Facial Dynamics in Video: Instruction Tuning for Improved Facial Expression Perception and Contextual Awareness
作者: Jiaxing Zhao, Boyuan Sun, Xiang Chen, Xihan Wei
分类: cs.CV, cs.AI
发布日期: 2025-01-14
💡 一句话要点
提出FaceTrack-MM与FEC-Bench,提升视频MLLM在动态面部表情感知和上下文理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频理解 多模态学习 面部表情识别 指令微调 人脸跟踪
📋 核心要点
- 现有视频MLLM在面部表情描述方面面临数据集匮乏和视觉token容量有限的挑战。
- 提出FaceTrack-MM模型,利用少量token编码人脸,提升复杂场景下的面部跟踪和表情识别能力。
- 构建FEC-Bench基准,并设计结合事件提取、关系分类和LCS的评估指标,全面评估模型性能。
📝 摘要(中文)
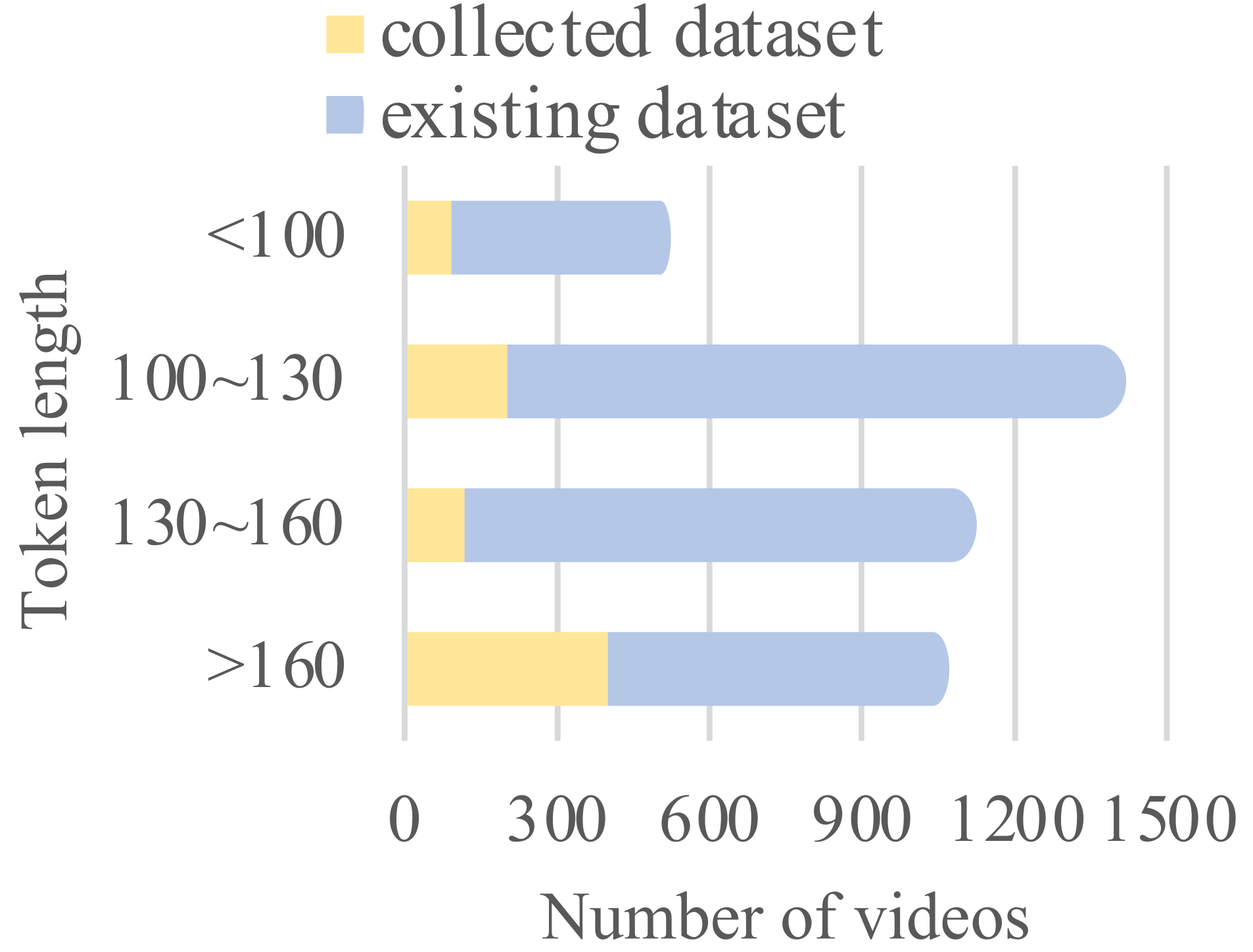
面部表情描述在多个领域有着广泛的应用。近年来,视频多模态大语言模型(MLLM)在通用视频理解任务中展现出潜力。然而,在视频中描述面部表情对这些模型提出了两个主要挑战:(1)缺乏足够的数据集和基准;(2)视频MLLM的视觉token容量有限。为了解决这些问题,本文引入了一个新的指令跟随数据集,专门用于动态面部表情描述。该数据集包含5,033个高质量的手动标注视频片段,超过70万个token,旨在提高视频MLLM识别细微面部表情的能力。此外,我们提出了FaceTrack-MM,它利用有限数量的token来编码主要人物的面部。该模型在跟踪面部和关注主要人物的面部表情方面表现出优异的性能,即使在复杂的多人场景中也是如此。此外,我们引入了一种新的评估指标,结合事件提取、关系分类和最长公共子序列(LCS)算法,以评估生成文本的内容一致性和时间序列一致性。此外,我们提出了FEC-Bench,这是一个旨在评估现有视频MLLM在该特定任务中的性能的基准。所有数据和源代码都将公开。
🔬 方法详解
问题定义:现有视频多模态大语言模型(MLLM)在理解视频中的面部表情时,面临两个主要问题。一是缺乏专门用于动态面部表情描述的大规模数据集和基准,导致模型训练不足。二是视频MLLM的视觉token容量有限,难以捕捉细微的面部表情变化,尤其是在多人场景下,模型难以聚焦关键人物的面部。
核心思路:本文的核心思路是通过构建高质量的动态面部表情描述数据集,并设计高效的面部跟踪模块,来提升视频MLLM在面部表情理解方面的能力。具体来说,通过指令微调的方式,让模型学习如何根据视频内容生成准确、连贯的面部表情描述。同时,利用有限的token资源,专注于主要人物的面部特征,从而提高模型的效率和准确性。
