Joint Learning of Depth and Appearance for Portrait Image Animation
作者: Xinya Ji, Gaspard Zoss, Prashanth Chandran, Lingchen Yang, Xun Cao, Barbara Solenthaler, Derek Bradley
分类: cs.CV, cs.LG
发布日期: 2025-01-15
💡 一句话要点
提出基于扩散模型的联合深度与外观学习框架,用于高质量人像图像动画
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 人像动画 扩散模型 深度估计 联合学习 3D一致性 图像生成 深度图生成
📋 核心要点
- 现有2D人像动画方法主要集中于RGB图像生成,缺乏对视觉外观和3D信息联合建模的能力。
- 论文提出一种基于扩散模型的框架,能够同时学习人像的视觉外观和深度信息,实现高质量的联合生成。
- 该框架可应用于面部深度估计、图像重光照、以及具有3D一致性的音频驱动人像动画等下游任务。
📝 摘要(中文)
近年来,2D人像动画取得了显著进展。大量研究利用大型生成扩散模型中蕴含的先验知识来增强高质量图像的操控性。然而,大多数方法仅关注生成RGB图像作为输出,而一致的视觉和3D输出的协同生成仍然很大程度上未被探索。在我们的工作中,我们提出在基于扩散的人像图像生成器中同时联合学习视觉外观和深度。我们的方法采用端到端扩散范式,并引入了一种新的架构,该架构适用于学习这种条件联合分布,包括参考网络和通道扩展的扩散骨干网络。经过训练后,我们的框架可以有效地适应各种下游应用,例如面部深度到图像和图像到深度生成、人像重光照以及具有一致3D输出的音频驱动的说话头动画。
🔬 方法详解
问题定义:现有的人像动画方法主要关注于生成高质量的RGB图像,忽略了3D信息的生成和利用。这导致生成的动画在3D空间中不一致,例如,头部旋转时,面部深度信息可能不自然。因此,如何同时生成高质量的RGB图像和一致的3D深度信息是一个关键问题。
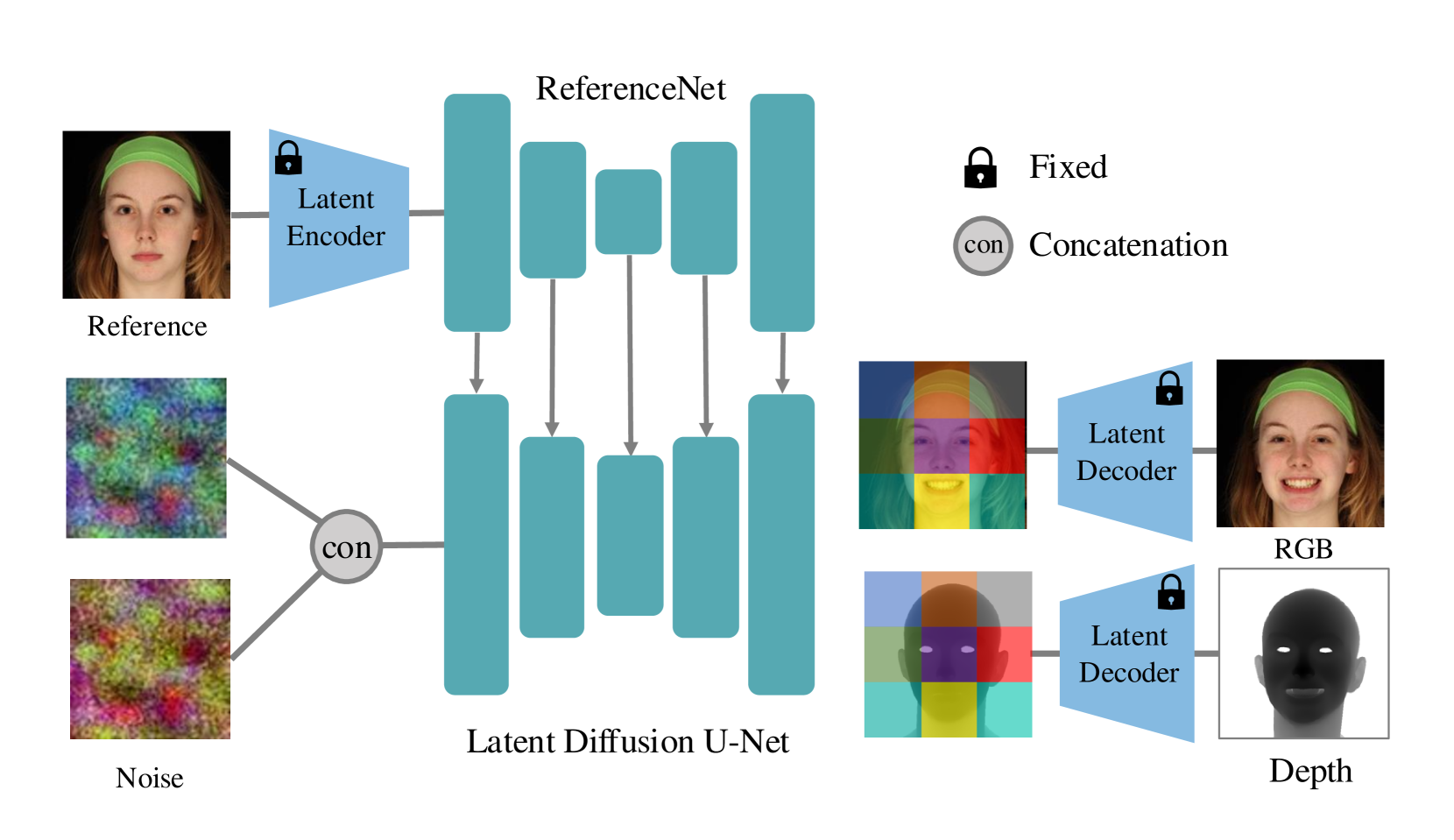
核心思路:论文的核心思路是利用扩散模型强大的生成能力,并将其扩展到同时生成RGB图像和深度图。通过联合学习RGB图像和深度图的分布,可以保证生成结果在视觉外观和3D空间上的一致性。此外,论文还引入了参考网络,用于提取参考图像的特征,从而控制生成过程。
技术框架:整体框架包含一个参考网络和一个通道扩展的扩散骨干网络。参考网络用于提取参考图像的特征,这些特征被输入到扩散骨干网络中,作为生成过程的条件。扩散骨干网络是一个标准的U-Net结构,但其输入和输出通道数被扩展,以同时处理RGB图像和深度图。训练过程中,模型学习从噪声中逐步生成RGB图像和深度图,直到生成高质量的结果。
关键创新:该论文的关键创新在于提出了一个端到端的扩散模型,可以同时生成高质量的RGB图像和深度图。与现有方法相比,该方法能够更好地保证生成结果在视觉外观和3D空间上的一致性。此外,论文还引入了参考网络,使得生成过程可以受到参考图像的控制。
