DAViD: Modeling Dynamic Affordance of 3D Objects Using Pre-trained Video Diffusion Models
作者: Hyeonwoo Kim, Sangwon Baik, Hanbyul Joo
分类: cs.CV
发布日期: 2025-01-14 (更新: 2025-08-11)
备注: Project Page: https://snuvclab.github.io/david/
💡 一句话要点
DAViD:利用预训练视频扩散模型建模3D对象的动态可供性
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱四:生成式动作 (Generative Motion) 支柱五:交互与反应 (Interaction & Reaction) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 动态可供性 人-物交互 视频扩散模型 运动生成 低秩适应 4D HOI 合成数据
📋 核心要点
- 现有方法主要关注静态人-物交互模式,忽略了捕捉人和物体随时间变化的动态人-物交互模式。
- 论文提出DAViD框架,利用预训练视频扩散模型和LoRA微调,从合成数据中学习3D对象的动态可供性。
- 实验表明,DAViD在合成人-物交互运动方面优于现有基线方法,能够生成新颖的交互动作。
📝 摘要(中文)
本文提出了一种新颖的框架,用于学习各种目标对象类别的动态可供性。为了解决4D人-物交互(HOI)数据集的稀缺问题,该方法从合成生成的4D HOI样本中学习3D动态可供性。具体而言,该流程首先使用预训练的视频扩散模型从给定的3D目标对象生成2D HOI视频,然后将其提升到3D以生成4D HOI样本。利用这些合成的4D HOI样本,训练DAViD,即生成式4D人-物交互模型,它由两个关键组件组成:(1)具有低秩适应(LoRA)模块的人体运动扩散模型(MDM),用于微调预训练的MDM,以从有限的HOI运动样本中学习HOI运动概念;(2)由产生的人体交互运动调节的4D对象姿势的运动扩散模型。DAViD可以将新学习的HOI运动概念与预训练的人体运动相结合,从而创建新颖的HOI运动,即使对于多个HOI运动概念也是如此,这证明了LoRA在集成动态HOI概念方面的优势。通过广泛的实验,证明DAViD在合成HOI运动方面优于基线。
🔬 方法详解
问题定义:现有的人-物交互(HOI)研究主要集中在静态交互模式,例如接触和空间关系,而忽略了动态HOI模式,即人和物体随时间变化的运动。缺乏足够规模的4D HOI数据集是训练此类模型的关键瓶颈。
核心思路:论文的核心思路是利用预训练的视频扩散模型生成合成的4D HOI数据,然后使用这些数据训练一个生成模型,使其能够学习和生成动态的HOI动作。通过这种方式,可以绕过对大规模真实4D HOI数据的需求。
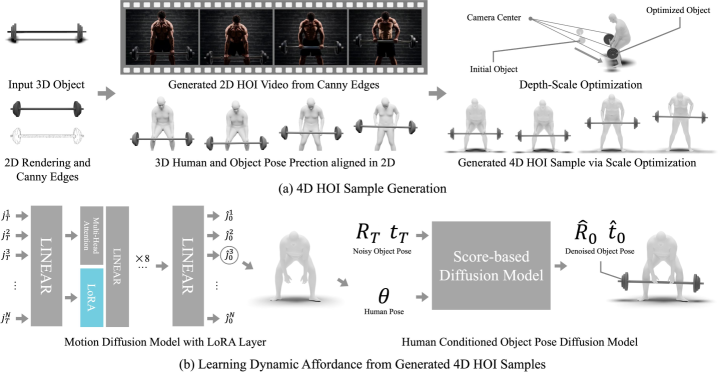
技术框架:DAViD框架包含以下几个主要步骤:1) 使用预训练的视频扩散模型,根据给定的3D目标对象生成2D HOI视频。2) 将生成的2D视频提升到3D空间,从而创建4D HOI样本。3) 使用合成的4D HOI样本训练DAViD模型。DAViD模型包含两个关键组件:a) 一个基于运动扩散模型(MDM)的人体运动生成器,使用LoRA进行微调;b) 一个条件运动扩散模型,用于生成与人体运动相对应的4D物体姿态。
关键创新:该方法的主要创新在于利用预训练的视频扩散模型生成合成的4D HOI数据,并使用LoRA微调MDM,从而能够在有限的数据集上学习复杂的HOI动作。此外,该方法能够将新学习的HOI运动概念与预训练的人体运动相结合,创造出新颖的HOI动作。
关键设计:LoRA模块被用于微调预训练的MDM,以便在有限的HOI运动样本上学习HOI运动概念。具体来说,LoRA通过引入低秩矩阵来近似原始模型的权重更新,从而减少了需要训练的参数数量,并防止了过拟合。此外,论文还设计了一个条件运动扩散模型,用于生成与人体运动相对应的4D物体姿态。具体的损失函数和网络结构等技术细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
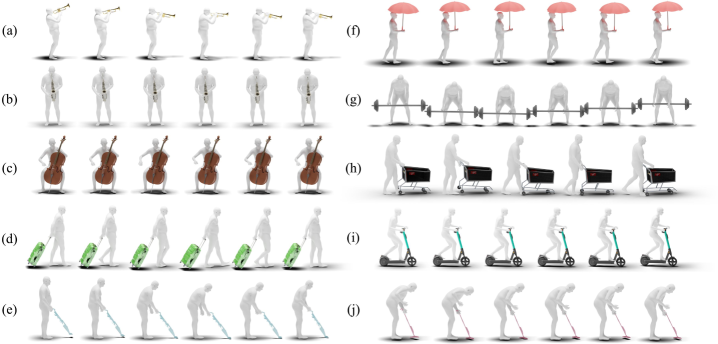
