Parameter-Inverted Image Pyramid Networks for Visual Perception and Multimodal Understanding
作者: Zhaokai Wang, Xizhou Zhu, Xue Yang, Gen Luo, Hao Li, Changyao Tian, Wenhan Dou, Junqi Ge, Lewei Lu, Yu Qiao, Jifeng Dai
分类: cs.CV, cs.CL
发布日期: 2025-01-14
期刊: TPAMI 2025
DOI: 10.1109/TPAMI.2025.3593283
🔗 代码/项目: GITHUB
💡 一句话要点
提出参数倒置图像金字塔网络(PIIP),以低计算成本提升视觉感知和多模态理解性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像金字塔 多尺度特征 视觉感知 多模态理解 参数倒置 跨分支特征交互 目标检测 语义分割
📋 核心要点
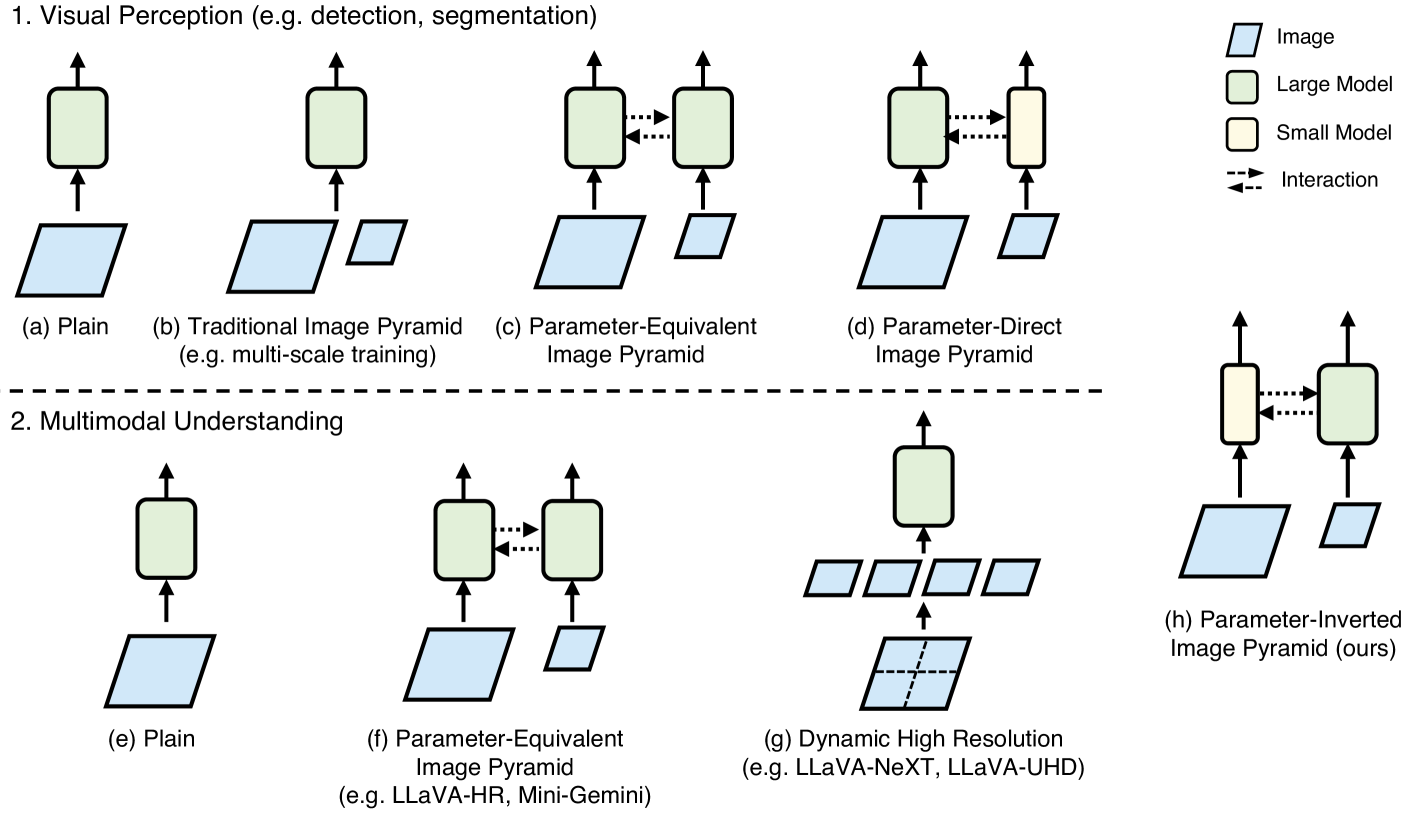
- 现有图像金字塔方法计算成本高昂,因为它们对所有分辨率的图像都使用相同的大规模模型。
- PIIP通过使用参数倒置策略,即高分辨率图像由较小的网络分支处理,来平衡计算成本和性能。
- 实验表明,PIIP在多个视觉和多模态任务上,以更低的计算成本实现了优越的性能,例如在COCO检测上达到60.0 AP。
📝 摘要(中文)
图像金字塔被广泛应用于高性能方法中,以获得多尺度特征,从而实现精确的视觉感知和理解。然而,当前的图像金字塔使用相同的大规模模型来处理多个分辨率的图像,导致显著的计算成本。为了解决这个挑战,我们提出了一种新的网络架构,称为参数倒置图像金字塔网络(PIIP)。具体来说,PIIP使用预训练模型(ViTs或CNNs)作为分支来处理多尺度图像,其中较高分辨率的图像由较小的网络分支处理,以平衡计算成本和性能。为了整合来自不同空间尺度的信息,我们进一步提出了一种新的跨分支特征交互机制。为了验证PIIP,我们将其应用于各种感知模型和一个代表性的多模态大型语言模型LLaVA,并在各种任务(如对象检测、分割、图像分类和多模态理解)上进行了广泛的实验。PIIP以较低的计算成本实现了优于单分支和现有多分辨率方法性能。当应用于大规模视觉基础模型InternViT-6B时,PIIP可以在仅使用原始计算量的40%-60%的情况下,将其在检测和分割方面的性能提高1%-2%,最终在MS COCO上达到60.0 box AP,在ADE20K上达到59.7 mIoU。对于多模态理解,我们的PIIP-LLaVA仅使用2.8M的训练数据,在TextVQA上实现了73.0%的准确率,在MMBench上实现了74.5%的准确率。
🔬 方法详解
问题定义:现有图像金字塔方法在处理多尺度图像时,由于对所有分辨率都采用相同的大规模模型,导致计算成本过高,限制了其在资源受限场景下的应用。如何在保证性能的同时,降低图像金字塔的计算复杂度是一个关键问题。
