Perspective-Aware Teaching: Adapting Knowledge for Heterogeneous Distillation
作者: Jhe-Hao Lin, Yi Yao, Chan-Feng Hsu, Hongxia Xie, Hong-Han Shuai, Wen-Huang Cheng
分类: cs.CV
发布日期: 2025-01-15 (更新: 2025-10-16)
备注: Accepted by ICCV 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出视角感知教学框架,实现异构架构间知识蒸馏
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 异构模型 模型压缩 视角感知 Prompt Tuning
📋 核心要点
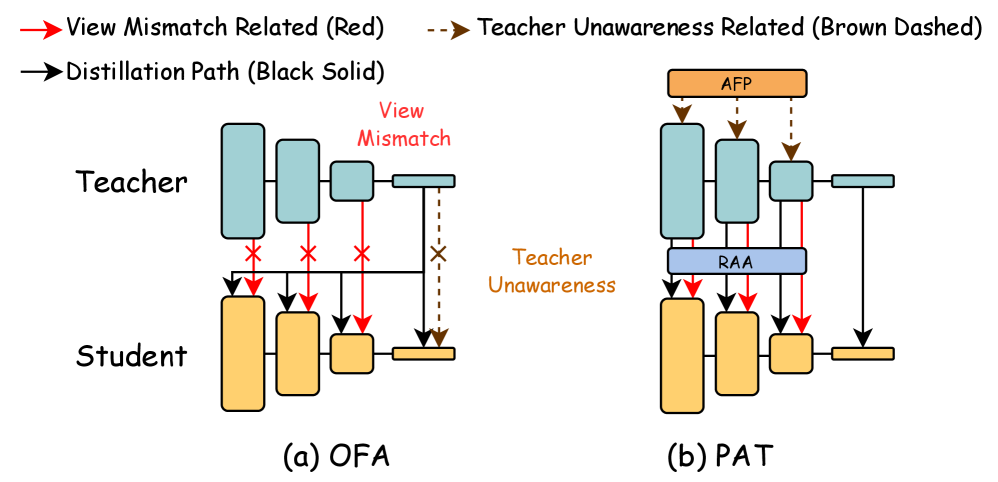
- 现有知识蒸馏方法难以有效处理教师和学生模型架构异构的问题,限制了其通用性。
- 论文提出视角感知教学框架,通过prompt tuning和区域感知注意力,使教师模型适应学生模型,缓解视角差异。
- 在CIFAR、ImageNet和COCO数据集上的实验表明,该方法在异构架构知识蒸馏方面表现优异。
📝 摘要(中文)
知识蒸馏(KD)旨在将知识从预训练的重型教师模型迁移到轻量级的学生模型,从而在保持相当效果的同时降低推理成本。先前的KD技术通常假设教师和学生模型之间是同质的。然而,随着技术的发展,涌现出各种各样的架构,从最初的卷积神经网络(CNN)到视觉Transformer(ViT)和多层感知器(MLP)。因此,开发一种与任何架构兼容的通用KD框架已成为一个重要的研究课题。在本文中,我们介绍了一种视角感知教学(PAT) KD框架,以实现跨不同架构的特征蒸馏。我们的框架包括两个关键组件。首先,我们设计了结合学生反馈的prompt tuning块,允许教师特征适应学生模型的学习过程。其次,我们提出了区域感知注意力来缓解异构架构之间的视角不匹配问题。通过利用这两个模块,可以实现跨异构架构的中间特征的有效蒸馏。在CIFAR、ImageNet和COCO上的大量实验证明了该方法的优越性。我们的代码可在https://github.com/jimmylin0979/PAT.git 获取。
🔬 方法详解
问题定义:论文旨在解决异构模型之间的知识蒸馏问题。现有知识蒸馏方法大多假设教师模型和学生模型具有相似的架构,当模型架构差异较大时,知识迁移效果会显著下降。因此,如何有效地在CNN、ViT、MLP等不同架构的模型之间进行知识蒸馏是一个挑战。
核心思路:论文的核心思路是通过让教师模型“感知”学生模型的学习状态,并根据学生模型的特点调整自身的知识表达,从而弥合异构架构之间的差异。具体来说,通过prompt tuning使教师模型适应学生模型的学习过程,并通过区域感知注意力机制来缓解不同架构模型在特征表示上的视角不匹配问题。
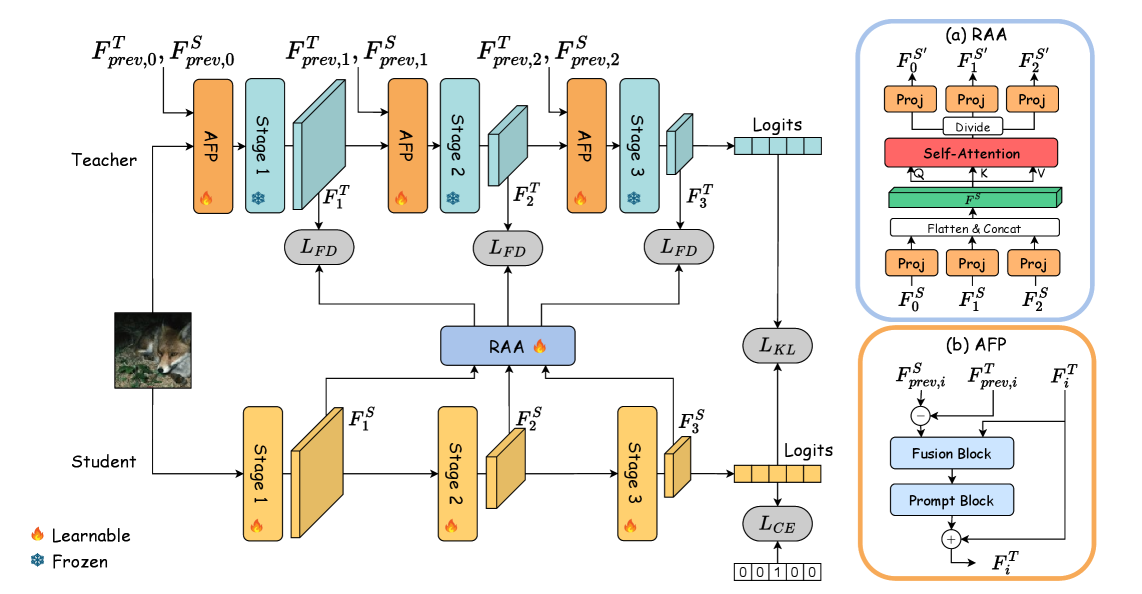
技术框架:PAT框架包含两个主要模块:Prompt Tuning Block和Region-Aware Attention。Prompt Tuning Block位于教师模型中,接收来自学生模型的反馈信号,并调整教师模型的特征表示,使其更适合学生模型的学习。Region-Aware Attention模块用于计算教师和学生模型特征之间的注意力权重,该权重考虑了不同区域的重要性,从而缓解了视角不匹配问题。整体流程是,学生模型前向传播,将特征反馈给教师模型,教师模型通过Prompt Tuning Block调整特征,然后通过Region-Aware Attention计算注意力权重,最后利用该权重进行知识蒸馏。
关键创新:论文的关键创新在于提出了视角感知教学的思想,并将其具体化为Prompt Tuning Block和Region-Aware Attention两个模块。Prompt Tuning Block允许教师模型根据学生模型的反馈动态调整自身,这是一种主动适应学生模型的机制,与传统的被动知识迁移方法不同。Region-Aware Attention则针对异构架构的特征表示差异,通过关注重要区域来提高知识迁移的效率。