关键设计:论文的关键设计包括:1) 通道扩展的扩散骨干网络,用于同时处理RGB图像和深度图;2) 参考网络,用于提取参考图像的特征;3) 联合损失函数,用于优化RGB图像和深度图的生成质量。具体的损失函数包括RGB图像的L1损失、深度图的L1损失,以及对抗损失等。网络结构采用标准的U-Net结构,并根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
论文提出的方法在人像深度估计、图像重光照和音频驱动人像动画等任务上取得了显著的成果。通过与现有方法的对比,证明了该方法能够生成更高质量、更逼真的人像动画,并且在3D一致性方面有明显优势。具体的性能数据和对比基线在论文中有详细的展示。
🎯 应用场景
该研究成果可广泛应用于虚拟现实、增强现实、游戏开发、影视制作等领域。例如,可以用于创建逼真的虚拟人物,实现高质量的视频会议和直播,以及生成具有3D效果的动画内容。此外,该技术还可以应用于人脸重建、人脸识别等领域,具有重要的实际应用价值和广阔的市场前景。
📄 摘要(原文)
2D portrait animation has experienced significant advancements in recent years. Much research has utilized the prior knowledge embedded in large generative diffusion models to enhance high-quality image manipulation. However, most methods only focus on generating RGB images as output, and the co-generation of consistent visual plus 3D output remains largely under-explored. In our work, we propose to jointly learn the visual appearance and depth simultaneously in a diffusion-based portrait image generator. Our method embraces the end-to-end diffusion paradigm and introduces a new architecture suitable for learning this conditional joint distribution, consisting of a reference network and a channel-expanded diffusion backbone. Once trained, our framework can be efficiently adapted to various downstream applications, such as facial depth-to-image and image-to-depth generation, portrait relighting, and audio-driven talking head animation with consistent 3D output.