Go-with-the-Flow: Motion-Controllable Video Diffusion Models Using Real-Time Warped Noise
作者: Ryan Burgert, Yuancheng Xu, Wenqi Xian, Oliver Pilarski, Pascal Clausen, Mingming He, Li Ma, Yitong Deng, Lingxiao Li, Mohsen Mousavi, Michael Ryoo, Paul Debevec, Ning Yu
分类: cs.CV
发布日期: 2025-01-14 (更新: 2025-08-06)
备注: Accepted to CVPR'25 as Oral
🔗 代码/项目: GITHUB | PROJECT_PAGE
💡 一句话要点
提出基于实时噪声扭曲的运动可控视频扩散模型,实现灵活的视频生成控制。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视频扩散模型 运动控制 光流场 噪声扭曲 视频生成
📋 核心要点
- 现有视频扩散模型缺乏对生成视频运动的有效控制,难以满足用户对特定运动轨迹的需求。
- 通过对训练数据进行预处理,利用光流场生成扭曲噪声,从而在潜在空间中引入运动信息,实现运动控制。
- 实验表明,该方法能够有效控制视频中物体和相机的运动,同时保持视频的视觉质量,具有良好的可扩展性。
📝 摘要(中文)
本文通过引入结构化的潜在噪声采样,增强了视频扩散模型,使其具备运动控制能力。该方法的核心在于对训练视频进行预处理,生成结构化的噪声。这种方法与扩散模型的设计无关,无需修改模型架构或训练流程。具体而言,论文提出了一种快速的噪声扭曲算法,该算法能够实时运行,并用从光流场导出的相关扭曲噪声替换随机时间高斯噪声,同时保持空间高斯性。该算法的高效性使得能够以最小的开销,使用扭曲噪声对现代视频扩散基础模型进行微调,并为各种用户友好的运动控制提供一站式解决方案,包括局部对象运动控制、全局相机运动控制和运动迁移。扭曲噪声中时间连贯性和空间高斯性之间的协调,实现了有效的运动控制,同时保持了每帧像素质量。大量的实验和用户研究表明了该方法的优势,使其成为控制视频扩散模型中运动的稳健且可扩展的方法。
🔬 方法详解
问题定义:现有的视频扩散模型在生成视频时,难以对视频中的运动进行精确控制。用户无法指定特定物体的运动轨迹或相机的运动方式,导致生成结果缺乏灵活性和可控性。现有方法通常需要修改模型结构或训练流程,增加了复杂性。
核心思路:论文的核心思路是通过在训练数据中引入结构化的噪声,将运动信息编码到潜在空间中。具体而言,利用光流场来扭曲随机噪声,使其具有与视频运动相关的时序相关性。这样,在生成视频时,可以通过控制扭曲噪声的特性来控制视频的运动。
技术框架:该方法主要包含以下几个步骤:1) 使用光流算法估计训练视频的光流场;2) 设计一种快速的噪声扭曲算法,利用光流场对随机高斯噪声进行扭曲,生成具有时序相关性的扭曲噪声;3) 使用包含扭曲噪声的视频数据对现有的视频扩散模型进行微调;4) 在推理阶段,通过控制光流场来控制生成视频的运动。
关键创新:该方法最重要的创新点在于提出了一种高效的噪声扭曲算法,该算法能够实时运行,并能够生成具有时序相关性,同时保持空间高斯性的扭曲噪声。这种扭曲噪声能够有效地将运动信息编码到潜在空间中,从而实现对视频运动的精确控制。与现有方法相比,该方法无需修改模型结构或训练流程,具有更好的通用性和可扩展性。
关键设计:噪声扭曲算法的设计是关键。算法需要保证扭曲后的噪声在时间上具有连贯性,以反映视频的运动信息,同时在空间上保持高斯性,以保证生成视频的视觉质量。论文中具体采用了一种基于光流场的像素级扭曲方法,并对算法进行了优化,使其能够实时运行。此外,论文还探索了不同的光流场控制策略,以实现不同的运动控制效果。
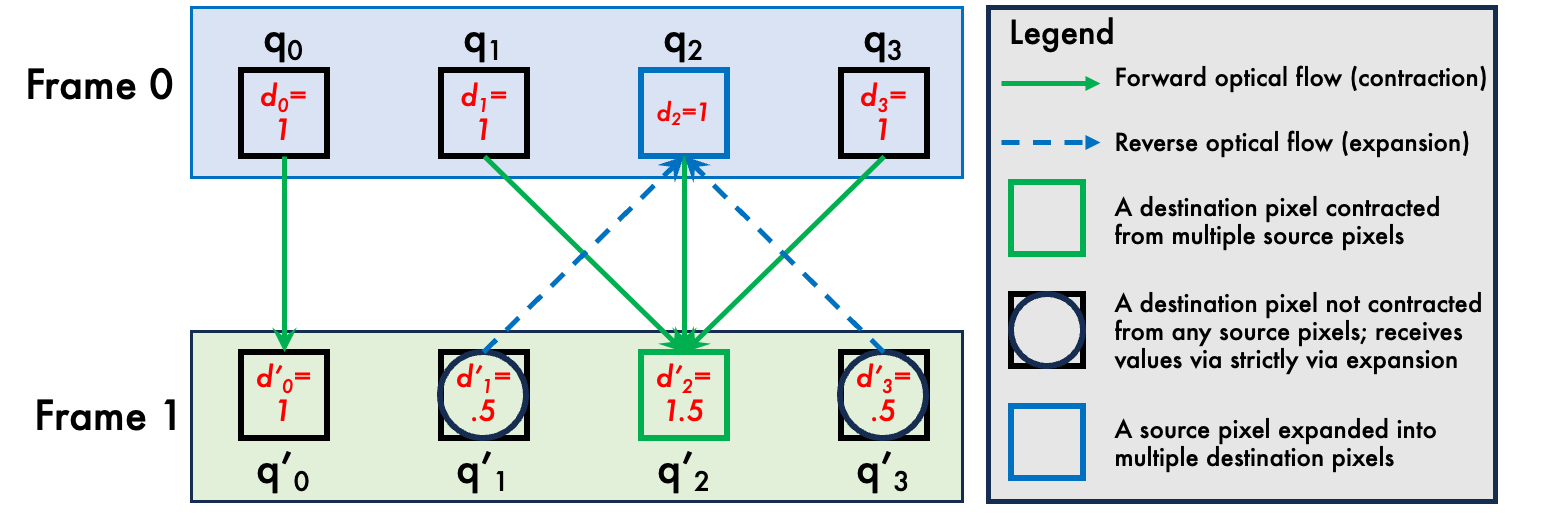
