BRIGHT-VO: Brightness-Guided Hybrid Transformer for Visual Odometry with Multi-modality Refinement Module
作者: Dongzhihan Wang, Yang Yang, Liang Xu
分类: cs.CV
发布日期: 2025-01-15 (更新: 2025-04-30)
🔗 代码/项目: GITHUB
💡 一句话要点
BrightVO:亮度引导的混合Transformer视觉里程计,结合多模态优化模块,提升弱光环境性能。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉里程计 Transformer 多模态融合 弱光环境 位姿估计
📋 核心要点
- 现有视觉里程计方法在弱光环境下表现不佳,因为特征可见性降低,关键点匹配难度增加。
- BrightVO利用Transformer进行视觉特征提取,并结合多模态优化模块融合IMU数据,提升位姿估计精度。
- 实验表明,BrightVO在正常光照和弱光环境下均优于现有方法,尤其在弱光环境下提升显著。
📝 摘要(中文)
本文提出了一种名为BrightVO的新型视觉里程计模型,该模型基于Transformer架构,不仅执行前端视觉特征提取,还在后端集成了一个多模态优化模块,该模块融合了惯性测量单元(IMU)数据。通过位姿图优化,该模块迭代地优化位姿估计,以减少误差并提高准确性和鲁棒性。此外,我们创建了一个合成的低光数据集KiC4R,其中包括各种光照条件,以促进在具有挑战性的环境中对VO框架的训练和评估。实验结果表明,BrightVO在KiC4R数据集和KITTI基准测试中均实现了最先进的性能。具体而言,在正常户外环境中,其位姿估计精度平均提高了20%,在弱光条件下提高了259%,优于现有方法。该研究工作已完全开源。
🔬 方法详解
问题定义:论文旨在解决视觉里程计在弱光环境下性能下降的问题。现有方法在光照不足时,提取的图像特征质量差,导致位姿估计精度大幅降低,难以满足自动驾驶和机器人导航等应用的需求。
核心思路:论文的核心思路是利用Transformer强大的特征提取能力,并结合IMU等多模态信息进行位姿优化。Transformer能够更好地捕捉图像中的全局信息,从而在弱光环境下也能提取到有效的特征。IMU数据则可以提供运动先验,帮助优化位姿估计结果。
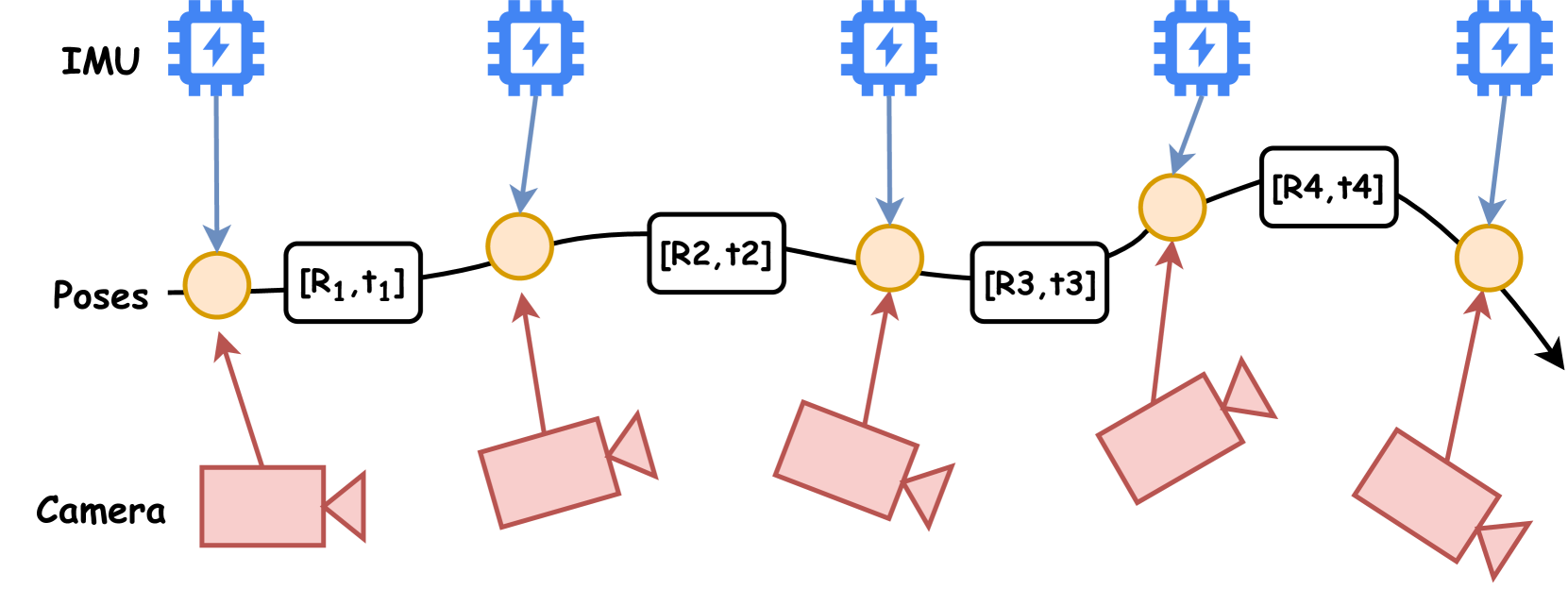
