Multimodal LLMs Can Reason about Aesthetics in Zero-Shot
作者: Ruixiang Jiang, Changwen Chen
分类: cs.CV, cs.AI, cs.CL, cs.MM
发布日期: 2025-01-15 (更新: 2025-09-02)
备注: ACM MM 2025 Camera Ready
🔗 代码/项目: GITHUB
💡 一句话要点
提出ArtCoT,提升多模态LLM在零样本美学推理中的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态LLM 美学推理 零样本学习 幻觉抑制 证据推理
📋 核心要点
- 现有计算方法在美学感知方面存在不足,无法捕捉超越视觉吸引力的复杂认知过程。
- 论文提出ArtCoT框架,通过基于证据和客观的推理过程,抑制MLLM在美学推理中的幻觉。
- 实验表明,ArtCoT能显著提升MLLM的美学推理能力,使其判断与人类审美更加一致。
📝 摘要(中文)
生成艺术的快速发展降低了视觉吸引力图像的创作门槛。然而,实现真正的艺术影响力仍然具有挑战性,因为它需要复杂的美学感知。这种感知涉及超越单纯视觉吸引力的多方面认知过程,而这通常被现有计算方法所忽略。本文开创了一种方法,通过研究如何有效地激发多模态LLM(MLLM)的推理能力来进行美学判断,从而捕捉这一复杂过程。分析揭示了一个关键挑战:MLLM在美学推理过程中表现出幻觉倾向,其特征是主观意见和缺乏证据支持的艺术解释。进一步证明,通过采用基于证据和客观的推理过程可以抑制这些幻觉,正如我们提出的基线ArtCoT所证实的那样。在这种原则的提示下,MLLM产生了多方面的、深入的美学推理,与人类的判断更加一致。这些发现可以直接应用于人工智能艺术辅导和图像生成的奖励模型等领域。最终,我们希望这项工作为能够真正理解、欣赏和贡献符合人类审美价值的艺术的人工智能系统铺平道路。
🔬 方法详解
问题定义:论文旨在解决多模态LLM(MLLM)在零样本美学推理中存在的幻觉问题。现有方法在进行美学判断时,容易产生主观意见和缺乏证据支持的艺术解释,导致结果与人类审美存在偏差。
核心思路:论文的核心思路是通过引入基于证据和客观的推理过程来抑制MLLM的幻觉。具体来说,就是引导MLLM在进行美学判断时,首先寻找支持其观点的证据,然后再进行推理,从而减少主观臆断。
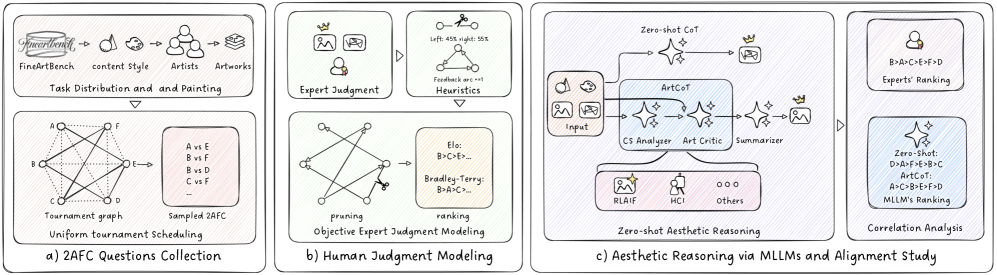
技术框架:论文提出的ArtCoT框架主要包含以下几个阶段:1. 图像输入:将待评估的艺术作品输入MLLM。2. 证据收集:引导MLLM从图像中寻找支持其美学判断的证据。3. 客观推理:基于收集到的证据,进行客观的美学推理。4. 结果输出:输出最终的美学判断结果。
关键创新:论文最重要的技术创新点在于提出了基于证据和客观推理的美学判断方法。与现有方法相比,该方法能够有效抑制MLLM的幻觉,使其美学判断更加客观和准确。
关键设计:ArtCoT的关键设计在于如何引导MLLM进行证据收集和客观推理。具体来说,论文使用了特定的提示语(prompt)来引导MLLM思考图像中的相关特征,并要求MLLM在进行判断之前,先列出支持其观点的证据。此外,论文还可能使用了特定的损失函数来鼓励MLLM进行客观推理,但具体细节未知。
🖼️ 关键图片

📊 实验亮点
论文提出的ArtCoT框架能够显著提升MLLM在零样本美学推理中的表现。实验结果表明,ArtCoT能够有效抑制MLLM的幻觉,使其美学判断与人类的判断更加一致。具体的性能数据和提升幅度在论文中进行了详细的展示,但此处未知。
🎯 应用场景
该研究成果可应用于多个领域,例如AI艺术辅导,帮助学生理解艺术作品的审美价值;图像生成的奖励模型,引导AI生成更符合人类审美标准的图像;以及艺术品推荐系统,为用户推荐更符合其审美偏好的作品。该研究有助于推动人工智能在艺术领域的应用,并促进人与AI在艺术创作方面的合作。
📄 摘要(原文)
The rapid technical progress of generative art (GenArt) has democratized the creation of visually appealing imagery. However, achieving genuine artistic impact - the kind that resonates with viewers on a deeper, more meaningful level - remains formidable as it requires a sophisticated aesthetic sensibility. This sensibility involves a multifaceted cognitive process extending beyond mere visual appeal, which is often overlooked by current computational methods. This paper pioneers an approach to capture this complex process by investigating how the reasoning capabilities of Multimodal LLMs (MLLMs) can be effectively elicited to perform aesthetic judgment. Our analysis reveals a critical challenge: MLLMs exhibit a tendency towards hallucinations during aesthetic reasoning, characterized by subjective opinions and unsubstantiated artistic interpretations. We further demonstrate that these hallucinations can be suppressed by employing an evidence-based and objective reasoning process, as substantiated by our proposed baseline, ArtCoT. MLLMs prompted by this principle produce multifaceted, in-depth aesthetic reasoning that aligns significantly better with human judgment. These findings have direct applications in areas such as AI art tutoring and as reward models for image generation. Ultimately, we hope this work paves the way for AI systems that can truly understand, appreciate, and contribute to art that aligns with human aesthetic values. Project homepage: https://github.com/songrise/MLLM4Art.