关键设计:Prompt Tuning Block的具体实现方式是,在教师模型的中间层插入可学习的prompt向量,这些向量通过梯度下降进行优化,以最小化学生模型的损失函数。Region-Aware Attention通过计算教师和学生模型特征图之间的相似度来确定注意力权重,并引入了可学习的参数来调整不同区域的权重。损失函数包括传统的知识蒸馏损失(如KL散度)以及用于优化prompt向量的损失函数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提出的PAT框架在CIFAR、ImageNet和COCO数据集上均取得了显著的性能提升。例如,在ImageNet数据集上,使用ResNet50作为教师模型,MobileNetV2作为学生模型时,PAT框架相比于其他知识蒸馏方法,Top-1准确率提升了1-2个百分点。此外,消融实验验证了Prompt Tuning Block和Region-Aware Attention两个模块的有效性。
🎯 应用场景
该研究成果可广泛应用于模型压缩和加速领域,尤其是在需要将大型模型部署到资源受限的设备上时。例如,可以将一个在服务器上训练好的大型Transformer模型蒸馏到一个轻量级的CNN模型,然后部署到移动设备或嵌入式系统中。此外,该方法还可以用于构建更通用的知识蒸馏框架,支持各种不同的模型架构。
📄 摘要(原文)
Knowledge distillation (KD) involves transferring knowledge from a pre-trained heavy teacher model to a lighter student model, thereby reducing the inference cost while maintaining comparable effectiveness. Prior KD techniques typically assume homogeneity between the teacher and student models. However, as technology advances, a wide variety of architectures have emerged, ranging from initial Convolutional Neural Networks (CNNs) to Vision Transformers (ViTs), and Multi-Level Perceptrons (MLPs). Consequently, developing a universal KD framework compatible with any architecture has become an important research topic. In this paper, we introduce a perspective-aware teaching (PAT) KD framework to enable feature distillation across diverse architectures. Our framework comprises two key components. First, we design prompt tuning blocks that incorporate student feedback, allowing teacher features to adapt to the student model's learning process. Second, we propose region-aware attention to mitigate the view mismatch problem between heterogeneous architectures. By leveraging these two modules, effective distillation of intermediate features can be achieved across heterogeneous architectures. Extensive experiments on CIFAR, ImageNet, and COCO demonstrate the superiority of the proposed method. Our code is available at https://github.com/jimmylin0979/PAT.git.