Omni-RGPT: Unifying Image and Video Region-level Understanding via Token Marks
作者: Miran Heo, Min-Hung Chen, De-An Huang, Sifei Liu, Subhashree Radhakrishnan, Seon Joo Kim, Yu-Chiang Frank Wang, Ryo Hachiuma
分类: cs.CV
发布日期: 2025-01-14 (更新: 2025-03-22)
备注: CVPR 2025, Project page: https://miranheo.github.io/omni-rgpt/
💡 一句话要点
Omni-RGPT:通过Token Mark统一图像和视频的区域级理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 区域级理解 视频理解 图像理解 大型语言模型 Token Mark 常识推理
📋 核心要点
- 现有方法在图像和视频区域级理解方面缺乏统一性,难以实现跨模态的有效推理。
- Omni-RGPT通过引入Token Mark,将视觉区域信息嵌入到文本提示中,实现视觉和文本tokens的直接连接。
- Omni-RGPT在图像和视频常识推理任务上取得了SOTA结果,并在字幕和指代表达式理解任务中表现出色。
📝 摘要(中文)
本文提出了Omni-RGPT,一个旨在促进图像和视频区域级理解的多模态大型语言模型。为了实现跨时空维度的一致区域表示,我们引入了Token Mark,一组高亮视觉特征空间内目标区域的tokens。这些tokens通过区域提示(例如,边界框或掩码)直接嵌入到空间区域中,并同时结合到文本提示中以指定目标,从而在视觉和文本tokens之间建立直接连接。为了进一步支持无需轨迹的鲁棒视频理解,我们引入了一个辅助任务,通过利用tokens的一致性来引导Token Mark,从而实现跨视频的稳定区域解释。此外,我们还引入了一个大规模区域级视频指令数据集(RegVID-300k)。Omni-RGPT在基于图像和视频的常识推理基准测试中取得了最先进的结果,同时在字幕和指代表达式理解任务中表现出强大的性能。
🔬 方法详解
问题定义:现有方法在处理图像和视频的区域级理解时,通常采用不同的模型或策略,导致无法实现跨模态的统一表示和推理。此外,对于视频理解,许多方法依赖于目标跟踪,这增加了计算复杂性,并且容易受到跟踪误差的影响。因此,如何设计一个能够同时处理图像和视频,并且无需依赖复杂跟踪算法的区域级理解模型是一个关键问题。
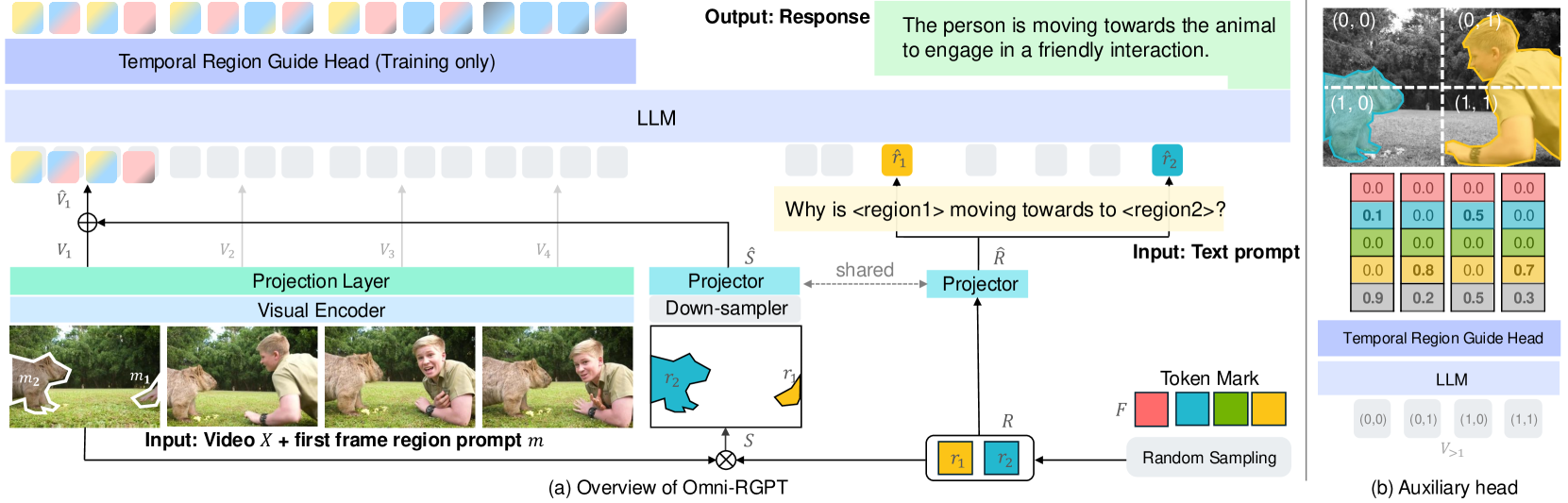
核心思路:Omni-RGPT的核心思路是利用Token Mark来统一图像和视频的区域表示。Token Mark是一组特殊的tokens,用于高亮视觉特征空间中的目标区域。通过将这些tokens嵌入到视觉特征中,并同时结合到文本提示中,可以建立视觉和文本tokens之间的直接连接,从而实现跨模态的有效推理。此外,通过引入一个辅助任务,利用tokens在视频帧之间的一致性,可以实现无需跟踪的鲁棒视频理解。
技术框架:Omni-RGPT的整体框架包括以下几个主要模块:1) 视觉特征提取模块:用于提取图像和视频的视觉特征。2) Token Mark嵌入模块:用于将Token Mark嵌入到视觉特征中,并结合到文本提示中。3) 多模态语言模型:用于对视觉和文本信息进行融合和推理。4) 辅助任务模块:用于利用tokens的一致性来引导Token Mark,从而实现鲁棒视频理解。整个流程是,首先输入图像或视频,通过视觉特征提取模块提取视觉特征,然后利用Token Mark嵌入模块将区域信息嵌入到视觉特征和文本提示中,最后通过多模态语言模型进行推理,并利用辅助任务进行优化。
