ZeroStereo: Zero-shot Stereo Matching from Single Images
作者: Xianqi Wang, Hao Yang, Gangwei Xu, Junda Cheng, Min Lin, Yong Deng, Jinliang Zang, Yurui Chen, Xin Yang
分类: cs.CV
发布日期: 2025-01-15 (更新: 2025-07-29)
备注: Accepted to ICCV 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出ZeroStereo以解决真实场景下立体匹配的泛化问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 零-shot学习 立体匹配 深度估计 图像生成 扩散模型
📋 核心要点
- 现有的监督立体匹配方法在真实场景中的泛化能力不足,主要由于缺乏足够的标注数据。
- 提出了ZeroStereo,通过生成高质量的右图像来实现零-shot立体匹配,利用单目深度估计模型生成伪视差。
- 实验表明,使用ZeroStereo训练的模型在多个数据集上实现了最先进的零-shot泛化性能,数据量仅与Scene Flow相当。
📝 摘要(中文)
现有的监督立体匹配方法在各种基准测试中表现优异,但在真实场景中的泛化能力仍然面临挑战,主要由于缺乏标注的真实立体数据。本文提出了ZeroStereo,一个用于零-shot立体匹配的新型立体图像生成管道。该方法通过利用单目深度估计模型生成的伪视差,从任意单幅图像合成高质量的右图像。与以往方法不同,本文通过微调扩散修复模型来恢复缺失细节,同时保持语义结构。此外,提出了无训练的置信度生成方法,以减轻不可靠伪标签的影响,并采用自适应视差选择,确保多样且真实的视差分布,同时防止过度遮挡和前景失真。实验结果表明,使用该管道训练的模型在多个数据集上实现了最先进的零-shot泛化性能。
🔬 方法详解
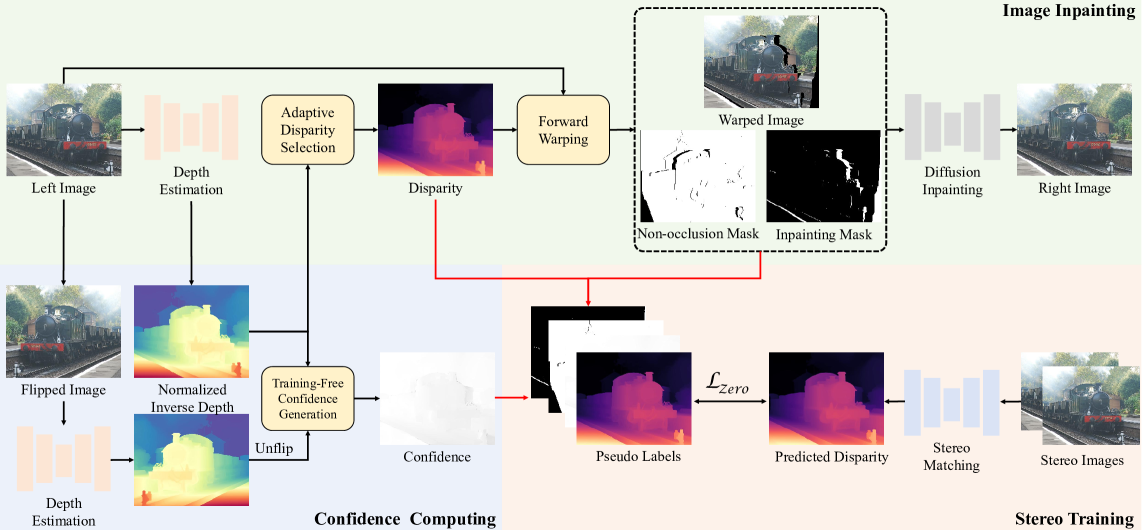
问题定义:现有的监督立体匹配方法在真实场景中的泛化能力不足,主要由于缺乏标注的真实立体数据,导致在处理遮挡区域时效果不佳。
核心思路:本文提出的ZeroStereo方法通过生成高质量的右图像,利用单目深度估计模型生成的伪视差,来实现零-shot立体匹配,避免了对大量标注数据的依赖。
技术框架:ZeroStereo的整体架构包括伪视差生成、扩散修复模型微调和自适应视差选择三个主要模块。首先,通过单目深度估计生成伪视差;其次,使用扩散修复模型恢复缺失细节;最后,进行自适应视差选择以确保视差分布的多样性和真实性。
关键创新:最重要的技术创新在于无训练的置信度生成方法和自适应视差选择,这些方法有效减轻了不可靠伪标签的影响,并确保了生成图像的质量和真实性。
关键设计:在关键设计方面,扩散修复模型经过微调以适应特定的图像特征,同时在视差选择中引入了防止过度遮挡和前景失真的机制,确保生成的右图像在视觉上更为自然。
🖼️ 关键图片


📊 实验亮点
实验结果显示,使用ZeroStereo训练的模型在多个数据集上实现了最先进的零-shot泛化性能,相较于基线方法,性能提升显著,尤其在处理复杂场景时表现出色,验证了该方法的有效性。
🎯 应用场景
ZeroStereo的研究成果在自动驾驶、机器人视觉和增强现实等领域具有广泛的应用潜力。通过提高立体匹配的泛化能力,该方法能够在缺乏标注数据的情况下,提升系统在真实环境中的表现,具有重要的实际价值和未来影响。
📄 摘要(原文)
State-of-the-art supervised stereo matching methods have achieved remarkable performance on various benchmarks. However, their generalization to real-world scenarios remains challenging due to the scarcity of annotated real-world stereo data. In this paper, we propose ZeroStereo, a novel stereo image generation pipeline for zero-shot stereo matching. Our approach synthesizes high-quality right images from arbitrary single images by leveraging pseudo disparities generated by a monocular depth estimation model. Unlike previous methods that address occluded regions by filling missing areas with neighboring pixels or random backgrounds, we fine-tune a diffusion inpainting model to recover missing details while preserving semantic structure. Additionally, we propose Training-Free Confidence Generation, which mitigates the impact of unreliable pseudo labels without additional training, and Adaptive Disparity Selection, which ensures a diverse and realistic disparity distribution while preventing excessive occlusion and foreground distortion. Experiments demonstrate that models trained with our pipeline achieve state-of-the-art zero-shot generalization across multiple datasets with only a dataset volume comparable to Scene Flow. Code: https://github.com/Windsrain/ZeroStereo.