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法能够有效地控制视频中物体和相机的运动,同时保持视频的视觉质量。与现有的视频扩散模型相比,该方法在运动控制方面具有显著的优势。用户研究也表明,用户对该方法生成的视频的运动控制效果表示满意,认为该方法具有良好的实用价值。
🎯 应用场景
该研究成果可广泛应用于视频编辑、游戏开发、虚拟现实等领域。例如,用户可以使用该方法轻松地编辑视频中的物体运动轨迹,或者生成具有特定相机运动的虚拟场景。此外,该方法还可以用于视频修复和超分辨率等任务,通过控制运动信息来提高生成视频的质量。
📄 摘要(原文)
Generative modeling aims to transform random noise into structured outputs. In this work, we enhance video diffusion models by allowing motion control via structured latent noise sampling. This is achieved by just a change in data: we pre-process training videos to yield structured noise. Consequently, our method is agnostic to diffusion model design, requiring no changes to model architectures or training pipelines. Specifically, we propose a novel noise warping algorithm, fast enough to run in real time, that replaces random temporal Gaussianity with correlated warped noise derived from optical flow fields, while preserving the spatial Gaussianity. The efficiency of our algorithm enables us to fine-tune modern video diffusion base models using warped noise with minimal overhead, and provide a one-stop solution for a wide range of user-friendly motion control: local object motion control, global camera movement control, and motion transfer. The harmonization between temporal coherence and spatial Gaussianity in our warped noise leads to effective motion control while maintaining per-frame pixel quality. Extensive experiments and user studies demonstrate the advantages of our method, making it a robust and scalable approach for controlling motion in video diffusion models. Video results are available on our webpage: https://eyeline-labs.github.io/Go-with-the-Flow. Source code and model checkpoints are available on GitHub: https://github.com/Eyeline-Labs/Go-with-the-Flow.