A Critical Synthesis of Uncertainty Quantification and Foundation Models in Monocular Depth Estimation
作者: Steven Landgraf, Rongjun Qin, Markus Ulrich
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-01-14
💡 一句话要点
融合不确定性量化与深度基础模型,提升单目深度估计的可靠性
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 单目深度估计 不确定性量化 深度基础模型 高斯负对数似然 DepthAnythingV2
📋 核心要点
- 现有单目深度估计模型,特别是基于基础模型的方案,在度量深度估计中存在误差,限制了其在现实场景中的可靠应用。
- 论文核心思想是将不确定性量化方法与先进的DepthAnythingV2基础模型相结合,旨在提供更可靠的深度估计结果和不确定性评估。
- 实验表明,使用高斯负对数似然损失(GNLL)进行微调,能够在保持预测性能的同时,提供可靠的不确定性估计,且计算效率高。
📝 摘要(中文)
尽管最近的基础模型在单目深度估计方面取得了显著突破,但在现实世界中安全可靠的部署仍然难以实现。度量深度估计(涉及预测绝对距离)提出了特殊的挑战,因为即使是最先进的基础模型也容易出现严重错误。由于量化不确定性已成为解决这些限制并实现可信部署的有希望的尝试,我们将五种不同的不确定性量化方法与当前最先进的DepthAnythingV2基础模型融合。为了涵盖广泛的度量深度领域,我们在四个不同的数据集上评估了它们的性能。我们的研究结果表明,使用高斯负对数似然损失(GNLL)进行微调是一种特别有前途的方法,它提供了可靠的不确定性估计,同时保持了与基线相当的预测性能和计算效率,包括训练和推理时间。通过在单目深度估计的背景下融合不确定性量化和基础模型,本文为未来的研究奠定了关键基础,旨在不仅提高模型性能,还提高其可解释性。将不确定性量化和基础模型的这种关键综合扩展到其他关键任务(如语义分割和姿态估计)为更安全、更可靠的机器视觉系统提供了令人兴奋的机会。
🔬 方法详解
问题定义:论文旨在解决单目深度估计中,现有深度基础模型在预测绝对距离时容易出错,导致实际应用中可靠性不足的问题。现有方法缺乏有效的不确定性量化手段,难以评估预测结果的可信度。
核心思路:论文的核心思路是将不确定性量化方法融入到深度基础模型中,使得模型不仅能预测深度值,还能评估预测结果的不确定性。通过量化不确定性,可以识别出模型预测不可靠的区域,从而提高整体系统的安全性。
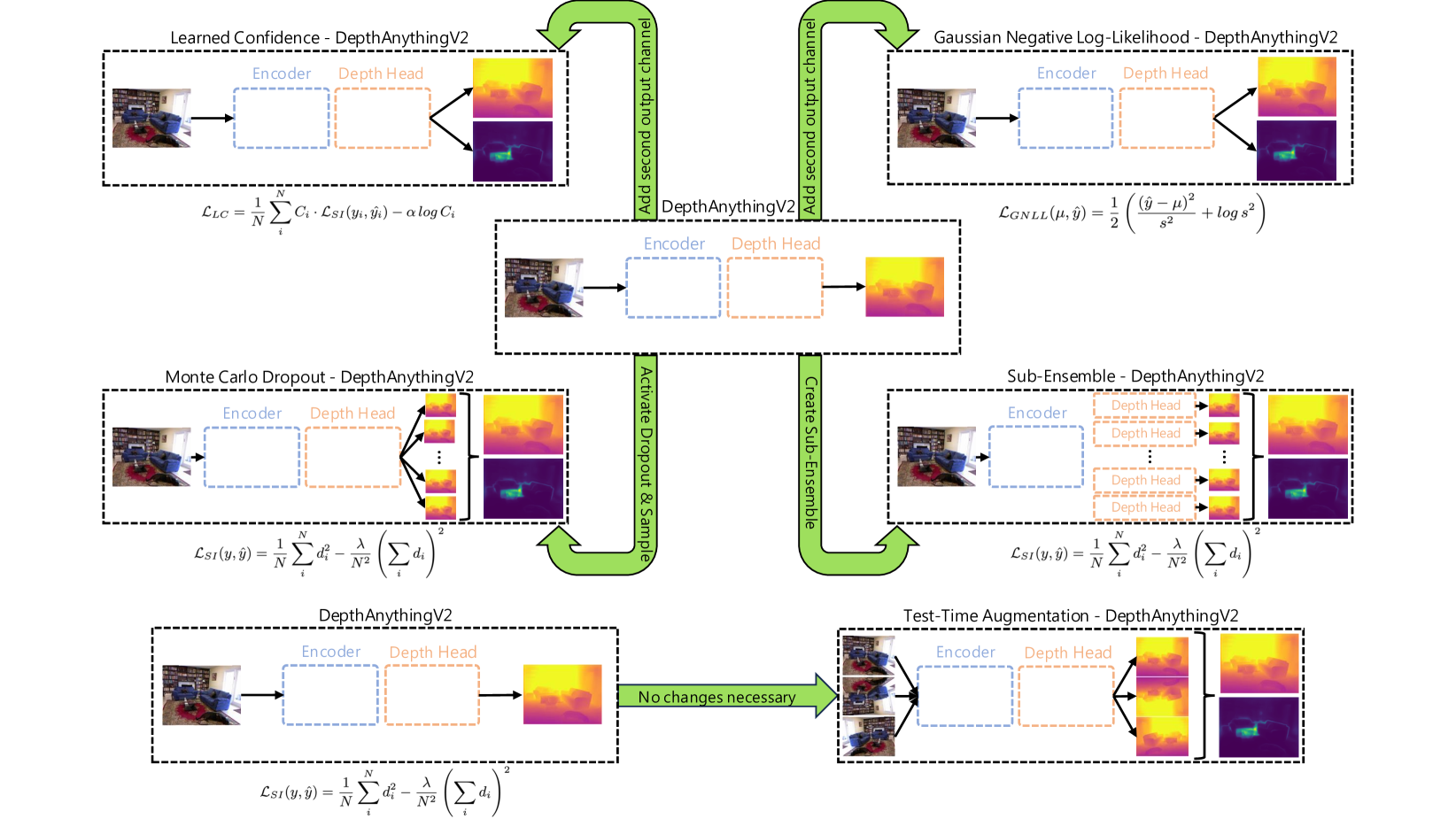
技术框架:整体框架是将五种不同的不确定性量化方法与DepthAnythingV2基础模型相结合。具体流程包括:首先,使用DepthAnythingV2进行初始深度预测;然后,利用不同的不确定性量化方法对预测结果进行评估,生成不确定性图;最后,通过特定的损失函数(如GNLL)对模型进行微调,使得模型能够同时预测深度和不确定性。
关键创新:最重要的创新点在于将不确定性量化与深度基础模型相结合,使得模型能够提供更全面的深度估计信息,包括深度值和不确定性。这与传统方法只关注深度值的预测不同,为后续应用提供了更多信息。
关键设计:论文的关键设计包括:1) 选择DepthAnythingV2作为基础模型,因为它代表了当前最先进的单目深度估计水平;2) 选择了五种不同的不确定性量化方法,以覆盖不同的不确定性来源;3) 使用高斯负对数似然损失(GNLL)作为微调的损失函数,因为它能够有效地学习深度和不确定性之间的关系。具体而言,GNLL损失函数鼓励模型预测的深度值接近真实值,同时最小化不确定性,但对于预测错误的区域,允许模型预测更大的不确定性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用高斯负对数似然损失(GNLL)进行微调,能够在四个不同的数据集上提供可靠的不确定性估计,同时保持与基线DepthAnythingV2相当的预测性能和计算效率。这意味着在不牺牲性能的前提下,显著提升了模型的可靠性和可解释性。具体的不确定性量化指标提升数据未知。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、增强现实等领域。通过提供带有不确定性评估的深度信息,可以提高这些系统在复杂环境中的鲁棒性和安全性。例如,在自动驾驶中,可以利用不确定性信息来判断前方障碍物距离估计的可靠性,从而做出更安全的决策。未来,该方法可以扩展到其他视觉任务,如语义分割和姿态估计,构建更安全可靠的机器视觉系统。
📄 摘要(原文)
While recent foundation models have enabled significant breakthroughs in monocular depth estimation, a clear path towards safe and reliable deployment in the real-world remains elusive. Metric depth estimation, which involves predicting absolute distances, poses particular challenges, as even the most advanced foundation models remain prone to critical errors. Since quantifying the uncertainty has emerged as a promising endeavor to address these limitations and enable trustworthy deployment, we fuse five different uncertainty quantification methods with the current state-of-the-art DepthAnythingV2 foundation model. To cover a wide range of metric depth domains, we evaluate their performance on four diverse datasets. Our findings identify fine-tuning with the Gaussian Negative Log-Likelihood Loss (GNLL) as a particularly promising approach, offering reliable uncertainty estimates while maintaining predictive performance and computational efficiency on par with the baseline, encompassing both training and inference time. By fusing uncertainty quantification and foundation models within the context of monocular depth estimation, this paper lays a critical foundation for future research aimed at improving not only model performance but also its explainability. Extending this critical synthesis of uncertainty quantification and foundation models into other crucial tasks, such as semantic segmentation and pose estimation, presents exciting opportunities for safer and more reliable machine vision systems.