Zero-shot Video Moment Retrieval via Off-the-shelf Multimodal Large Language Models
作者: Yifang Xu, Yunzhuo Sun, Benxiang Zhai, Ming Li, Wenxin Liang, Yang Li, Sidan Du
分类: cs.MM, cs.CV
发布日期: 2025-01-14
备注: Accepted by AAAI 2025
💡 一句话要点
提出Moment-GPT,利用冻结的多模态大语言模型实现零样本视频片段检索。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频片段检索 多模态大语言模型 零样本学习 语言偏差纠正 视频理解
📋 核心要点
- 现有VMR方法依赖大量标注数据和模型微调,零样本方法忽略了查询中的语言偏差,导致检索精度下降。
- Moment-GPT通过LLaMA-3纠正查询偏差,结合MiniGPT-v2自适应生成候选片段,并利用VideoChatGPT进行片段评分。
- 实验表明,Moment-GPT在QVHighlights、ActivityNet-Captions和Charades-STA等数据集上显著优于现有MLLM和零样本方法。
📝 摘要(中文)
视频片段检索(VMR)的任务是预测视频中与给定语言查询在语义上匹配的时间跨度。现有的基于多模态大语言模型(MLLM)的VMR方法过度依赖昂贵的高质量数据集和耗时的微调。虽然最近的一些研究引入了零样本设置以避免微调,但它们忽略了查询中固有的语言偏差,导致错误的定位。为了解决上述挑战,本文提出了一种无需微调的零样本VMR流程Moment-GPT,它利用了冻结的MLLM。具体来说,我们首先使用LLaMA-3来纠正和改写查询,以减轻语言偏差。随后,我们设计了一个结合MiniGPT-v2的跨度生成器,以自适应地生成候选跨度。最后,为了利用MLLM的视频理解能力,我们应用VideoChatGPT和跨度评分器来选择最合适的跨度。我们提出的方法在多个公共数据集上,包括QVHighlights、ActivityNet-Captions和Charades-STA,显著优于最先进的基于MLLM的和零样本模型。
🔬 方法详解
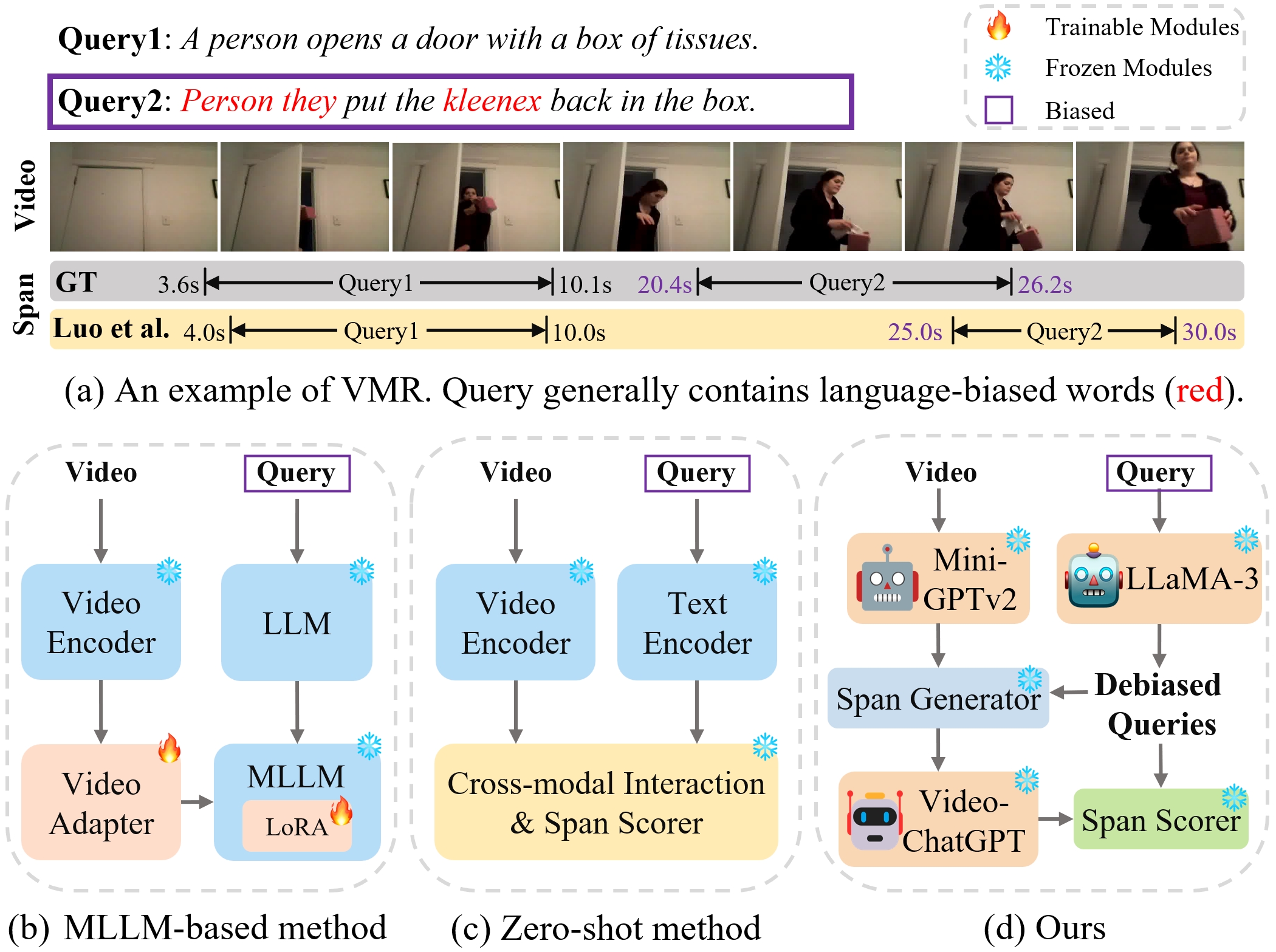
问题定义:视频片段检索旨在根据给定的文本查询,从视频中定位语义相关的片段。现有基于多模态大语言模型的方法通常需要大量的标注数据进行微调,成本高昂。而零样本方法虽然避免了微调,但忽略了查询语句中可能存在的语言偏差,这会导致检索结果出现偏差,影响定位的准确性。
核心思路:Moment-GPT的核心思路是利用预训练的、冻结的多模态大语言模型,通过一系列巧妙的设计,在不进行微调的情况下,实现高效且准确的零样本视频片段检索。关键在于解决查询中的语言偏差问题,并充分利用MLLM的视频理解能力。
技术框架:Moment-GPT的整体框架包含三个主要阶段:1) 查询纠正与重述:使用LLaMA-3对原始查询进行纠正和重述,以消除或减轻语言偏差。2) 候选片段生成:设计一个跨度生成器,结合MiniGPT-v2,自适应地生成一系列候选的视频片段。3) 片段选择与评分:利用VideoChatGPT对候选片段进行评分,选择与查询最相关的片段作为最终的检索结果。
关键创新:Moment-GPT的关键创新在于其完全零样本的特性,以及针对查询语言偏差的处理方式。它避免了昂贵的微调过程,同时通过LLaMA-3的查询纠正,显著提高了检索的准确性。此外,自适应的片段生成和基于VideoChatGPT的片段评分机制,也充分利用了MLLM的视频理解能力。
