Advancing Semantic Future Prediction through Multimodal Visual Sequence Transformers
作者: Efstathios Karypidis, Ioannis Kakogeorgiou, Spyros Gidaris, Nikos Komodakis
分类: cs.CV
发布日期: 2025-01-14 (更新: 2025-11-27)
备注: CVPR 2025
💡 一句话要点
FUTURIST:提出基于多模态视觉序列Transformer的语义未来预测方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 未来语义预测 多模态学习 视觉序列Transformer 掩码建模 分层Token化
📋 核心要点
- 现有方法难以有效融合多模态信息,限制了未来语义预测的准确性,尤其是在动态环境中。
- FUTURIST利用视觉序列Transformer,结合多模态掩码建模和新型掩码机制,实现多模态信息的有效整合。
- 实验表明,FUTURIST在Cityscapes数据集上实现了最先进的未来语义分割性能,尤其是在短期和中期预测方面。
📝 摘要(中文)
本文提出了一种名为FUTURIST的多模态未来语义预测方法,该方法采用统一且高效的视觉序列Transformer架构。我们的方法结合了多模态掩码视觉建模目标和一种专为多模态训练设计的新型掩码机制,从而使模型能够有效地整合来自各种模态的可见信息,提高预测精度。此外,我们提出了一种无需VAE的分层token化过程,该过程降低了计算复杂度,简化了训练流程,并支持使用高分辨率多模态输入进行端到端训练。我们在Cityscapes数据集上验证了FUTURIST,证明了其在短期和中期预测中未来语义分割方面的最先进性能。
🔬 方法详解
问题定义:论文旨在解决自动驾驶等动态环境中,如何准确预测未来语义分割的问题。现有方法在处理多模态数据融合方面存在不足,难以有效利用不同模态的信息来提升预测精度。此外,高分辨率多模态输入的计算复杂度也是一个挑战。
核心思路:论文的核心思路是利用Transformer架构强大的序列建模能力,结合多模态掩码建模目标和新型掩码机制,实现多模态信息的有效融合。通过分层token化过程,降低计算复杂度,实现高分辨率输入的端到端训练。
技术框架:FUTURIST采用视觉序列Transformer架构,包含以下主要模块:多模态输入编码器(用于提取不同模态的特征),多模态掩码建模模块(用于训练模型理解和融合不同模态的信息),Transformer编码器(用于序列建模和未来预测),以及分层token化模块(用于降低计算复杂度)。整体流程为:输入多模态数据 -> 特征提取 -> 分层token化 -> Transformer编码 -> 未来语义分割预测。
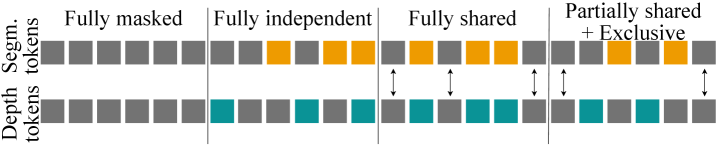
关键创新:论文的关键创新点在于:1) 提出了多模态掩码视觉建模目标和新型掩码机制,有效融合了不同模态的信息。2) 提出了无需VAE的分层token化过程,降低了计算复杂度,支持高分辨率输入的端到端训练。
关键设计:多模态掩码建模目标通过随机掩盖部分模态的输入,迫使模型利用其他模态的信息进行预测,从而增强模型的跨模态理解能力。新型掩码机制则根据不同模态的重要性进行自适应掩码。分层token化过程首先将高分辨率输入划分为多个patch,然后将相邻的patch进行合并,形成更粗粒度的token,从而降低序列长度和计算复杂度。损失函数包括语义分割损失和掩码重建损失。
🖼️ 关键图片


📊 实验亮点
FUTURIST在Cityscapes数据集上取得了最先进的未来语义分割性能。具体而言,在短期和中期预测任务中,FUTURIST的性能显著优于现有方法。实验结果表明,所提出的多模态掩码建模目标和分层token化过程能够有效提升预测精度和计算效率。项目主页提供了详细的实验结果和代码。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航等领域,通过预测未来场景的语义信息,提高系统的决策能力和安全性。例如,自动驾驶系统可以利用未来语义分割信息,提前感知潜在的障碍物和交通状况,从而做出更合理的驾驶策略。该技术还有潜力应用于视频监控、智能交通等领域。
📄 摘要(原文)
Semantic future prediction is important for autonomous systems navigating dynamic environments. This paper introduces FUTURIST, a method for multimodal future semantic prediction that uses a unified and efficient visual sequence transformer architecture. Our approach incorporates a multimodal masked visual modeling objective and a novel masking mechanism designed for multimodal training. This allows the model to effectively integrate visible information from various modalities, improving prediction accuracy. Additionally, we propose a VAE-free hierarchical tokenization process, which reduces computational complexity, streamlines the training pipeline, and enables end-to-end training with high-resolution, multimodal inputs. We validate FUTURIST on the Cityscapes dataset, demonstrating state-of-the-art performance in future semantic segmentation for both short- and mid-term forecasting. Project page and code at https://futurist-cvpr2025.github.io/ .