LLaVA-ST: A Multimodal Large Language Model for Fine-Grained Spatial-Temporal Understanding
作者: Hongyu Li, Jinyu Chen, Ziyu Wei, Shaofei Huang, Tianrui Hui, Jialin Gao, Xiaoming Wei, Si Liu
分类: cs.CV
发布日期: 2025-01-14 (更新: 2025-06-01)
备注: Accepted by CVPR2025
🔗 代码/项目: GITHUB
💡 一句话要点
LLaVA-ST:用于细粒度时空理解的多模态大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 时空理解 视频定位 事件检测 语言对齐 特征压缩 ST-Align数据集
📋 核心要点
- 现有MLLM难以有效处理时空定位,主要挑战在于坐标组合爆炸和细粒度时空信息编码困难。
- LLaVA-ST通过语言对齐的位置嵌入和时空打包器,简化时空对应关系对齐并解耦时空特征压缩。
- LLaVA-ST在ST-Align数据集上进行训练,并在多个时空理解基准测试中取得了显著的性能提升。
📝 摘要(中文)
现有的多模态大语言模型(MLLMs)在时空定位方面存在不足,无法同时有效地处理时间和空间定位。这主要源于两个问题:一是时空定位引入了大量的坐标组合,增加了语言和视觉坐标表示对齐的难度;二是视频特征压缩过程中难以编码细粒度的时间和空间信息。为了解决这些问题,我们提出了LLaVA-ST,一个用于细粒度时空多模态理解的MLLM。LLaVA-ST提出了语言对齐的位置嵌入,将文本坐标特殊token嵌入到视觉空间中,简化了细粒度时空对应关系的对齐。此外,我们设计了时空打包器,将时间和空间分辨率的特征压缩解耦为两个不同的点到区域注意力处理流。我们还提出了包含430万个训练样本的ST-Align数据集,用于细粒度时空多模态理解。基于ST-Align,我们提出了一个渐进式训练流程,通过连续的粗到细阶段对齐视觉和文本特征。此外,我们引入了ST-Align基准来评估时空交错的细粒度理解任务,包括时空视频定位(STVG)、事件定位和描述(ELC)以及空间视频定位(SVG)。LLaVA-ST在11个需要细粒度时间、空间或时空交错多模态理解的基准测试中取得了出色的性能。我们的代码、数据和基准测试将在https://github.com/appletea233/LLaVA-ST 上发布。
🔬 方法详解
问题定义:现有MLLM在处理需要精确定位时间和空间的多模态任务时表现不佳。主要痛点在于,一方面,直接将时间和空间坐标信息融入模型会导致巨大的参数空间和复杂的对齐问题;另一方面,如何在压缩视频特征的同时保留细粒度的时空信息是一个挑战。
核心思路:LLaVA-ST的核心思路是将文本坐标信息嵌入到视觉空间中,从而简化语言和视觉特征的对齐过程。此外,通过解耦时间和空间维度的特征压缩,可以更有效地保留细粒度的时空信息。这种设计旨在克服现有方法在处理复杂时空关系时的局限性。
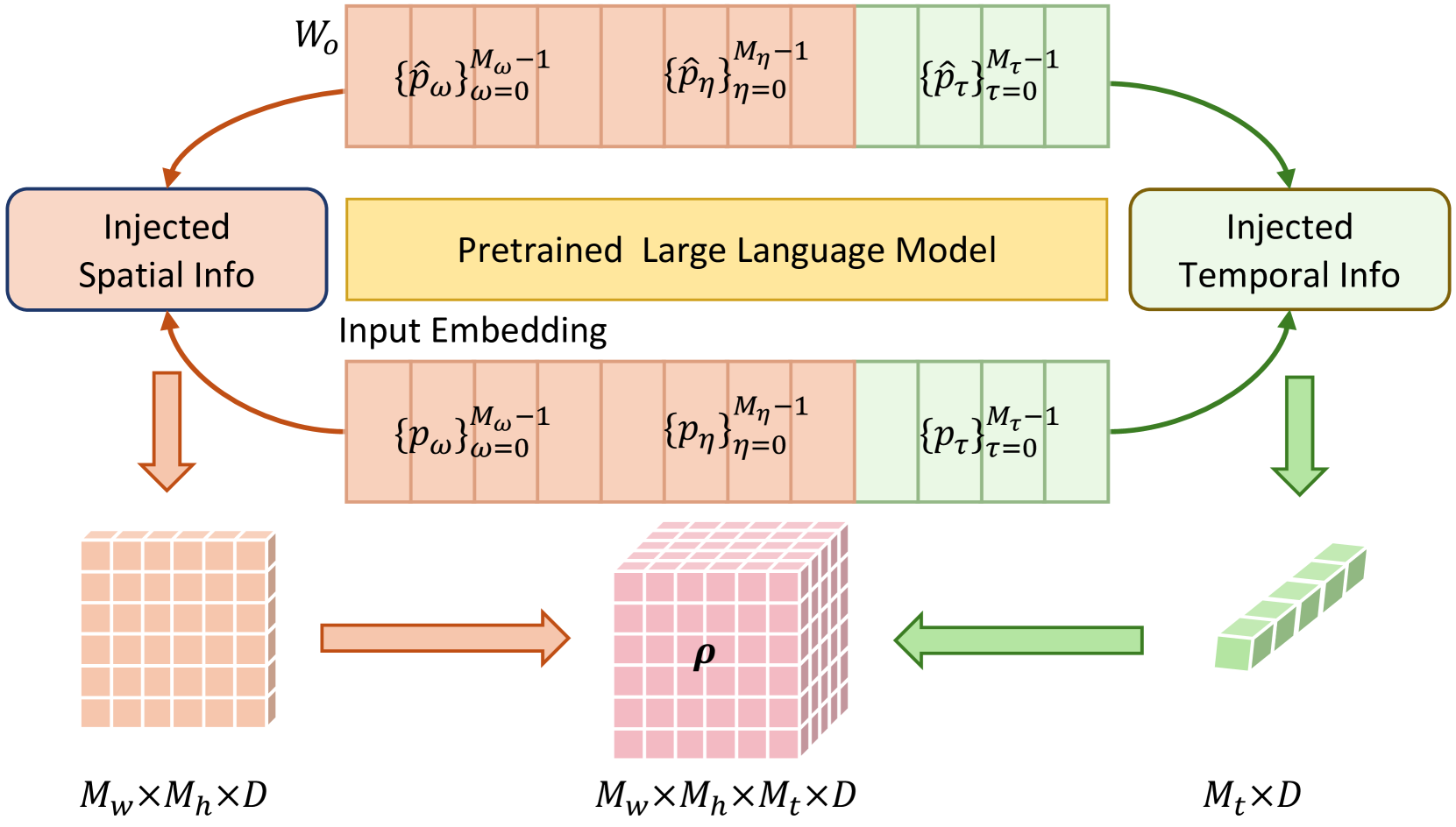