关键设计:在查询纠正阶段,LLaMA-3被用于识别并修正查询中的语法错误、歧义或不准确之处。跨度生成器利用MiniGPT-v2,根据视频内容和修正后的查询,生成一系列具有不同时间跨度的候选片段。VideoChatGPT则被用于评估每个候选片段与查询的相关性,并输出一个评分,最终选择评分最高的片段。
🖼️ 关键图片


📊 实验亮点
Moment-GPT在QVHighlights、ActivityNet-Captions和Charades-STA等数据集上取得了显著的性能提升,超越了现有的基于MLLM和零样本的VMR方法。具体性能数据在论文中给出,表明该方法在零样本场景下具有很强的竞争力。
🎯 应用场景
该研究成果可应用于视频内容理解、智能视频搜索、视频摘要生成等领域。例如,用户可以通过自然语言描述快速定位视频中的关键时刻,提升视频检索效率。未来,该技术有望在教育、娱乐、安防等行业得到广泛应用,实现更智能化的视频分析和理解。
📄 摘要(原文)
The target of video moment retrieval (VMR) is predicting temporal spans within a video that semantically match a given linguistic query. Existing VMR methods based on multimodal large language models (MLLMs) overly rely on expensive high-quality datasets and time-consuming fine-tuning. Although some recent studies introduce a zero-shot setting to avoid fine-tuning, they overlook inherent language bias in the query, leading to erroneous localization. To tackle the aforementioned challenges, this paper proposes Moment-GPT, a tuning-free pipeline for zero-shot VMR utilizing frozen MLLMs. Specifically, we first employ LLaMA-3 to correct and rephrase the query to mitigate language bias. Subsequently, we design a span generator combined with MiniGPT-v2 to produce candidate spans adaptively. Finally, to leverage the video comprehension capabilities of MLLMs, we apply VideoChatGPT and span scorer to select the most appropriate spans. Our proposed method substantially outperforms the state-ofthe-art MLLM-based and zero-shot models on several public datasets, including QVHighlights, ActivityNet-Captions, and Charades-STA.