核心思路:PIIP的核心思路是“参数倒置”,即图像分辨率越高,处理该分辨率图像的网络分支的参数量越小。这样可以在保证高分辨率图像细节信息被充分利用的同时,避免不必要的计算冗余。同时,设计跨分支特征交互机制,融合不同尺度特征,弥补小模型带来的信息损失。
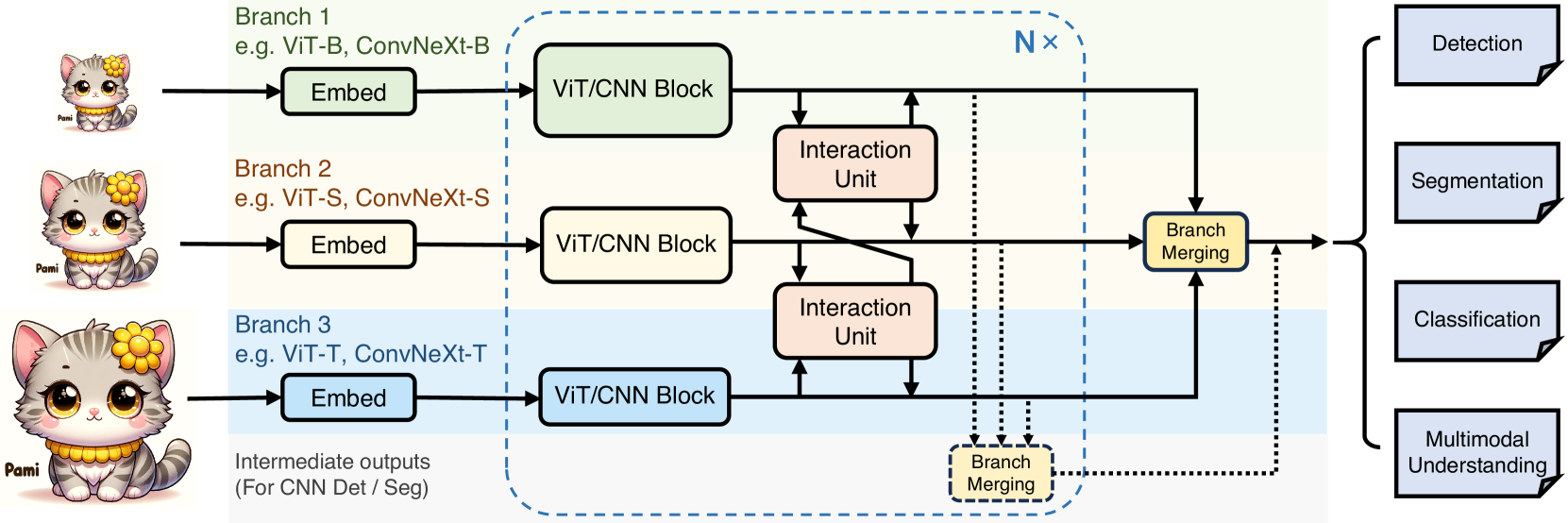
技术框架:PIIP的整体架构是一个多分支网络,每个分支处理不同分辨率的图像。这些分支可以是预训练的ViT或CNN模型。高分辨率图像对应参数量较小的分支,低分辨率图像对应参数量较大的分支。所有分支的输出特征通过跨分支特征交互模块进行融合,最终用于下游任务。
关键创新:PIIP最重要的创新点在于“参数倒置”的思想,它打破了传统图像金字塔中所有分辨率共享相同模型的模式,根据分辨率自适应地调整模型大小,从而在计算成本和性能之间取得了更好的平衡。此外,跨分支特征交互机制也是一个重要的创新,它能够有效地融合不同尺度特征,提升整体性能。
关键设计:PIIP的关键设计包括:1) 如何选择每个分支的模型大小,需要根据具体任务和数据集进行调整;2) 跨分支特征交互模块的具体实现方式,可以使用注意力机制、卷积等方法;3) 损失函数的设计,需要考虑不同分支的贡献,以及跨分支特征交互的效果。
🖼️ 关键图片

📊 实验亮点
PIIP在多个任务上取得了显著的性能提升。例如,在MS COCO目标检测任务上,PIIP-InternViT-6B在仅使用原始计算量的40%-60%的情况下,将性能提升了1%-2%,达到了60.0 box AP。在ADE20K语义分割任务上,PIIP-InternViT-6B达到了59.7 mIoU。在多模态理解任务中,PIIP-LLaVA仅使用2.8M的训练数据,在TextVQA上实现了73.0%的准确率,在MMBench上实现了74.5%的准确率。
🎯 应用场景
PIIP具有广泛的应用前景,可应用于各种需要多尺度特征的视觉任务,如目标检测、图像分割、图像分类等。此外,PIIP还可以应用于多模态理解任务,例如视觉问答、图像描述等。该研究成果有助于推动视觉感知和多模态理解技术的发展,并为实际应用提供更高效的解决方案。
📄 摘要(原文)
Image pyramids are widely adopted in top-performing methods to obtain multi-scale features for precise visual perception and understanding. However, current image pyramids use the same large-scale model to process multiple resolutions of images, leading to significant computational cost. To address this challenge, we propose a novel network architecture, called Parameter-Inverted Image Pyramid Networks (PIIP). Specifically, PIIP uses pretrained models (ViTs or CNNs) as branches to process multi-scale images, where images of higher resolutions are processed by smaller network branches to balance computational cost and performance. To integrate information from different spatial scales, we further propose a novel cross-branch feature interaction mechanism. To validate PIIP, we apply it to various perception models and a representative multimodal large language model called LLaVA, and conduct extensive experiments on various tasks such as object detection, segmentation, image classification and multimodal understanding. PIIP achieves superior performance compared to single-branch and existing multi-resolution approaches with lower computational cost. When applied to InternViT-6B, a large-scale vision foundation model, PIIP can improve its performance by 1%-2% on detection and segmentation with only 40%-60% of the original computation, finally achieving 60.0 box AP on MS COCO and 59.7 mIoU on ADE20K. For multimodal understanding, our PIIP-LLaVA achieves 73.0% accuracy on TextVQA and 74.5% on MMBench with only 2.8M training data. Our code is released at https://github.com/OpenGVLab/PIIP.