实验结果表明,DAViD在合成HOI运动方面优于基线方法。DAViD能够生成更逼真、更自然的HOI动作,并且能够将新学习的HOI运动概念与预训练的人体运动相结合,创造出新颖的HOI动作。具体的性能数据和提升幅度在论文中进行了详细描述(未知)。
🎯 应用场景
该研究成果可应用于机器人技术、虚拟现实、游戏开发等领域。例如,可以训练机器人模仿人类与物体的交互,创建更逼真的虚拟现实体验,或生成更智能的游戏角色动作。未来,该技术有望推动人机协作和人工智能在现实世界中的应用。
📄 摘要(原文)
Modeling how humans interact with objects is crucial for AI to effectively assist or mimic human behaviors. Existing studies for learning such ability primarily focus on static human-object interaction (HOI) patterns, such as contact and spatial relationships, while dynamic HOI patterns, capturing the movement of humans and objects over time, remain relatively underexplored. In this paper, we present a novel framework for learning Dynamic Affordance across various target object categories. To address the scarcity of 4D HOI datasets, our method learns the 3D dynamic affordance from synthetically generated 4D HOI samples. Specifically, we propose a pipeline that first generates 2D HOI videos from a given 3D target object using a pre-trained video diffusion model, then lifts them into 3D to generate 4D HOI samples. Leveraging these synthesized 4D HOI samples, we train DAViD, our generative 4D human-object interaction model, which is composed of two key components: (1) a human motion diffusion model (MDM) with Low-Rank Adaptation (LoRA) module to fine-tune a pre-trained MDM to learn the HOI motion concepts from limited HOI motion samples, (2) a motion diffusion model for 4D object poses conditioned by produced human interaction motions. Interestingly, DAViD can integrate newly learned HOI motion concepts with pre-trained human motions to create novel HOI motions, even for multiple HOI motion concepts, demonstrating the advantage of our pipeline with LoRA in integrating dynamic HOI concepts. Through extensive experiments, we demonstrate that DAViD outperforms baselines in synthesizing HOI motion.