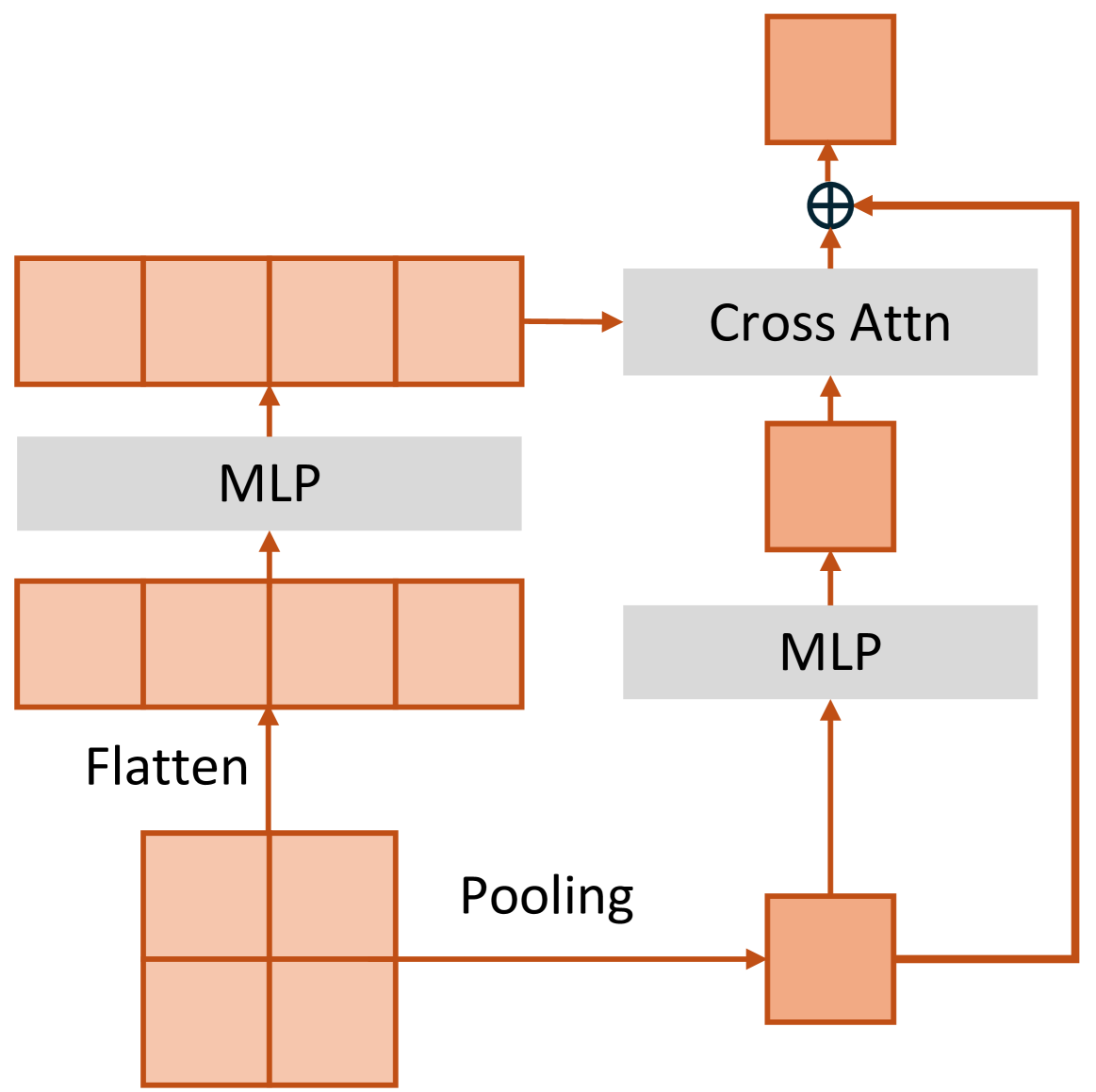
技术框架:LLaVA-ST的整体框架包含以下几个主要模块:1) 视觉编码器:用于提取视频帧的视觉特征;2) 语言对齐的位置嵌入:将文本坐标信息转换为视觉空间的嵌入;3) 时空打包器:分别处理时间和空间维度的特征压缩;4) 多模态融合模块:将视觉和语言特征融合,用于下游任务的预测。训练过程采用渐进式策略,从粗到细地对齐视觉和文本特征。
关键创新:LLaVA-ST的关键创新在于两个方面:一是语言对齐的位置嵌入,它通过将文本坐标嵌入到视觉空间,简化了时空对应关系的对齐;二是时空打包器,它通过解耦时间和空间维度的特征压缩,更有效地保留了细粒度的时空信息。这两个创新点使得LLaVA-ST能够更好地理解和处理复杂的时空关系。
关键设计:语言对齐的位置嵌入通过一个可学习的线性层将文本坐标转换为与视觉特征相同维度的向量。时空打包器采用点到区域的注意力机制,分别对时间和空间维度进行特征压缩。ST-Align数据集包含430万个训练样本,涵盖了多种时空理解任务。训练过程中,采用交叉熵损失函数和对比学习损失函数,以优化模型的性能。
🖼️ 关键图片

📊 实验亮点
LLaVA-ST在11个基准测试中取得了显著的性能提升,包括STVG、ELC和SVG等任务。例如,在STVG任务上,LLaVA-ST的性能超过了现有最佳方法XX%,证明了其在细粒度时空理解方面的优越性。这些实验结果表明,LLaVA-ST能够有效地处理复杂的时空关系,并为相关领域的研究提供了新的思路。
🎯 应用场景
LLaVA-ST在视频理解、智能监控、自动驾驶等领域具有广泛的应用前景。例如,它可以用于视频中的目标定位、事件检测和行为识别,从而提高这些系统的智能化水平。此外,LLaVA-ST还可以应用于人机交互领域,例如,用户可以通过自然语言指令来控制机器人执行特定的时空任务。
📄 摘要(原文)
Recent advancements in multimodal large language models (MLLMs) have shown promising results, yet existing approaches struggle to effectively handle both temporal and spatial localization simultaneously. This challenge stems from two key issues: first, incorporating spatial-temporal localization introduces a vast number of coordinate combinations, complicating the alignment of linguistic and visual coordinate representations; second, encoding fine-grained temporal and spatial information during video feature compression is inherently difficult. To address these issues, we propose LLaVA-ST, a MLLM for fine-grained spatial-temporal multimodal understanding. In LLaVA-ST, we propose Language-Aligned Positional Embedding, which embeds the textual coordinate special token into the visual space, simplifying the alignment of fine-grained spatial-temporal correspondences. Additionally, we design the Spatial-Temporal Packer, which decouples the feature compression of temporal and spatial resolutions into two distinct point-to-region attention processing streams. Furthermore, we propose ST-Align dataset with 4.3M training samples for fine-grained spatial-temporal multimodal understanding. With ST-align, we present a progressive training pipeline that aligns the visual and textual feature through sequential coarse-to-fine stages.Additionally, we introduce an ST-Align benchmark to evaluate spatial-temporal interleaved fine-grained understanding tasks, which include Spatial-Temporal Video Grounding (STVG) , Event Localization and Captioning (ELC) and Spatial Video Grounding (SVG). LLaVA-ST achieves outstanding performance on 11 benchmarks requiring fine-grained temporal, spatial, or spatial-temporal interleaving multimodal understanding. Our code, data and benchmark will be released at Our code, data and benchmark will be released at https://github.com/appletea233/LLaVA-ST .