技术框架:BrightVO的整体架构包含三个主要模块:前端视觉特征提取模块、多模态融合模块和位姿图优化模块。前端视觉特征提取模块使用Transformer提取图像特征。多模态融合模块将视觉特征和IMU数据进行融合。位姿图优化模块利用融合后的信息进行位姿估计和优化。
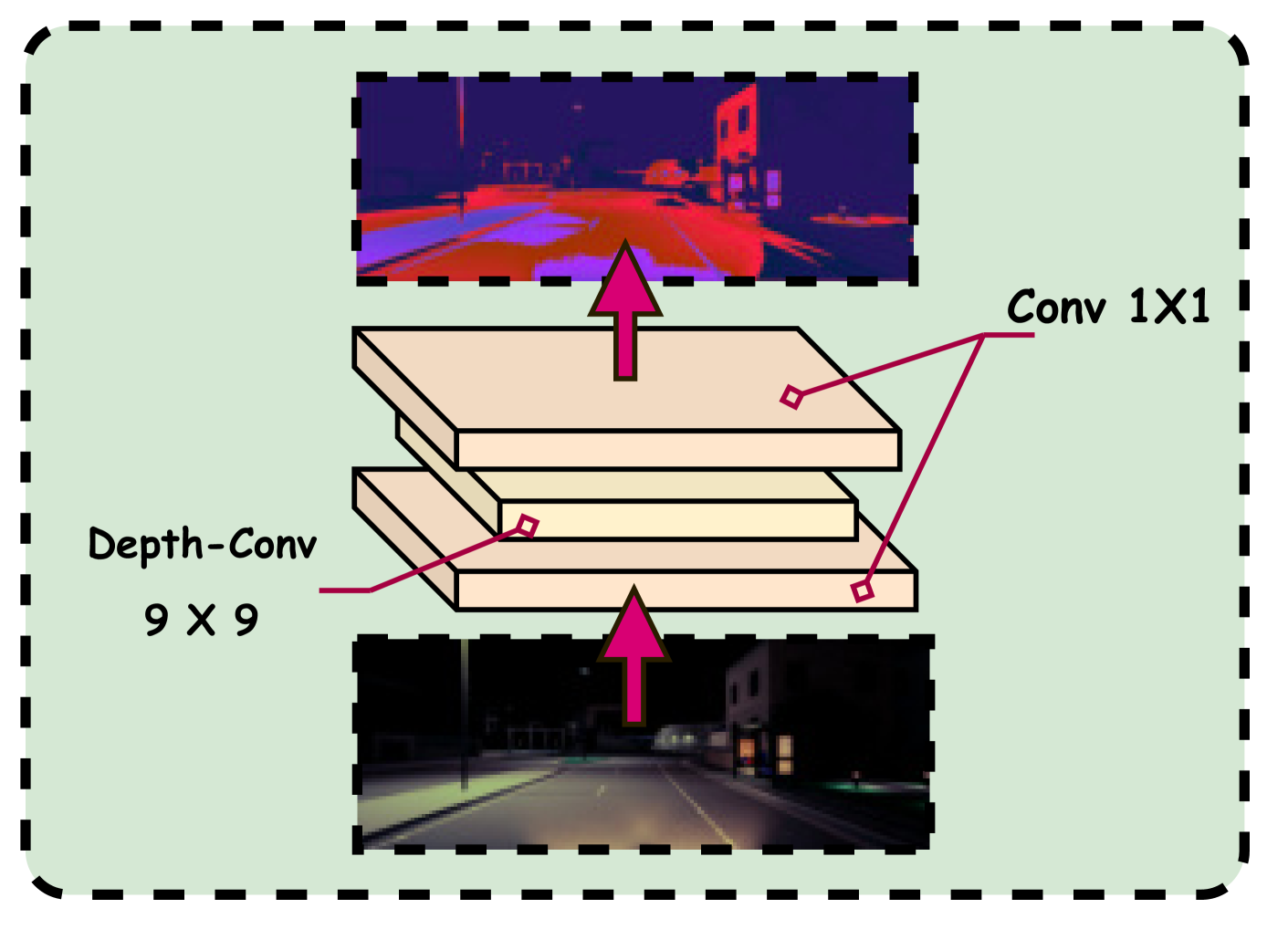
关键创新:论文的关键创新在于将Transformer应用于视觉里程计的前端特征提取,并设计了多模态融合模块,有效利用了IMU数据。此外,论文还提出了一个合成的低光数据集KiC4R,用于训练和评估VO框架在弱光环境下的性能。
关键设计:Transformer的结构细节未知,但推测使用了自注意力机制来捕捉图像中的长程依赖关系。多模态融合模块的具体融合方式未知,但可能使用了卡尔曼滤波或扩展卡尔曼滤波等方法。位姿图优化模块使用了常见的g2o或ceres等优化库。损失函数的设计未知,但可能包含了重投影误差和IMU预积分误差等。
🖼️ 关键图片

📊 实验亮点
BrightVO在KiC4R数据集和KITTI数据集上均取得了state-of-the-art的性能。在正常户外环境中,位姿估计精度平均提高了20%。在更具挑战性的弱光条件下,位姿估计精度提高了259%,显著优于现有方法,证明了BrightVO在弱光环境下的优越性。
🎯 应用场景
BrightVO在自动驾驶、机器人导航、增强现实等领域具有广泛的应用前景。尤其是在光照条件不佳的环境下,如夜间、隧道、室内等,BrightVO能够提供更准确、更鲁棒的位姿估计,从而提高系统的可靠性和安全性。该研究成果有助于推动自动驾驶和机器人技术的发展。
📄 摘要(原文)
Visual odometry (VO) plays a crucial role in autonomous driving, robotic navigation, and other related tasks by estimating the position and orientation of a camera based on visual input. Significant progress has been made in data-driven VO methods, particularly those leveraging deep learning techniques to extract image features and estimate camera poses. However, these methods often struggle in low-light conditions because of the reduced visibility of features and the increased difficulty of matching keypoints. To address this limitation, we introduce BrightVO, a novel VO model based on Transformer architecture, which not only performs front-end visual feature extraction, but also incorporates a multi-modality refinement module in the back-end that integrates Inertial Measurement Unit (IMU) data. Using pose graph optimization, this module iteratively refines pose estimates to reduce errors and improve both accuracy and robustness. Furthermore, we create a synthetic low-light dataset, KiC4R, which includes a variety of lighting conditions to facilitate the training and evaluation of VO frameworks in challenging environments. Experimental results demonstrate that BrightVO achieves state-of-the-art performance on both the KiC4R dataset and the KITTI benchmarks. Specifically, it provides an average improvement of 20% in pose estimation accuracy in normal outdoor environments and 259% in low-light conditions, outperforming existing methods. For widespread use and further development, the research work is fully open-source at https://github.com/Anastasiawd/BrightVO.