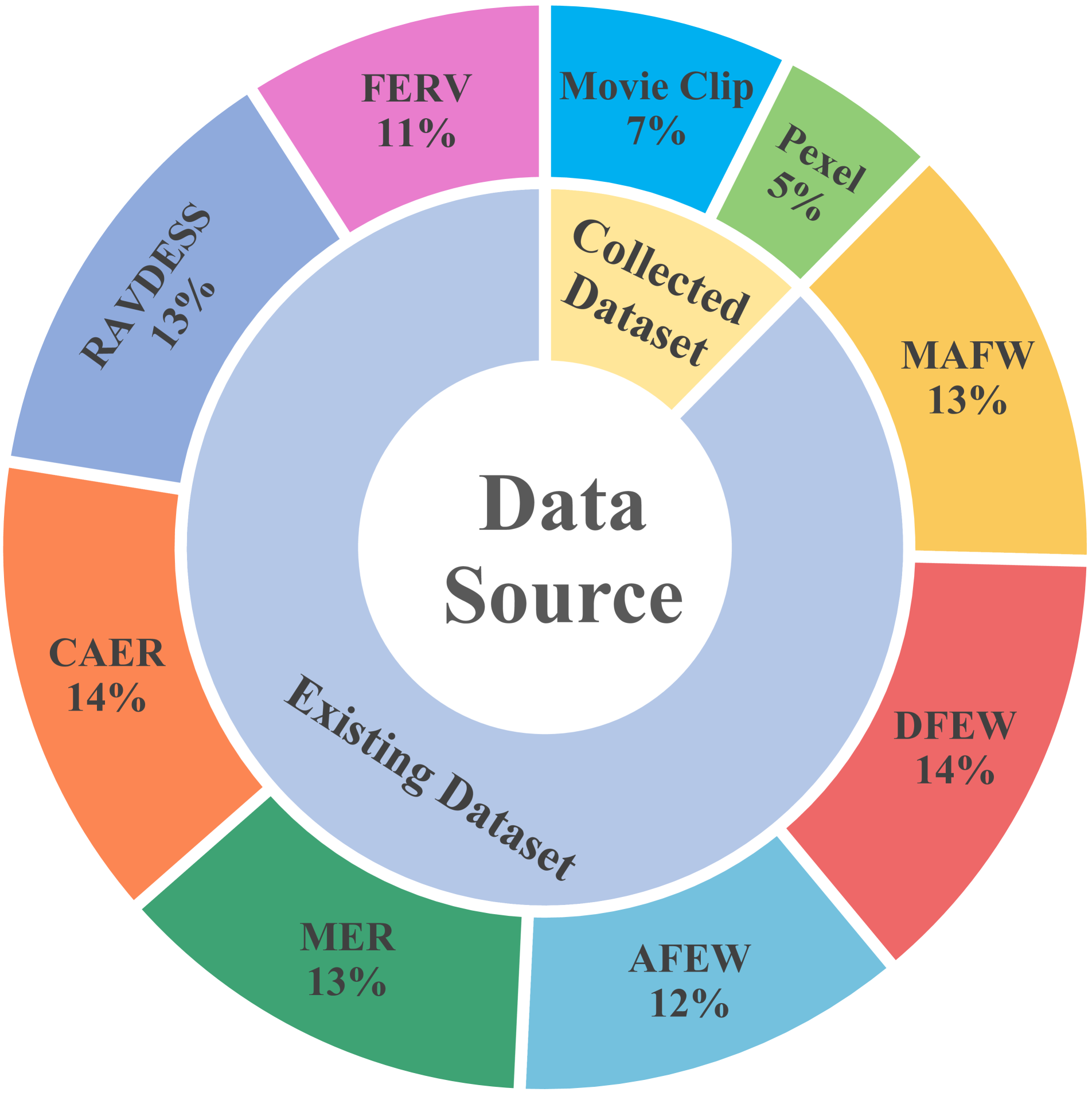
技术框架:整体框架包含数据构建和模型训练两个主要部分。首先,构建包含5033个视频片段的动态面部表情描述数据集,并进行人工标注。然后,提出FaceTrack-MM模型,该模型包含一个面部跟踪模块,用于提取视频中主要人物的面部特征。最后,使用构建的数据集对FaceTrack-MM进行指令微调,使其能够生成高质量的面部表情描述。
关键创新:本文的关键创新在于以下几个方面:(1)构建了一个高质量的动态面部表情描述数据集,填补了该领域的空白。(2)提出了FaceTrack-MM模型,该模型能够有效地跟踪面部,并利用有限的token资源专注于主要人物的面部表情。(3)设计了一种新的评估指标,结合事件提取、关系分类和最长公共子序列(LCS)算法,能够更全面地评估模型生成文本的内容一致性和时间序列一致性。与现有方法相比,FaceTrack-MM能够更准确地捕捉细微的面部表情变化,并生成更连贯的描述。
关键设计:FaceTrack-MM的关键设计在于其面部跟踪模块,该模块利用少量token来编码主要人物的面部。具体来说,该模块首先检测视频中的人脸,然后选择最主要的人物(例如,根据人物在画面中的大小或位置)。接下来,该模块提取该人物的面部特征,并将这些特征编码为少量token。这些token随后被输入到视频MLLM中,用于生成面部表情描述。此外,在指令微调过程中,使用了交叉熵损失函数来优化模型,使其能够生成更准确的描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FaceTrack-MM在面部表情描述任务上取得了显著的性能提升。通过与现有视频MLLM进行对比,FaceTrack-MM在FEC-Bench基准上取得了最佳性能,尤其是在内容一致性和时间序列一致性方面表现突出。具体性能数据未知,但论文强调了FaceTrack-MM在复杂场景下的优越性。
🎯 应用场景
该研究成果可应用于人机交互、情感分析、心理健康评估、以及视频监控等领域。例如,在人机交互中,可以使机器更好地理解人类的情感状态,从而提供更自然、更个性化的服务。在心理健康评估中,可以通过分析患者的面部表情来辅助诊断和治疗。在视频监控中,可以自动检测异常情绪,提高安全预警能力。
📄 摘要(原文)
Facial expression captioning has found widespread application across various domains. Recently, the emergence of video Multimodal Large Language Models (MLLMs) has shown promise in general video understanding tasks. However, describing facial expressions within videos poses two major challenges for these models: (1) the lack of adequate datasets and benchmarks, and (2) the limited visual token capacity of video MLLMs. To address these issues, this paper introduces a new instruction-following dataset tailored for dynamic facial expression caption. The dataset comprises 5,033 high-quality video clips annotated manually, containing over 700,000 tokens. Its purpose is to improve the capability of video MLLMs to discern subtle facial nuances. Furthermore, we propose FaceTrack-MM, which leverages a limited number of tokens to encode the main character's face. This model demonstrates superior performance in tracking faces and focusing on the facial expressions of the main characters, even in intricate multi-person scenarios. Additionally, we introduce a novel evaluation metric combining event extraction, relation classification, and the longest common subsequence (LCS) algorithm to assess the content consistency and temporal sequence consistency of generated text. Moreover, we present FEC-Bench, a benchmark designed to assess the performance of existing video MLLMs in this specific task. All data and source code will be made publicly available.