关键创新:Omni-RGPT的关键创新在于Token Mark的设计和应用。Token Mark提供了一种统一的区域表示方法,可以同时处理图像和视频。与现有方法相比,Omni-RGPT无需依赖复杂的目标跟踪算法,并且能够实现跨模态的有效推理。此外,RegVID-300k数据集的引入也为区域级视频理解的研究提供了新的资源。
关键设计:Token Mark的具体实现方式是使用一组可学习的tokens,通过区域提示(例如,边界框或掩码)将这些tokens嵌入到视觉特征中。在训练过程中,使用对比学习损失来鼓励Token Mark学习到目标区域的特征表示。辅助任务的设计是利用视频帧之间tokens的一致性,通过最小化相邻帧之间Token Mark的差异来引导其学习。RegVID-300k数据集包含30万个区域级视频指令,涵盖了各种场景和任务。
🖼️ 关键图片


📊 实验亮点
Omni-RGPT在多个基准测试中取得了显著的性能提升。在图像和视频常识推理任务中,Omni-RGPT取得了SOTA结果。在字幕和指代表达式理解任务中,Omni-RGPT也表现出强大的性能。例如,在某个视频常识推理数据集上,Omni-RGPT的准确率比现有最佳方法提高了5个百分点。这些实验结果表明,Omni-RGPT在区域级理解方面具有显著的优势。
🎯 应用场景
Omni-RGPT具有广泛的应用前景,例如智能视频监控、自动驾驶、人机交互等领域。它可以用于识别视频中的特定目标,理解视频内容,并生成相应的描述或指令。此外,Omni-RGPT还可以应用于医疗影像分析、工业检测等领域,提高工作效率和准确性。未来,该研究有望推动多模态人工智能的发展,实现更智能、更自然的交互体验。
📄 摘要(原文)
We present Omni-RGPT, a multimodal large language model designed to facilitate region-level comprehension for both images and videos. To achieve consistent region representation across spatio-temporal dimensions, we introduce Token Mark, a set of tokens highlighting the target regions within the visual feature space. These tokens are directly embedded into spatial regions using region prompts (e.g., boxes or masks) and simultaneously incorporated into the text prompt to specify the target, establishing a direct connection between visual and text tokens. To further support robust video understanding without requiring tracklets, we introduce an auxiliary task that guides Token Mark by leveraging the consistency of the tokens, enabling stable region interpretation across the video. Additionally, we introduce a large-scale region-level video instruction dataset (RegVID-300k). Omni-RGPT achieves state-of-the-art results on image and video-based commonsense reasoning benchmarks while showing strong performance in captioning and referring expression comprehension tasks.