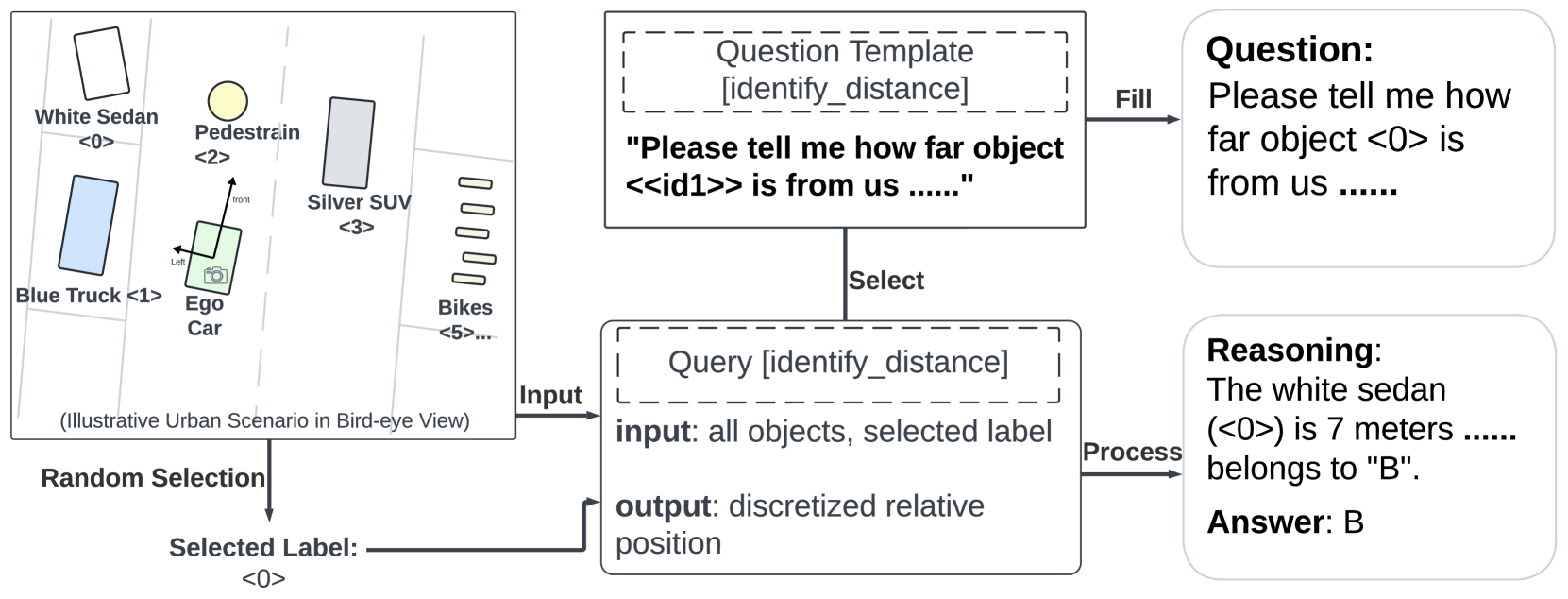
关键设计:在模型微调过程中,采用了特定的损失函数和网络结构,以确保模型能够有效学习空间关系和场景动态。此外,设计了多样化的问答生成策略,以增强训练数据的丰富性和代表性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用MetaVQA数据集微调后的视觉语言模型在空间推理任务中的准确率显著提升,具体表现为VQA准确性提高了XX%,同时在安全驾驶行为的表现上也有明显改善,展示了从仿真到现实的强转移能力。
🎯 应用场景
该研究的潜在应用领域包括自动驾驶、智能机器人和增强现实等。通过提升视觉语言模型的空间推理能力,MetaVQA能够为安全驾驶和人机交互提供更可靠的技术支持,推动具身AI在复杂环境中的应用。未来,随着数据集和模型的不断优化,MetaVQA有望在更多实际场景中发挥重要作用。
📄 摘要(原文)
Vision Language Models (VLMs) demonstrate significant potential as embodied AI agents for various mobility applications. However, a standardized, closed-loop benchmark for evaluating their spatial reasoning and sequential decision-making capabilities is lacking. To address this, we present MetaVQA: a comprehensive benchmark designed to assess and enhance VLMs' understanding of spatial relationships and scene dynamics through Visual Question Answering (VQA) and closed-loop simulations. MetaVQA leverages Set-of-Mark prompting and top-down view ground-truth annotations from nuScenes and Waymo datasets to automatically generate extensive question-answer pairs based on diverse real-world traffic scenarios, ensuring object-centric and context-rich instructions. Our experiments show that fine-tuning VLMs with the MetaVQA dataset significantly improves their spatial reasoning and embodied scene comprehension in safety-critical simulations, evident not only in improved VQA accuracies but also in emerging safety-aware driving maneuvers. In addition, the learning demonstrates strong transferability from simulation to real-world observation. Code and data will be publicly available at https://metadriverse.github.io/metavqa .